논문의 목적 및 개요 이 논문은 4M이라는 다중 모달 학습 방식을 제안하며, 이는 비전 분야에서 대규모 언어 모델(LLMs)처럼 다양한 작업을 수행할 수 있는 범용적이고 확장 가능한 모델을 개발하기 위한 한 단계입니다. 현재 비전 모델은 단일 모달리티 및 작업에 고도로 특화된 경우가 많지만, 4M은 단일 통합 트랜스포머 인코더-디코더를 사용하여 텍스트, 이미지, 기하학적 및 의미론적 모달리티, 신경망 특징 맵 등 광범위한 입/출력 모달리티에 걸쳐 마스크 모델링 목표로 훈련합니다.
4M의 핵심 능력 4M으로 훈련된 모델은 여러 가지 핵심 능력을 보여줍니다:
- 다양한 비전 작업을 즉시(out of the box) 수행할 수 있습니다.
- 보이지 않는 다운스트림 작업이나 새로운 입력 모달리티에 미세 조정 시 뛰어난 성능을 보입니다.
- 임의의 모달리티에 조건화될 수 있는 생성 모델로 기능하여 놀라운 유연성으로 다양한 표현적인 다중 모달 편집 기능을 가능하게 합니다.
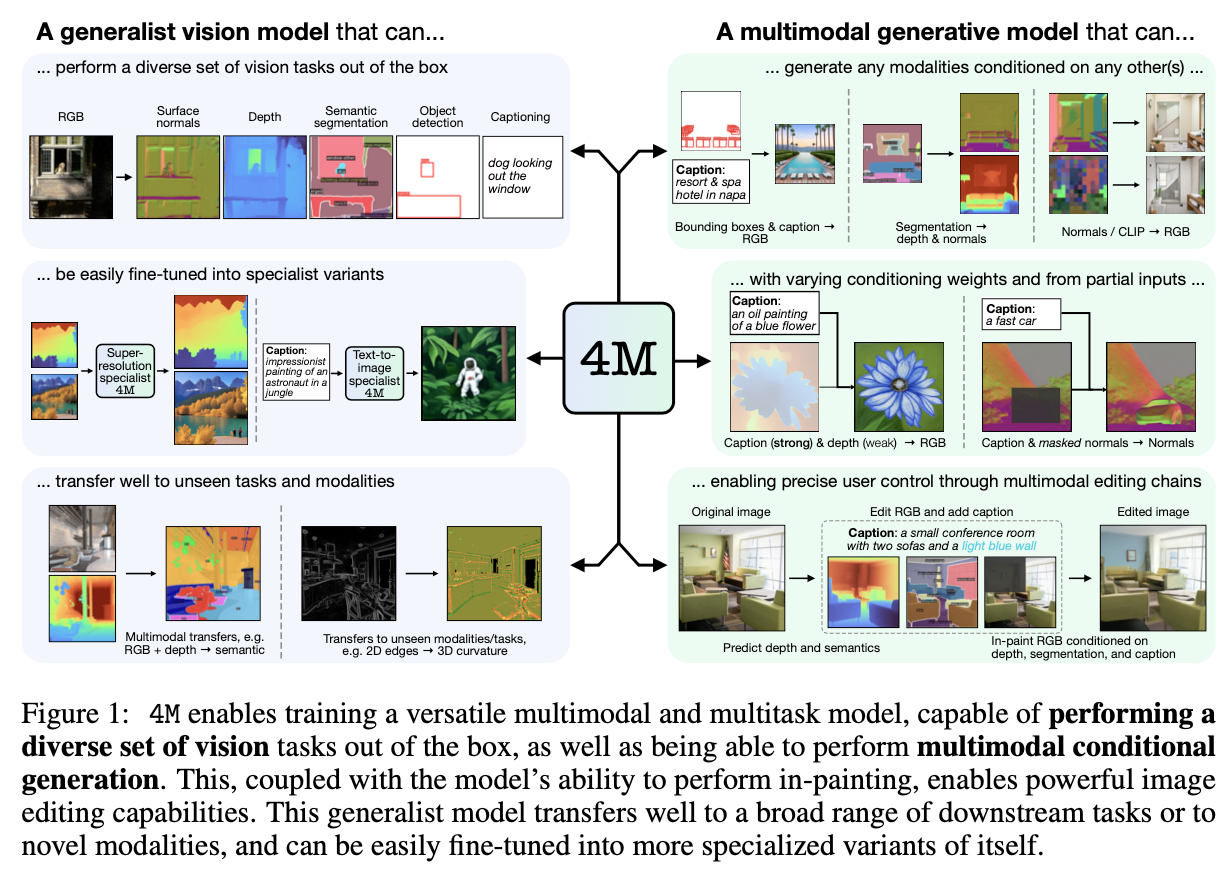
방법론
- 확장성 고려: 기초 모델의 바람직한 속성을 만들기 위해 4M은 데이터, 아키텍처, 훈련 목표의 세 가지 핵심 측면에서 확장성을 고려하여 설계되었습니다.
- 토큰화 모달리티: 4M은 텍스트, 바운딩 박스, 이미지 또는 신경망 특징과 같은 서로 다른 형식의 모달리티를 단일 트랜스포머에서 훈련하기 위해 모든 모달리티를 이산 토큰의 시퀀스 또는 세트로 매핑하여 표현 공간을 통일합니다. 이를 위해 모달리티별 토크나이저를 사용하며, 이는 작업별 인코더 및 헤드의 필요성을 제거하여 호환성, 확장성 및 공유를 향상시킵니다. dense 모달리티(RGB, depth, normals, semantic segmentation maps, CLIP feature maps)는 학습된 VQ-VAE를 사용하여 토큰화되고, sequence 모달리티(캡션, 바운딩 박스)는 WordPiece를 사용하여 텍스트로 처리됩니다. 바운딩 박스의 경우 Pix2Seq 방식을 따라 객체 탐지 작업을 시퀀스 예측 문제로 변환합니다.
- 단일 호환 네트워크 훈련: 모든 모달리티를 통합된 표현 공간으로 토큰화함으로써, 단일 트랜스포머 인코더-디코더를 훈련하여 (병렬 또는 직렬 자동 회귀) 토큰 예측을 통해 다른 모달리티 간의 매핑을 수행할 수 있습니다. 인코더는 모달리티별 학습 가능한 입력 임베딩 및 위치 임베딩을 사용하며, 디코더는 모든 인코더 토큰에 자유롭게 어텐션할 수 있고 모달리티별 어텐션 마스크를 사용하여 일관된 출력을 생성합니다. 디코더는 dense 모달리티에 대해서는 마스크 토큰을 입력으로 받아 마스크된 내용을 예측하고, sequence 모달리티에 대해서는 다음 토큰을 예측하도록 훈련됩니다. 모든 목표 작업이 이산 토큰으로 구성되므로 교차 엔트로피 손실을 사용합니다.
- 다중 모달 마스크된 사전 훈련 목표: 4M은 다중 모달 마스크 모델링 목표를 사용하여 단일 통합 트랜스포머 인코더-디코더를 훈련하는 방법으로, 다중 모달 학습과 마스크 모델링의 이점을 결합합니다. 이는 풍부한 표현 학습, 강력한 교차 모달 예측 코딩 능력 및 공유 장면 표현 학습, 그리고 반복적인 샘플링을 통한 생성 작업 가능을 가능하게 합니다. 확장성을 위해, 4M은 입력 및 타겟 마스킹을 통해 효율적으로 훈련할 수 있습니다. 이는 모든 모달리티에서 무작위로 작은 부분 집합의 토큰을 입력으로 선택하고, 나머지 토큰의 다른 작은 부분 집합을 타겟으로 처리합니다. 입력 및 타겟 토큰의 수를 모달리티 수와 분리함으로써 계산 비용이 빠르게 증가하는 것을 방지합니다.
- 데이터 준비: 4M 모델 훈련에는 다양하고 대규모의 정렬된 다중 모달 데이터셋이 필요하지만, 기존 데이터셋은 요구 사항을 충족하지 못합니다. 이를 해결하기 위해, 공개적으로 사용 가능한 CC12M 데이터셋을 강력한 기성 모델을 사용하여 의사 라벨링(pseudo labeling)하여 바인딩 데이터셋으로 활용합니다. 이 접근 방식은 RGB 이미지 데이터셋만 있으면 되므로 대규모 웹 스케일 이미지 데이터셋으로 확장될 수 있습니다. 의사 라벨링된 모달리티에는 표면 노멀, 깊이, 의미론적 분할, 바운딩 박스, CLIP 특징 맵이 포함됩니다.
성능 및 결과
- 전이 학습: 4M은 ImageNet-1K 분류, COCO 탐지 및 인스턴스 분할, ADE20K 의미론적 분할, NYUv2 깊이 추정 등의 다운스트림 작업에 뛰어난 전이 성능을 보입니다. 특히 탐지, 분할 및 깊이 추정에서 기준 모델들보다 우수하며, ImageNet-1K에서는 특화된 모델에 비해 성능이 떨어집니다. 전반적으로 4M은 다중 의사 라벨링된 작업에서 사전 훈련함으로써 크게 이점을 얻는 다목적 비전 모델임을 보여줍니다.
- 생성 능력: 4M은 학습된 모든 모달리티를 반복적으로 디코딩하여 직접 생성에 사용할 수 있습니다. 어떤 훈련 모달리티든 (무조건적으로 또는 다른 모달리티 집합에 조건화하여) 생성할 수 있으며, 마스킹 기반 훈련 덕분에 조건부 인페인팅 및 아웃페인팅도 가능합니다. 이러한 기능들을 결합하여 의미론적 편집, 기하학적으로 기반한 생성 등 다양한 다중 모달 편집 작업을 수행합니다. 체인드 다중 모달 생성(Chained multimodal generation)은 생성된 모달리티를 후속 모달리티 생성의 조건으로 사용하여 일관된 출력을 만듭니다. 다중 모달 가이드(Multimodal weighted guidance)를 통해 다양한 모달리티(또는 그 부분)의 가중치를 다르게 설정하여 생성에 대한 정밀한 사용자 제어가 가능합니다. 약하게 조건화하거나 특정 개념을 피하기 위해 음수 가중치를 사용하는 것도 가능합니다.
- 학습된 표현 탐색: 입력의 일부를 조작하고 4M이 예측하는 방식을 관찰함으로써 학습된 표현을 탐색할 수 있습니다. 예를 들어, 바운딩 박스의 위치를 변경하면 4M이 객체의 의미론적 및 기하학적 특성을 암묵적으로 추론하여 장면의 일부가 되는 방식을 예측합니다. 분할 맵의 단일 세그먼트를 조작해도 4M은 타당한 생성을 수행합니다.
- 확장성 연구: 4M은 데이터셋 크기, 훈련 길이, 모델 크기에 따라 성능이 확장됨을 보여줍니다.
- 즉시 사용(Zero-shot) 성능: 4M은 미세 조정 없이도 표면 노멀 추정, 깊이 추정, 의미론적 분할과 같은 작업에서 경쟁력 있는 즉시 사용 성능을 보여줍니다.
- 텍스트-이미지 성능: 4M은 CC12M 데이터셋에서 학습된 전문가 모델과 유사한 텍스트-이미지 생성 성능을 보이지만, 더 큰 데이터셋과 계산 자원으로 학습된 최첨단 모델(예: Stable Diffusion 2.1)과는 성능 차이가 있습니다.
세부 연구 (Ablation Studies) 다중 모달 마스킹 목표의 핵심 설계 선택에 대한 광범위한 세부 연구가 수행되었습니다.
- 입력 및 타겟 모달리티: 모든 타겟 모달리티에 대해 사전 훈련하는 것이 평균 손실 면에서 다른 단일 작업 및 다중 작업 대안보다 지속적으로 우수하며, 미래 응용 프로그램이 알려지지 않은 경우 가장 다재다능한 선택입니다. 다중 모달 사전 훈련은 새로운 입력 모달리티로 전이하는 데 도움이 되지만, RGB를 유일한 입력 모달리티로 사용하는 전이에서는 성능 손실이 발생할 수 있습니다.
- 다중 모달 마스킹 전략: 마스킹 샘플링 매개변수(α)의 선택은 성능에 영향을 미치며, 높은 α 값으로 훈련된 모델은 RGB 작업에 더 잘 전이되는 경향이 있습니다. 입력 토큰 예산과 타겟 토큰 예산을 낮게 설정하면 계산 효율성이 향상되면서도 성능이 잘 유지됩니다. 다른 마스킹 전략을 혼합하여 사용하는 것은 다양한 다운스트림 작업에 대해 좋은 절충안이 될 수 있습니다.
- 아키텍처 및 훈련: 인코더 및 디코더 레이어의 균형 잡힌 할당은 좋은 성능을 보이며, 손실 계산 시 토큰당 손실이 아닌 모달리티당 손실로 평균화하는 것이 성능을 향상시킵니다. SwiGLU 활성화 함수와 바이어스 항 제거가 GELU보다 약간 더 나은 성능을 보였습니다. 데이터 로딩 효율성을 개선하기 위해 반복 샘플링을 사용하는 것이 성능 손실 없이 가능합니다.
한계 논문에서는 몇 가지 한계를 언급합니다:
- 추가 모달리티: 현재 포함된 모달리티 외에 에지, 스케치, 인간 자세 등의 추가 모달리티를 통합하면 4M의 유용성이 크게 향상될 수 있습니다.
- 토크나이저 품질: 더 나은 토크나이저는 생성 및 전이 결과 모두에 이점을 줄 수 있지만, 토큰화된 패치에 인코딩할 수 있는 정보의 양에는 한계가 있습니다.
- 데이터셋 크기 및 품질: 4M은 더 큰 데이터셋에서 훈련함으로써 이점을 얻을 수 있지만, 웹 스크랩된 데이터셋에는 저품질 이미지나 관련 없는 캡션이 포함될 수 있습니다. 더 선별된 데이터셋에서 미세 조정하거나 강화 학습을 사용하면 생성 품질과 다양성을 개선할 수 있습니다.
결론 4M은 다중 모달 마스크 모델링 목표를 사용하여 비전 작업을 위한 다재다능하고 확장 가능한 기초 모델을 훈련하기 위한 범용 프레임워크입니다. 즉시 다양한 비전 작업을 수행할 수 있을 뿐만 아니라 광범위한 다운스트림 작업에 대한 강력한 전이 결과도 보여줍니다. 인페인팅 및 any-to-any 생성 능력은 단일 모델로 광범위한 다중 모달 생성 및 표현적인 편집 작업을 가능하게 합니다.
논문의 Appendix는 본문의 내용을 보충하고, 실험 설정, 추가 결과, 세부 연구 결과, 데이터 준비 과정 등을 상세히 설명하는 역할을 합니다. 4M 논문의 Appendix는 크게 7개의 섹션 (A부터 G까지)으로 구성되어 있습니다.
Appendix A: Generative Capabilities & Probing the Learned Representation 이 섹션에서는 본문에서 간략히 언급된 4M 모델의 생성 능력과 학습된 표현을 탐색하는 방법에 대한 추가적인 세부 사항 및 시각 자료를 제공합니다.
- A.1 토큰 초해상도 (Token super-resolution): 4M이 기본 해상도(224x224 픽셀)에서 학습되었기 때문에 미세한 디테일 모델링에 한계가 있습니다. 이를 해결하기 위해, 4M-L 모델을 기반으로 4M-SR이라는 초해상도 모델을 별도로 학습시켰습니다. 이 모델은 저해상도 이미지 토큰을 고해상도 토큰으로 매핑하도록 fine-tuning되어, 이미지를 두 배 해상도(448x448 픽셀)로 업스케일하면서 디테일을 추가할 수 있습니다. 훈련 설정 및 과정이 상세히 설명되어 있습니다.
- A.2 생성 작업별 특화 (Generation-specific specializations): 4M 모델을 특정 생성 작업에 최적화하기 위해 fine-tuning하는 방법을 설명합니다. 예를 들어, 텍스트-이미지 생성에 대해 모델을 최적화하려면, 토큰 샘플링 분포를 캡션 입력이 더 많이 포함되도록 조정하여 fine-tuning할 수 있습니다.
- A.3 생성 절차 세부 사항 (Generation procedure details): 토큰 기반 마스크 이미지 모델을 사용하여 이미지를 생성하는 반복적인 디코딩 방식 (MaskGIT, ROAR 등)과 순차 모달리티에 대한 좌측-우측 자동 회귀 방식이 설명됩니다. 또한, 생성된 모달리티를 후속 모달리티 생성의 조건으로 사용하는 체인드 다중 모달 생성(Chained generation)이 설명되어, 일관성 있는 출력을 만들 수 있습니다. Classifier-free guidance 및 다중 모달 가이드(Multimodal guidance)를 통해 조건부 생성에 대한 제어력을 높이는 방법도 상세히 다루어집니다. 다중 모달 가이드에서는 여러 모달리티의 가중치를 다르게 설정하거나 음수 가중치를 사용하여 특정 개념을 피하는 등의 세밀한 제어가 가능함을 보여줍니다.
- A.4 추가 시각화 (Additional visualizations): RGB 이미지를 입력으로 받아 표면 노멀, 깊이, 의미론적 분할, 객체 탐지, 캡션 등을 예측하는 다양한 작업 예시(RGB→X), 체인드 생성 예시, 어떤 모달리티든 다른 모달리티에 조건화하여 생성하는 예시(Any-to-any generation), 마스킹된 영역을 조건에 기반하여 채우는 예시(Conditional in-painting), 원본 이미지의 특정 모달리티에 기반하여 이미지 변형을 생성하는 예시(Grounded generation), 다중 모달 가이드 예시, 그리고 입력 일부를 조작하여 모델의 예측을 관찰하는 방식의 학습된 표현 탐색 예시 등이 풍부하게 제공됩니다.
Appendix B: Multimodal Dataset & Tokenization 이 섹션은 4M 모델 학습에 사용된 다중 모달 데이터셋을 구축하고 모달리티를 토큰화하는 과정에 대한 자세한 내용을 설명합니다.
- B.1 의사 라벨링된 다중 모달 훈련 데이터셋 (Pseudo labeled multimodal training dataset details): 공개 데이터셋인 CC12M의 RGB 이미지와 캡션을 기반으로, 강력한 기성 모델들을 사용하여 표면 노멀, 깊이, 의미론적 분할, 바운딩 박스, CLIP 특징 맵을 의사 라벨링(pseudo labeling)하는 과정이 설명됩니다. 사용된 구체적인 모델(DPT-Hybrid, Mask2Former, ViTDet, CLIP ViT-B/16)과 설정이 명시되어 있습니다.
- B.2 캡션 및 바운딩 박스 토큰화 (Tokenization of captions & bounding boxes): 캡션과 바운딩 박스 모두 텍스트처럼 처리되어 WordPiece를 사용하여 인코딩됩니다. 바운딩 박스는 Pix2Seq 방식을 따라 객체 탐지 작업을 순차 예측 문제로 변환하며, 마스킹 처리를 용이하게 하기 위해 코너 좌표에 대해 별도의 토큰을 할당하고 객체 순서를 정렬하는 등의 수정이 이루어졌습니다. 캡션과 바운딩 박스 토큰은 함께 30K 크기의 어휘집을 구성합니다.
- B.3 조밀 모달리티 토큰화 (Tokenization of dense modalities): RGB, 깊이, 노멀, 의미론적 분할 맵, CLIP 특징 맵과 같은 조밀한 모달리티는 학습된 VQ-VAE를 사용하여 토큰화됩니다. 특히, RGB, 노멀, 깊이의 토크나이저는 사실적인 결과 생성을 위해 확산 모델(Diffusion model) 디코더를 사용합니다. 토크나이저 학습 과정(ImageNet-1K 후 CC12M) 및 설정, 코드북 관리(stale codebook entries 재시작), 멀티 해상도 fine-tuning, 그리고 각 모달리티별 토크나이저 구조 및 손실 함수에 대한 세부 사항이 제공됩니다.
Appendix C: Method & Training Details 이 섹션에서는 4M 모델의 아키텍처 및 훈련 설정에 대한 더 많은 기술적 세부 사항을 다룹니다.
- C.1 추가 4M 아키텍처 세부 사항 (Additional 4M architecture details): 4M이 표준 트랜스포머 인코더-디코더 구조를 따르지만, 다중 모달 처리를 위한 수정사항이 포함됨을 설명합니다. 모달리티별 학습 가능한 입력 임베딩, 모달리티 임베딩, 위치 임베딩 사용. 인코더는 RGB 픽셀을 직접 입력으로 받을 수 있도록 설계되었으며, 디코더는 조밀 모달리티와 순차 모달리티를 다르게 처리합니다. 모든 인코더 토큰에 어텐션하며, 모달리티별 어텐션 마스크를 사용하고, 순차 모달리티에는 인과적 마스크를 적용합니다. 모든 타겟 작업에 대해 교차 엔트로피 손실을 사용합니다. 다양한 모델 크기(Tiny, Small, Base, Large, XL)에 대한 상세 정보가 표로 제공됩니다. 순차 모달리티에 대한 스팬 마스킹(Span masking) 절차도 설명됩니다.
- C.2 훈련 세부 사항 (Training details): 본문 실험에 사용된 4M-B, -L, -XL 모델의 훈련 하이퍼파라미터(옵티마이저, 학습률, 배치 크기, 가중치 감소, 활성화 함수, 토큰 예산, α 값 등)가 상세히 제시됩니다. 각 모델 크기별 훈련 시간 및 사용된 하드웨어 정보도 포함됩니다. 4M-XL 모델 훈련 시 메모리 절감을 위해 Activation Checkpointing 및 ZeRO-2 (FSDP)를 사용했음이 언급됩니다.
Appendix D: Transfer Experiments Details 본문 섹션 3에서 보고된 전이 학습 실험의 세부 설정을 설명합니다.
- 일반적으로 사용되는 설정을 따랐지만, 계산 비용 절감을 위해 이미지넷-21K fine-tuning 에폭 감소, COCO 해상도 감소 등의 조정이 있었음이 명시됩니다.
- D.1 아키텍처 차이 (Architectural differences): 4M 인코더와 비교 대상 baseline 모델 간의 사소한 아키텍처 차이점(Bias 항 유무, 활성화 함수, CLS 토큰, 위치 임베딩 등)이 언급됩니다.
- D.2 이미지 분류 (Image classification on ImageNet-1K): ImageNet-21K에서의 중간 fine-tuning 및 ImageNet-1K에서의 최종 fine-tuning 설정이 상세한 하이퍼파라미터와 함께 표로 제시됩니다.
- D.3 객체 탐지 및 인스턴스 분할 (Object detection and instance segmentation on COCO): ViTDet 및 Cascade Mask-RCNN 기반 설정에 해상도 및 어텐션 방식 변경을 포함한 세부 하이퍼파라미터가 표로 제시됩니다.
- D.4 의미론적 분할 (Semantic segmentation on ADE20K): ConvNext 예측 헤드를 사용한 ADE20K fine-tuning 설정이 표로 제시됩니다.
- D.5 깊이 추정 (Depth estimation on NYUv2): ConvNeXt 예측 헤드를 사용한 NYUv2 fine-tuning 설정이 표로 제시됩니다.
Appendix E: Ablation Details & Results 본문 섹션 5에서 논의된 4M 모델의 주요 설계 선택에 대한 세부 연구 결과와 추가적인 아키텍처 및 훈련 관련 세부 연구 결과를 제공합니다.
- E.1 벤치마크 작업 (Benchmark tasks): 세부 연구에 사용된 전이 학습 작업들을 모두 토큰 대 토큰 예측 문제로 설정했음이 설명됩니다. 성능 측정은 교차 엔트로피 손실을 사용하며, 보이지 않는 입력 모달리티로 전이할 때 새로운 임베딩 레이어를 먼저 훈련하는 전략이 언급됩니다. COCO, ADE20K, Taskonomy-20K 및 Hypersim 데이터셋에서의 RGB→X, X→Y, X+Y→Z 전이 설정이 상세히 제시됩니다.
- E.2 참조 모델 (Reference model): 세부 연구의 기준이 되는 참조 모델의 크기 및 훈련 설정이 상세히 제시됩니다. 10개의 독립적인 참조 모델 훈련을 통해 전이 결과의 표준 편차를 계산하여 유의미성을 판단했음이 설명됩니다. 무작위 초기화 모델의 성능(from-scratch 결과)도 함께 제시되어 기준 성능을 보여줍니다.
- E.3 입력 모달리티 및 타겟 작업 (Input modalities and target tasks): 다양한 입력 및 타겟 모달리티 조합에 대한 전이 성능(평균 손실 및 순위) 결과가 표로 상세히 제시됩니다. 특정 타겟 작업에 대한 학습이 모델이 학습하는 표현에 영향을 미치며, 모든 타겟 모달리티에 대한 사전 학습이 평균 손실 측면에서 가장 다재다능한 선택임을 재확인합니다. 다중 모달 사전 학습이 새로운 입력 모달리티로의 전이에 도움이 되지만, RGB만 입력으로 사용하는 전이에서는 성능 손실이 발생할 수 있음을 보여줍니다.
- E.4 다중 모달 마스킹 전략 (Multimodal masking strategy): 마스크 샘플링 매개변수 α, 입력 토큰 예산, 타겟 토큰 예산, 다양한 마스킹 전략 혼합(RGB → All vs All → All vs Mixture)에 대한 세부 연구 결과가 표와 그래프로 제시됩니다. 낮은 입력/타겟 토큰 예산으로도 성능이 잘 유지되면서 효율성이 향상됨을 보여주고, 다양한 마스킹 전략을 혼합하는 것이 여러 다운스트림 작업에 대한 좋은 절충안이 될 수 있음을 시사합니다.
- E.5 4M 확장성 (How well does 4M scale?): 데이터셋 크기, 훈련 길이, 모델 크기에 따른 4M의 성능 변화를 보여주는 결과가 표와 그래프로 제시됩니다. 데이터셋, 훈련 시간, 모델 크기가 증가함에 따라 4M의 성능이 확장됨을 보여줍니다.
- E.6 아키텍처 설계 선택 (Architectural design choices): 인코더 및 디코더 레이어 할당, 손실 계산 방식(토큰별 평균 vs 모달리티별 평균), 트랜스포머 아키텍처 수정(활성화 함수, Bias 제거, Query/Key 정규화)에 대한 세부 연구 결과가 표로 제시됩니다. 모달리티별 평균 손실 계산이 성능을 향상시키고, SwiGLU 활성화 함수와 Bias 제거가 GELU보다 약간 더 나은 성능을 보이며 최종 모델에 사용되었음이 언급됩니다.
- E.7 훈련 설계 선택 (Training design choices): 기본 학습률 및 반복 샘플링(Repeated sampling) 사용에 대한 세부 연구 결과가 표로 제시됩니다. 반복 샘플링이 데이터 로딩 효율성을 향상시키면서 성능 손실이 없음을 보여줍니다.
- E.8 자체 기준선 (Self-baselines): MAE와 BEiT-v2와 개념적으로 유사한 자체 기준선(RGB→RGB 및 RGB→CLIP)을 다양한 마스킹 전략으로 훈련한 결과가 표로 제시됩니다. 각 기준선에 최적인 마스킹 전략이 다름을 보여줍니다.
- E.9 최종 모델과의 비교 (Comparison to the final models): 세부 연구 결과를 바탕으로 훈련된 최종 4M 모델이 참조 모델보다 모든 벤치마크 작업에서 훨씬 우수한 성능을 보임을 표로 제시합니다.
Appendix F: Additional Evaluations 본문 외 추가적인 평가 결과를 제시합니다.
- F.1 즉시 사용 성능 (Out of the box (zero-shot) performance): fine-tuning 없이 표면 노멀 추정, 깊이 추정, 의미론적 분할 작업에 대한 4M 모델의 즉시 사용 성능을 평가합니다. 기성 baseline 모델 및 의사 라벨링에 사용된 모델과 비교하여 경쟁력 있는 성능을 보임을 표로 제시합니다. 토큰화 품질이 즉시 사용 성능의 병목이 아님을 시사합니다.
- F.2 텍스트-이미지 성능 (Text-to-image performance): 텍스트-이미지 생성 능력에 대한 정량적 평가 결과(FID, CLIP 점수)를 제시합니다. CC12M 데이터셋에서 학습된 4M 모델이 전용 텍스트-이미지 모델과 유사한 성능을 보이지만, 더 큰 데이터셋과 계산 자원으로 학습된 최첨단 모델(예: Stable Diffusion 2.1)과는 성능 차이가 있음을 보여줍니다.
Appendix G: Broader Impact 연구의 광범위한 영향에 대해 논의합니다.
- G.1 계산 비용 (Computational costs): 다양한 크기의 4M 모델 및 세부 연구 모델 훈련에 소요된 시간 및 하드웨어 자원 정보를 제공합니다.
- G.2 사회적 영향 (Social impact): 범용 파운데이션 모델 개발의 이점 및 코드/모델 오픈 소스화를 통한 민주화 지원에 대해 언급합니다. 강력한 생성 모델의 잠재적인 부정적 사용 및 훈련 데이터셋(CC12M)에 포함될 수 있는 사회적 편향에 대한 주의를 환기합니다.
요약하자면, 4M 논문의 Appendix는 모델의 아키텍처, 데이터 준비(의사 라벨링, 토큰화), 훈련 상세 설정, 전이 학습 및 생성 능력에 대한 추가적인 실험 결과와 세부 분석을 매우 상세하게 제공하여, 본문의 내용을 깊이 이해하고 4M 방법론의 강점, 한계 및 설계 선택의 근거를 파악하는 데 필수적인 부분입니다. 특히, 광범위한 세부 연구 결과를 통해 모델의 확장성, 마스킹 전략의 영향, 아키텍처 및 훈련 설정의 효과 등을 탐구하며, 이는 향후 다중 모달 학습 연구에 중요한 통찰을 제공합니다.
'Paper Review' 카테고리의 다른 글
| Convolutional Vision Transformer (CvT) 논문 리뷰 (0) | 2025.06.15 |
|---|---|
| "Training data-efficient image transformers & distillation through attention" DeiT 논문 리뷰 (2) | 2025.06.15 |
| ARTrackV2 논문 리뷰 (2) | 2025.06.10 |
| "A Discriminative Semantic Ranker for Question Retrieval" DenseTrans 리뷰 (1) | 2025.06.10 |
| "TransUNet: Transformers Make Strong Encoders for Medical Image Segmentation" 리뷰 (0) | 2025.06.10 |