wav2vec 2.0: 음성 표현의 자기 지도 학습을 위한 프레임워크
이 논문은 레이블링되지 않은 음성 오디오만으로 강력한 표현(representation)을 학습하고, 이를 레이블링된 음성 데이터로 미세 조정(fine-tuning)하여, 기존의 최첨단 반 자기 지도(semi-supervised) 방법보다 우수한 성능을 달성할 수 있음을 처음으로 보여주는 연구입니다.
1. 서론 및 배경 신경망은 대량의 레이블링된 훈련 데이터로부터 이점을 얻습니다. 그러나 전 세계 약 7,000개 언어의 대다수에서는 수천 시간의 전사된 음성 데이터 확보가 어렵기 때문에, 현재 음성 인식 시스템을 구축하기 어렵습니다. 인간의 언어 습득 방식이 레이블링된 예제로부터만 배우는 것과 다르다는 점에 착안하여, 이 연구는 자기 지도 학습(self-supervised learning) 패러다임을 음성 데이터에 적용합니다. 자기 지도 학습은 레이블링되지 않은 데이터로부터 일반적인 데이터 표현을 학습하고, 이후 모델을 레이블링된 데이터로 미세 조정하는 방식입니다. 이는 자연어 처리 분야에서 성공을 거두었으며, 컴퓨터 비전 분야에서도 활발히 연구되고 있습니다.
2. 핵심 프레임워크 및 아이디어 wav2vec 2.0은 원본 오디오 데이터로부터 표현을 자기 지도 학습하는 프레임워크를 제시합니다. 이 접근 방식은 음성 오디오를 다층 컨볼루션 신경망(CNN)을 통해 인코딩한 다음, 결과로 나오는 잠재 음성 표현(latent speech representations)의 스팬(spans)을 마스킹합니다. 이는 마스킹된 언어 모델링(masked language modeling)과 유사합니다. 마스킹된 잠재 표현들은 트랜스포머(Transformer) 네트워크에 입력되어 문맥화된 표현(contextualized representations)을 구축하며, 모델은 양자화된 잠재 표현에 대해 정의된 대조적 작업(contrastive task)을 통해 훈련됩니다.
이 프레임워크는 문맥화된 음성 표현과 이산적인 음성 단위(discrete speech units)의 인벤토리를 공동으로 학습합니다. 기존 작업들이 데이터의 양자화를 먼저 학습한 다음 자기 주의(self-attention) 모델로 문맥화된 표현을 학습했던 것과 달리, wav2vec 2.0은 이 두 가지 문제를 종단 간(end-to-end)으로 해결합니다. 사전 훈련(pre-training) 후, 모델은 다운스트림 음성 인식 작업을 위해 Connectionist Temporal Classification (CTC) 손실을 사용하여 레이블링된 음성 데이터에 미세 조정됩니다.
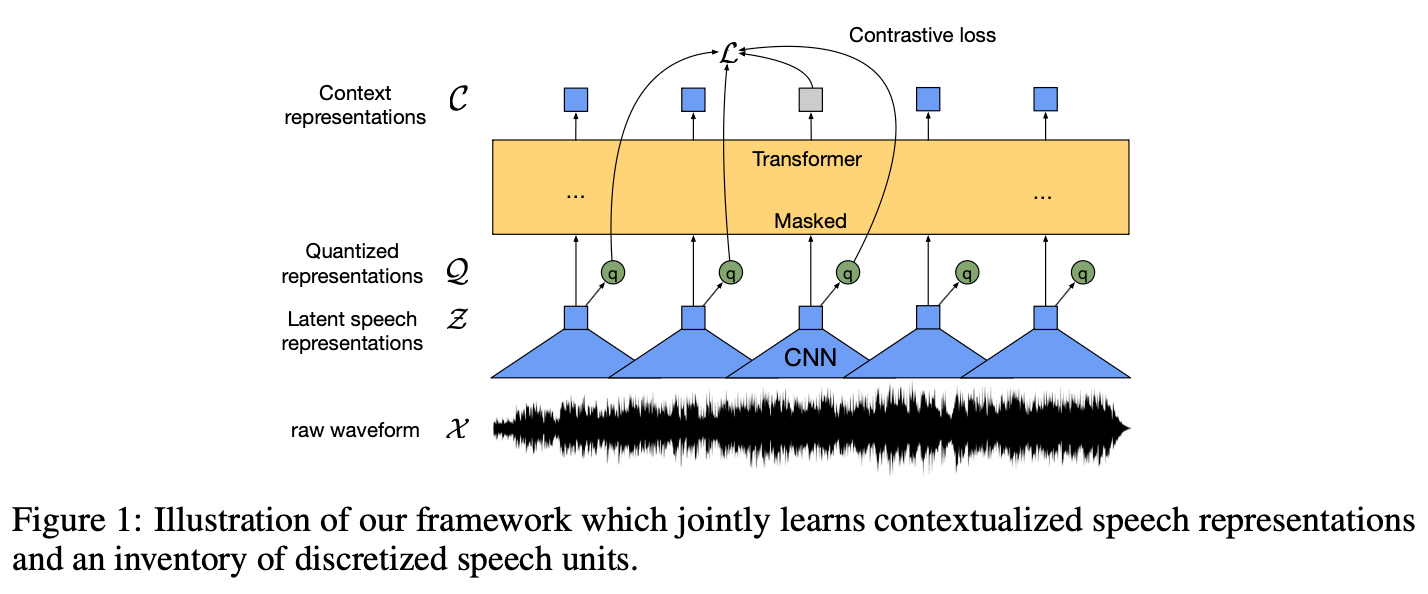
3. 모델 아키텍처 모델은 크게 세 가지 구성 요소로 이루어져 있습니다:
- 특징 인코더 (Feature Encoder): 원본 오디오 X를 입력으로 받아 잠재 음성 표현 z1, ..., zT를 출력하는 다층 컨볼루션 특징 인코더 f입니다. 이 인코더는 여러 블록으로 구성되며, 각 블록은 시간 컨볼루션, 레이어 정규화(layer normalization), GELU 활성화 함수(activation function)를 포함합니다.
- 트랜스포머 (Transformer): 특징 인코더의 출력 Z를 입력으로 받아 전체 시퀀스의 정보를 포착하는 문맥화된 표현 c1, ..., cT를 구축합니다. 고정된 위치 임베딩 대신, 컨볼루션 레이어를 사용하여 상대적 위치 임베딩(relative positional embedding) 역할을 수행합니다.
- 양자화 모듈 (Quantization Module): 특징 인코더의 출력 z를 유한한 음성 표현 집합으로 이산화(discretize)하여 자기 지도 목적 함수의 타겟(targets) q를 나타냅니다. 이는 제품 양자화(product quantization)를 통해 이루어지며, Gumbel softmax를 사용하여 이산적인 코드북 엔트리를 완전 미분 가능하게 선택할 수 있습니다.
4. 훈련 방법
- 사전 훈련 (Pre-training):
- 마스킹: 잠재 특징 인코더 공간의 특정 비율의 타임 스텝(time steps)을 마스킹하고, 마스킹된 모든 타임 스텝에서 공유되는 훈련된 특징 벡터로 대체합니다. 무작위로 시작 인덱스를 샘플링하고, 각 샘플링된 인덱스에서 M개의 연속적인 타임 스텝을 마스킹합니다. 예를 들어, 총 타임 스텝의 약 49%가 마스킹되며, 평균 마스킹 길이는 14.7 타임 스텝(299ms)입니다.
- 목적 함수:
- 대조 손실 (Contrastive Loss, Lm): 마스킹된 타임 스텝에 대해 일련의 방해물(distractors) 중에서 올바른 양자화된 잠재 음성 표현을 식별하도록 모델을 훈련시킵니다. 방해물은 동일한 발화의 다른 마스킹된 타임 스텝에서 균일하게 샘플링됩니다.
- 다양성 손실 (Diversity Loss, Ld): 코드북 엔트리들이 균등하게 사용되도록 장려하여, 양자화된 코드북 표현의 활용을 증가시킵니다.
- 전체 손실은 L = Lm + αLd로 정의됩니다.
- 미세 조정 (Fine-tuning):
- 사전 훈련된 모델은 문맥 네트워크 위에 무작위로 초기화된 선형 투영(linear projection)을 추가하여 음성 인식을 위해 미세 조정됩니다.
- CTC 손실(CTC loss)을 최소화하여 최적화되며, 오버피팅을 지연시키고 오류율을 크게 개선하기 위해 SpecAugment와 유사한 마스킹 전략을 적용합니다. 특징 인코더는 미세 조정 중에 훈련되지 않습니다.
5. 실험 설정 및 결과
- 데이터셋: 레이블링되지 않은 데이터로는 Librispeech (LS-960, 960시간) 또는 LibriVox (LV-60k, 53.2k 시간)를 사용했습니다. 미세 조정은 10분, 1시간, 10시간, 100시간, 960시간 등 다양한 양의 레이블링된 Librispeech 데이터셋과 TIMIT 데이터셋에서 수행되었습니다.
- 모델 구성: BASE (9,500만 파라미터)와 LARGE (3억 1,700만 파라미터) 두 가지 모델 구성이 실험되었습니다.
- 저자원 레이블링 데이터 평가:
- wav2vec 2.0은 극히 적은 양의 레이블링된 데이터로도 음성 인식의 가능성을 보여주었습니다. 예를 들어, 53k 시간의 레이블링되지 않은 데이터로 사전 훈련하고 단 10분의 레이블링된 데이터만 사용했을 때, Librispeech 테스트 세트에서 4.8/8.2의 WER (Word Error Rate)을 달성했습니다. 10분은 평균 12.5초 길이의 48개 녹음에 해당합니다.
- 1시간의 레이블링된 데이터만 사용했을 때도 이전 최첨단 자기 훈련(self-training) 방법보다 100배 적은 레이블링된 데이터를 사용하여 3.9/7.6의 WER로 더 나은 성능을 보였습니다.
- 100시간 서브셋에서 wav2vec 2.0은 2.3/5.0 WER을 달성하여, 기존 최첨단 방법인 반복적 의사 레이블링(iterative pseudo-labeling) 대비 45%/42%의 상대적 WER 감소를 보였습니다.
- 고자원 레이블링 데이터 평가:
- Librispeech 전체 960시간의 레이블링된 데이터에 미세 조정했을 때, 이 방법은 테스트 세트에서 1.8/3.3의 WER을 달성하며 최고 성능을 보였습니다. 이는 기존의 최첨단 반 자기 지도 방법보다 우수한 결과입니다.
- 모델의 어휘(문자 기반)와 언어 모델(단어 기반)의 어휘가 일치하지 않는 점과 데이터 균형화(data balancing)를 사용하지 않았음에도 불구하고 이러한 결과가 나왔다는 점이 주목할 만합니다.
- TIMIT 음소 인식:
- TIMIT 음소 인식(phoneme recognition) 데이터셋에서 새로운 최첨단 성능을 달성했습니다. 개발/테스트 세트에서 다음으로 좋은 결과 대비 23%/29%의 상대적 PER (Phoneme Error Rate) 감소를 보였습니다.
6. 어블레이션 연구 (Ablation Studies) 이 연구는 잠재 오디오 표현을 대조 손실의 타겟으로만 양자화하고 트랜스포머 네트워크의 입력으로는 양자화하지 않는다는 점에서 이전 작업과 차이가 있습니다. 어블레이션 연구를 통해 이 전략이 가장 좋은 성능을 보임을 확인했습니다.
- 연속 입력과 양자화된 타겟 (Baseline): 가장 좋은 성능을 보였습니다 (7.97 WER). 연속적인 잠재 음성 표현이 더 많은 정보를 유지하여 더 나은 문맥 표현을 가능하게 하며, 타겟 표현의 양자화는 더 견고한 훈련을 이끌어냅니다.
- 양자화된 입력 및 양자화된 타겟: 가장 낮은 성능을 보였습니다 (12.18 WER), 이는 이전 작업의 낮은 성능을 설명합니다.
- 연속 입력 및 연속 타겟: 두 번째로 좋은 성능을 보였지만, 모델이 현재 시퀀스의 세부적인 아티팩트(예: 화자 및 배경 정보)를 포착하여 작업을 쉽게 만들고 음성 인식에 유익한 일반적인 표현을 학습하는 것을 방해하는 것으로 나타났습니다.
- 다른 하이퍼파라미터: 수용장(receptive field) 크기 증가, 다양성 페널티(diversity penalty) 가중치 조정, 부정 샘플(negatives) 수 증가, Gumbel noise 제거 등 다양한 하이퍼파라미터 변경이 성능에 미치는 영향도 분석했습니다. Gumbel noise의 중요성과 부정 샘플링 방식의 영향을 확인했습니다.
7. 결론 및 영향 wav2vec 2.0은 원본 파형의 잠재 표현을 마스킹하고 양자화된 음성 표현에 대한 대조 작업을 해결하는 자기 지도 학습 프레임워크입니다. 이 연구는 레이블링되지 않은 데이터에 대한 사전 훈련이 음성 처리에서 엄청난 잠재력을 가지고 있음을 보여줍니다. 최소한의 레이블링된 데이터만으로도 높은 정확도를 달성할 수 있음을 입증했습니다. 또한, 이 접근 방식은 많은 양의 레이블링된 데이터를 사용할 때도 효과적입니다.
이러한 성과는 수천 개의 언어와 수많은 방언에 대해 현재 음성 인식 기술이 부족한 상황에서, 소량의 주석(annotated) 데이터로도 매우 좋은 정확도로 음성 인식 모델을 구축할 수 있음을 시사합니다. 이는 음성 인식 기술을 더 많은 언어와 방언에 널리 보급하는 데 기여할 것으로 기대됩니다.
'Paper Review' 카테고리의 다른 글
| Hunyuan-A13B 리뷰 (1) | 2025.07.03 |
|---|---|
| "VLRM: Vision-Language Models act as Reward Models for Image Captioning" 논문 리뷰 (3) | 2025.06.15 |
| Convolutional Vision Transformer (CvT) 논문 리뷰 (0) | 2025.06.15 |
| "Training data-efficient image transformers & distillation through attention" DeiT 논문 리뷰 (2) | 2025.06.15 |
| "4M: Massively Multimodal Masked Modeling" 논문 리뷰 (1) | 2025.06.10 |