1. 서론 및 배경 (Introduction and Background)
- 최근 어텐션 기반 신경망이 이미지 분류와 같은 이미지 이해 작업에서 높은 성능을 보여주었습니다 [1]. 특히 비전 트랜스포머(Vision Transformer, ViT)는 이미지 분류 작업에 원시 이미지 패치를 입력으로 직접 적용하여 우수한 결과를 달성했습니다 [2, 3].
- 그러나 기존의 고성능 비전 트랜스포머는 대규모 인프라를 사용하여 수억 개의 이미지로 사전 학습되어야 하므로, 그 채택이 제한적이었습니다 [1, 3, 4]. Dosovitskiy et al.의 연구 [5]에서는 트랜스포머가 "불충분한 양의 데이터로 학습할 때 잘 일반화되지 않는다"고 결론지었으며, 이러한 모델의 학습에는 광범위한 컴퓨팅 자원이 필요했습니다 [3].
- 오랜 기간 동안 이미지 이해 작업의 주된 설계 패러다임은 컨볼루션 신경망(Convolutional Neural Networks, CNNs)이었으며, Imagenet [6, 7]과 같은 대규모 학습 데이터셋의 가용성이 CNN 성공의 중요한 요소였습니다 [8, 9].
- 이 논문은 이미지넷(Imagenet) 데이터셋만으로 경쟁력 있는 컨볼루션 없는 트랜스포머를 개발하고, 단일 컴퓨터에서 3일 이내에 학습시키는 것을 목표로 합니다 [10].
2. 주요 기여 (Main Contributions)
이 연구는 다음과 같은 주요 기여를 합니다 [11, 12]:
- 컨볼루션 레이어가 없는 신경망이 외부 데이터 없이 ImageNet에서 최첨단 성능과 경쟁할 수 있음을 보여주었습니다 [11]. 이 모델들은 단일 노드(4 GPU)에서 3일 만에 학습됩니다 [11]. DeiT-S 및 DeiT-Ti와 같은 새로운 소형 모델도 제시됩니다 [11].
- 새로운 증류 절차인 '증류 토큰(distillation token)'을 기반으로 한 방법을 도입했습니다 [12]. 이 증류 토큰은 클래스 토큰과 동일한 역할을 하지만, 교사 모델이 추정한 레이블을 재현하는 것을 목표로 합니다 [13]. 이 트랜스포머 특정 전략은 일반적인 증류보다 훨씬 우수한 성능을 보입니다 [12].
- 흥미롭게도, 이 증류 방식을 사용하면 이미지 트랜스포머가 유사한 성능의 다른 트랜스포머보다 컨볼루션 네트워크(convnet)로부터 더 많이 학습한다는 것을 발견했습니다 [12, 14].
- ImageNet에서 사전 학습된 모델들은 CIFAR-10, CIFAR-100, Oxford-102 flowers, Stanford Cars, iNaturalist-18/19와 같은 다른 다운스트림 작업으로 전이 학습할 때도 경쟁력 있는 성능을 보입니다 [12].
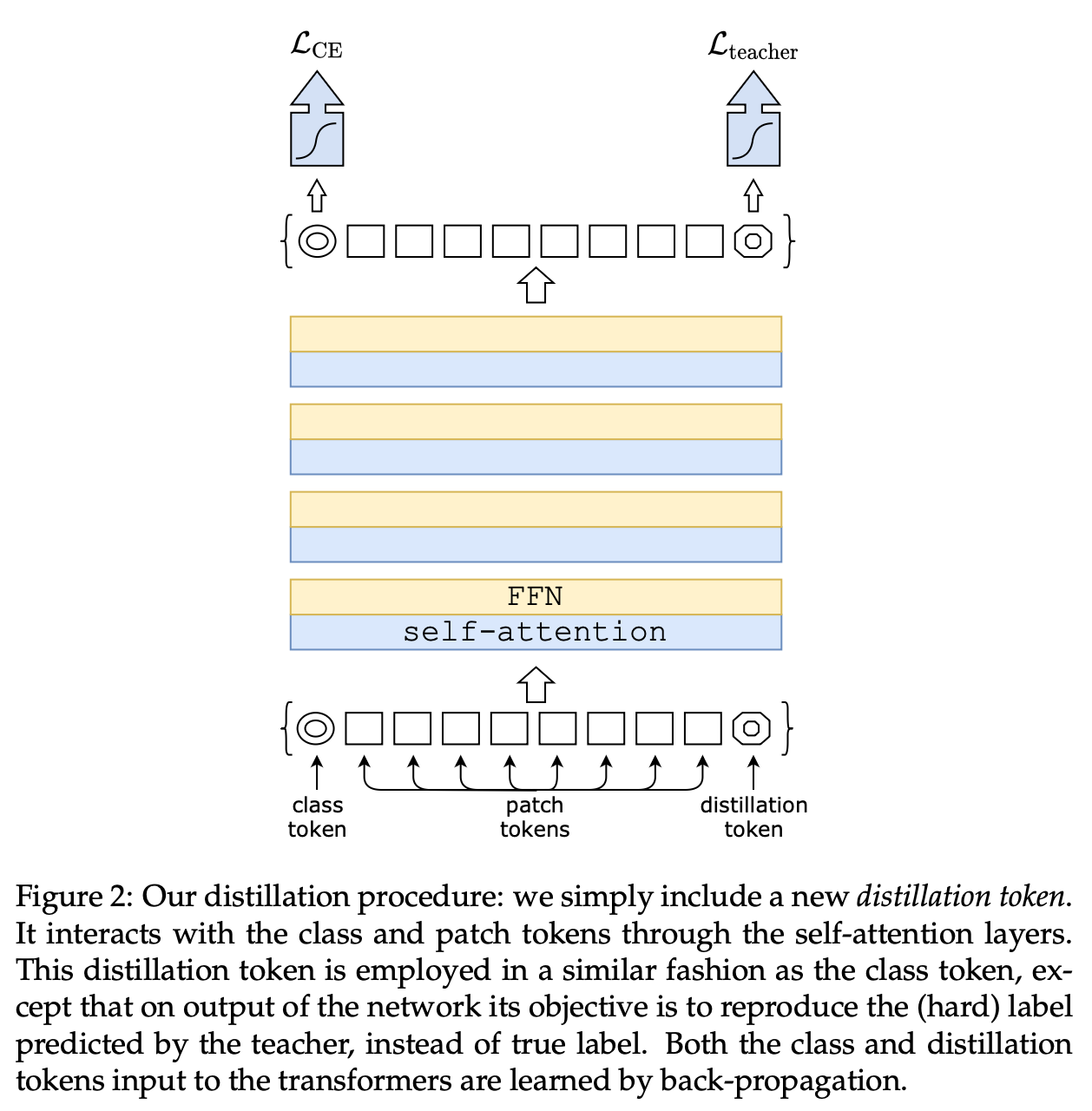
3. DeiT 아키텍처 및 학습 전략 (DeiT Architecture and Training Strategy)
- 아키텍처: DeiT는 Dosovitskiy et al. [5]이 제안한 ViT 모델과 동일한 아키텍처 설계를 사용하며, 컨볼루션이 없습니다 [15]. 주요 차이점은 학습 전략과 증류 토큰의 사용입니다 [15]. ViT-B와 동일한 아키텍처를 가진 DeiT-B가 주요 참조 모델입니다 [15, 16]. DeiT-Ti, DeiT-S, DeiT-B 세 가지 모델 변형이 소개됩니다 [16, 17].
- 데이터 효율적 학습: DeiT는 ImageNet만 사용하여 학습되며, 단일 8-GPU 노드에서 2~3일(사전 학습 53시간, 선택적 미세 조정 20시간) 내에 학습되어 유사한 파라미터 수와 효율성을 가진 컨볼루션 네트워크와 경쟁합니다 [3, 18].
- 학습 하이퍼파라미터 및 정규화: 트랜스포머는 학습 초기화에 민감하며, 저자들은 절단된 정규 분포로 가중치를 초기화하는 방법을 따랐습니다 [19, 20]. 학습률은 배치 크기에 따라 조정되며, AdamW 옵티마이저가 사용됩니다 [21, 22].
- 강력한 데이터 증강: DeiT는 Rand-Augment [23], random erasing [24], Mixup [25], Cutmix [26], 그리고 성능 향상에 중요한 기여를 하는 반복 증강(repeated augmentation) [2, 15] 등 광범위한 데이터 증강을 사용합니다 [22, 27]. 드롭아웃(dropout)은 학습 절차에서 제외됩니다 [27].
- 확률적 깊이 (Stochastic Depth): 트랜스포머의 수렴을 용이하게 하는 확률적 깊이 [14]를 사용합니다 [22].
- 고해상도 미세 조정: DeiT 모델은 기본적으로 224x224 해상도에서 학습되고 384x384 해상도에서 미세 조정됩니다 [18]. Touvron et al. [27]의 미세 조정 절차를 채택하며, 위치 임베딩은 해상도 변경 시 보간됩니다 [28, 29].
4. 어텐션을 통한 증류 (Distillation through Attention)
- 지식 증류(Knowledge Distillation, KD): 힌튼(Hinton) 등이 도입한 지식 증류 [30]는 강한 교사 신경망의 "소프트 레이블"을 활용하여 학생 모델을 학습시키는 패러다임입니다 [23]. 이는 학생 모델의 성능을 향상시키거나 교사 모델을 더 작은 모델로 압축하는 형태로 볼 수 있습니다 [23].
- 소프트 증류 vs. 하드 증류:
- 소프트 증류: 교사 모델의 소프트맥스 출력과 학생 모델의 소프트맥스 출력 간의 쿨백-라이블러 발산(Kullback-Leibler divergence)을 최소화합니다 [31].
- 하드 레이블 증류: 교사 모델의 하드 결정(최대 로짓에 해당하는 클래스)을 참 레이블로 사용하여 학습합니다 [32]. 이 논문에서는 하드 증류가 소프트 증류보다 더 나은 선택이며, 파라미터가 없다는 장점이 있다고 설명합니다 [32, 33].
- 증류 토큰 (Distillation Token):
- 이 연구의 핵심 제안으로, 기존 임베딩(패치 및 클래스 토큰)에 새로운 증류 토큰을 추가합니다 [34].
- 증류 토큰은 클래스 토큰과 유사하게 사용되며, 자기 어텐션을 통해 다른 임베딩과 상호 작용합니다 [34].
- 네트워크의 마지막 레이어에서 출력되며, 그 목표는 교사의 (하드) 레이블 예측을 재현하는 것입니다 [13, 34].
- 이 증류 임베딩은 모델이 일반적인 증류처럼 교사의 출력으로부터 학습하도록 하면서도 클래스 임베딩과 상호 보완적인 관계를 유지합니다 [34].
- 클래스 토큰과 증류 토큰은 네트워크를 통해 점차 유사해지지만, 마지막 레이어에서도 완전히 동일하지는 않습니다 (코사인 유사도 0.93) [35]. 이 증류 토큰 전략은 일반적인 증류보다 훨씬 우수한 성능 향상을 제공합니다 [33, 35].
- 컨볼루션 네트워크를 교사로 사용: 컨볼루션 네트워크를 교사로 사용할 때 트랜스포머 교사를 사용하는 것보다 더 나은 성능을 얻는다고 언급합니다 [12, 14]. 이는 증류를 통해 트랜스포머가 컨볼루션 네트워크로부터 유도 편향(inductive bias)을 상속받기 때문일 가능성이 높다고 설명합니다 [14, 36].
- 결합 분류기 (Joint Classifiers): 테스트 시에는 트랜스포머가 생성하는 클래스 또는 증류 임베딩 모두 선형 분류기와 연관되어 이미지 레이블을 추론할 수 있습니다 [30]. 저자들의 참조 방법은 이 두 개의 분리된 헤드의 후기 융합(late fusion)이며, 예측을 위해 두 분류기의 소프트맥스 출력을 더합니다 [30].
5. 실험 결과 (Experimental Results)
- ImageNet 성능:
- DeiT-B는 ImageNet에서 외부 데이터 없이 83.1%의 단일 크롭(single-crop) 상위-1 정확도를 달성합니다 [10].
- DeiT⚗(증류 적용 모델)은 ImageNet에서 최대 85.2% 정확도를 달성하며, 컨볼루션 네트워크와 경쟁력 있는 결과를 보고합니다 [10, 37-39]. 이는 JFT-300M에서 사전 학습된 ViT-B 모델(84.15%)을 능가합니다 [37, 40].
- DeiT는 EfficientNet보다 약간 낮지만, RegNetY와 같은 상대적으로 약한 교사로부터 증류 혜택을 받으면 EfficientNet을 능가합니다 [40].
- 하드 증류는 소프트 증류보다 트랜스포머에 대해 훨씬 우수한 성능을 보이며 (83.0% vs 81.8%), 증류 토큰 전략은 분류에 유용한 보완 정보를 제공하여 성능을 더욱 향상시킵니다 [33].
- 증류 토큰은 클래스 토큰보다 약간 더 나은 결과를 제공하며, 컨볼루션 네트워크의 예측과 더 높은 상관관계를 보입니다 [36].
- 교사 유형의 영향: 컨볼루션 네트워크 교사(RegNetY-16GF)가 트랜스포머 교사보다 더 나은 성능을 제공함이 확인됩니다 [12, 14, 36]. DeiT⚗ 모델은 레이블만으로 학습된 DeiT보다 컨볼루션 네트워크에 더 상관관계가 높습니다 [41].
- 학습 시간: DeiT-B의 일반적인 300 에포크 학습은 단일 노드에서 53시간이 소요됩니다 [18]. 이는 RegNetY-16GF보다 20% 빠릅니다 [18].
- 전이 학습 (Transfer Learning): ImageNet에서 사전 학습된 DeiT 모델은 CIFAR-10, CIFAR-100, Oxford-102 Flowers, Stanford Cars, iNaturalist-18/19 등 여러 다운스트림 작업에서 ViT 및 최첨단 컨볼루션 아키텍처와 대등한 성능을 보입니다 [12, 42, 43]. ImageNet 사전 학습 없이 CIFAR-10만으로 학습한 경우에도 DeiT-B⚗은 98.5%의 정확도를 달성하며 합리적인 성능을 보입니다 [7].
6. 결론 (Conclusion)
- 이 논문은 향상된 학습 전략, 특히 새로운 증류 절차를 통해 대규모 데이터 없이도 학습 가능한 이미지 트랜스포머인 DeiT를 소개했습니다 [44].
- 이미지 트랜스포머가 컨볼루션 네트워크와 대등한 성능을 보이는 것을 고려할 때, 주어진 정확도에서 더 낮은 메모리 사용량을 가지므로 빠르게 선호되는 방법이 될 것이라고 믿습니다 [45].
- DeiT의 오픈 소스 구현은 https://github.com/facebookresearch/deit에서 제공됩니다 [45].
이 논문은 트랜스포머가 이미지 이해 작업에서 데이터 효율적으로 학습될 수 있음을 효과적으로 입증했으며, 특히 제안된 증류 토큰 기반의 증류 전략이 성능 향상에 크게 기여함을 보여줍니다.
'Paper Review' 카테고리의 다른 글
| wav2vec 2.0 논문 리뷰 (1) | 2025.06.15 |
|---|---|
| Convolutional Vision Transformer (CvT) 논문 리뷰 (0) | 2025.06.15 |
| "4M: Massively Multimodal Masked Modeling" 논문 리뷰 (1) | 2025.06.10 |
| ARTrackV2 논문 리뷰 (2) | 2025.06.10 |
| "A Discriminative Semantic Ranker for Question Retrieval" DenseTrans 리뷰 (1) | 2025.06.10 |