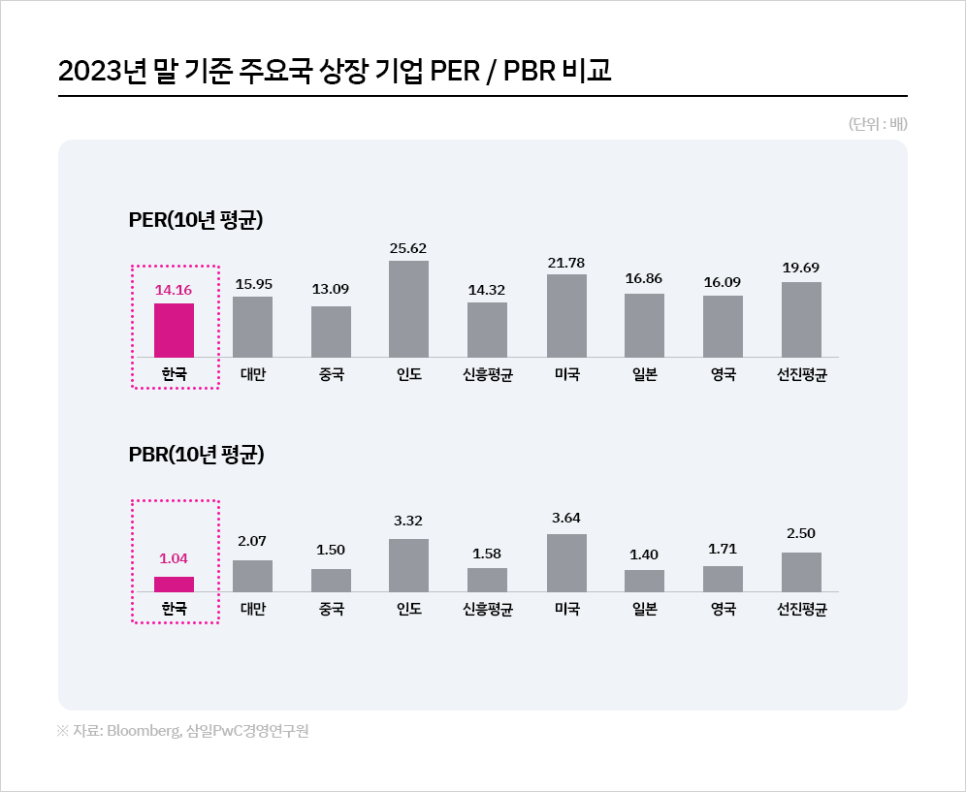
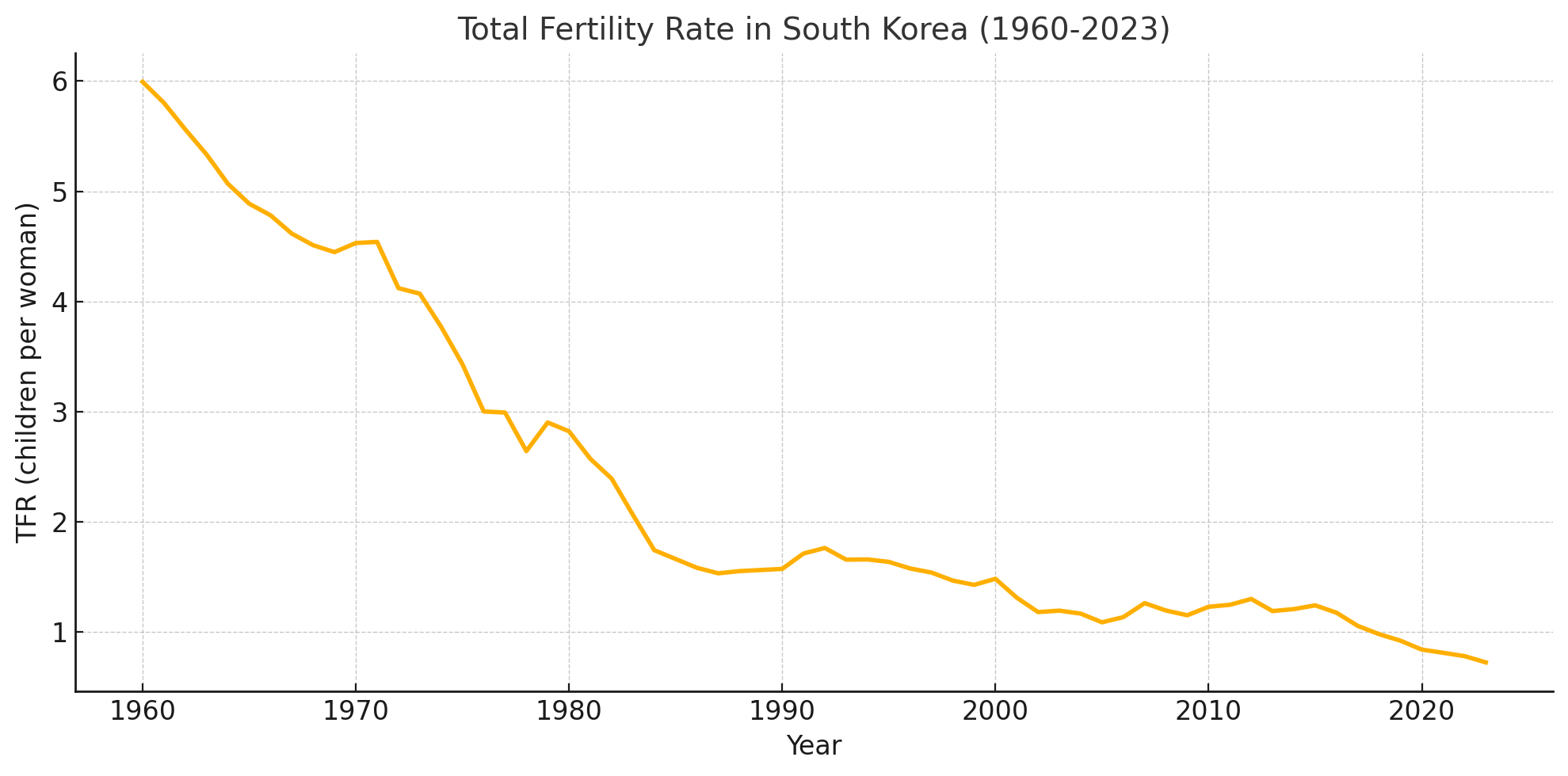
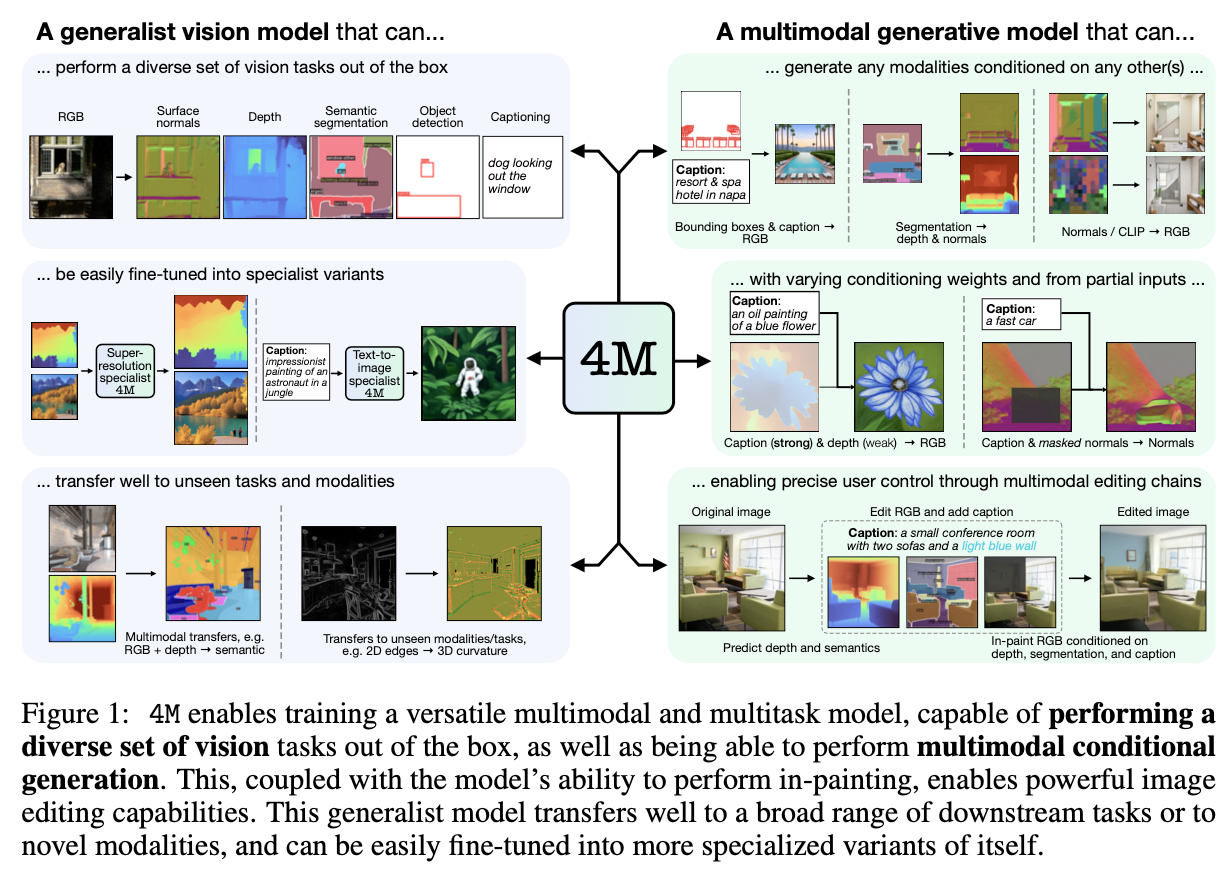
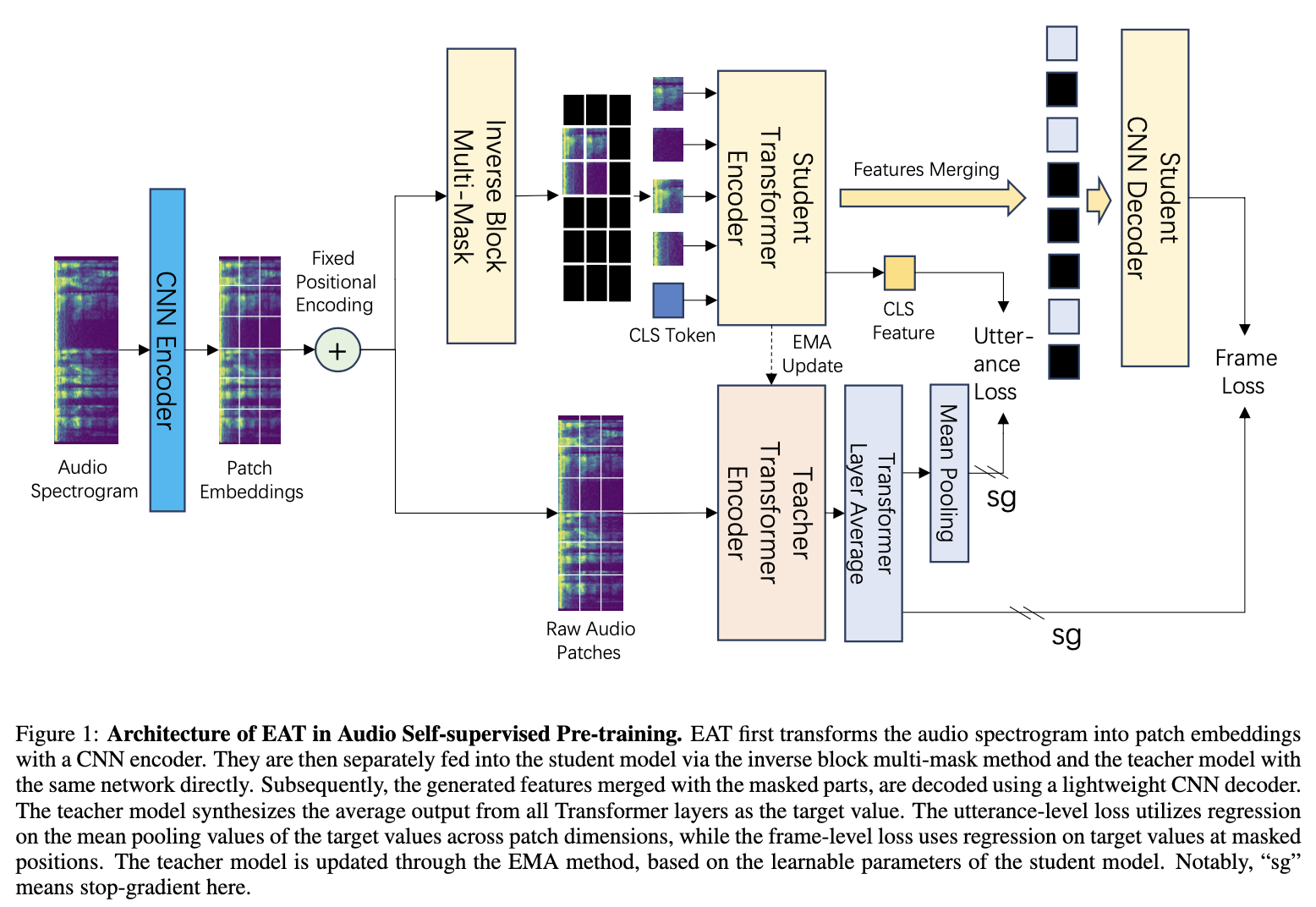
1. 서론 및 배경 (Introduction and Background) 최근 어텐션 기반 신경망이 이미지 분류와 같은 이미지 이해 작업에서 높은 성능을 보여주었습니다 [1]. 특히 비전 트랜스포머(Vision Transformer, ViT)는 이미지 분류 작업에 원시 이미지 패치를 입력으로 직접 적용하여 우수한 결과를 달성했습니다 [2, 3].그러나 기존의 고성능 비전 트랜스포머는 대규모 인프라를 사용하여 수억 개의 이미지로 사전 학습되어야 하므로, 그 채택이 제한적이었습니다 [1, 3, 4]. Dosovitskiy et al.의 연구 [5]에서는 트랜스포머가 "불충분한 양의 데이터로 학습할 때 잘 일반화되지 않는다"고 결론지었으며, 이러한 모델의 학습에는 광범위한 컴퓨팅 자원이 필요했습니다 [3].오..