VLRM: 이미지 캡셔닝을 위한 비전-언어 모델을 보상 모델로 활용
이 논문은 이미지 캡셔닝 모델, 특히 BLIP2를 강화 학습(Reinforcement Learning, RL)과 CLIP 및 BLIP2-ITM과 같은 비전-언어 모델(Vision-Language Models, VLM)을 보상 모델(Reward Model)로 활용하여 향상시키는 비지도 학습(unsupervised) 방식을 제안합니다. 이 방법을 통해 RL로 튜닝된 모델은 더 길고 포괄적인 설명을 생성할 수 있으며, MS-COCO Carpathy Test Split에서 인상적인 0.90 R@1 CLIP Recall 점수를 달성했습니다.
1. 문제점 및 동기
최근 개발된 이미지 캡셔닝 모델들은 인상적인 성능을 보여주었지만, 종종 캡션에 세부 정보가 부족하고 장면에 대한 필수적이고 제한적인 정보만 제공하는 경향이 있습니다. 이러한 문제의 원인은 훈련 데이터에 있습니다. 비지도 학습 및 지도 학습 캡션 모두 주요 객체와 행동에 초점을 맞추는 경향이 있으며, 특정 세부 정보를 생략하거나 관련 정보 전체를 포착하지 못하는 경우가 많습니다.
일부 연구는 대규모 언어 모델(Large Language Model, LLM)을 모델 출력 가이드에 대한 후처리 도구로 적용하여 이 문제를 해결하려고 시도했습니다. 예를 들어, IC3는 여러 캡션을 샘플링한 다음 LLM이 이를 더 자세한 캡션으로 통합하도록 제안했으며, "ChatGPT asks, BLIP2 answers"는 LLM이 초기 캡션을 바탕으로 질문을 하여 더 많은 세부 정보를 추출하도록 합니다. 그러나 이러한 접근 방식은 상당한 계산 오버헤드를 발생시킵니다. 추론 시 기본 모델과 LLM을 동시에 실행해야 하므로 많은 자원이 필요합니다.
최근 LLM의 성능 향상은 주로 세 단계 훈련 절차를 통해 이루어졌습니다. 첫 두 단계는 일반적이며, 첫 단계는 인터넷에서 가져온 대량의 비지도 데이터로 사전 훈련하는 것이고, 두 번째 단계는 인간이 레이블을 지정한 프롬프트-응답 쌍으로 모델을 미세 조정하는 것입니다. 핵심 차이점은 세 번째 단계에 있습니다. 이 단계에서는 강화 학습 기술을 사용하여 보상 모델이 부여한 점수를 최대화하도록 모델을 미세 조정합니다. 보상 모델은 프롬프트와 여러 생성된 출력에 대해 훈련되며, 인간 평가자가 출력을 순위 매긴 데이터가 보상 모델 훈련에 사용됩니다. 이 논문은 이 잘 확립된 RL 기반 미세 조정 접근 방식이 이미지 캡셔닝 작업에도 적용될 수 있는지에 대한 질문에서 시작되었습니다.
2. VLRM 방법론
논문은 사전 훈련된 이미지 캡셔닝 모델을 강화 학습으로 미세 조정하는 새로운 접근 방식을 제시하며, 비전-언어 모델을 즉시 사용 가능한(off-the-shelf) 보상 모델로 활용합니다. 이 방법은 비지도 학습 방식이기 때문에 중요한 장점을 가집니다. 지도 데이터나 어떤 종류의 인간 레이블링 과정도 필요 없으므로 데이터 준비 작업을 크게 단순화하고 고품질 이미지 캡셔닝 모델 훈련 비용을 절감합니다.
주요 장점:
- 비지도 학습: 훈련 중 어떤 종류의 인간이 레이블링한 데이터도 필요하지 않습니다.
- 오버헤드 없음: 추론 시 기본 모델 가중치가 미세 조정된 가중치로 단순히 교체됩니다.
- 고세부 캡션: BLIP2를 기본 모델로 사용하여 MS-COCO 데이터셋 (Karpathy Test Split)에서 0.90 CLIP Recall (R@1)이라는 놀라운 점수를 달성했습니다.
2.1. 훈련 과정 논문은 실험에서 BLIP2 OPT-2.7B를 이미지 캡셔닝 모델로 사용합니다. 훈련 과정은 다음과 같습니다:
- 주어진 이미지에 대해 캡셔닝 모델이 캡션을 생성합니다.
- 비전-언어 모델을 사용하여 (이미지, 캡션) 쌍에 대한 보상(reward)이 계산됩니다.
- 이후 Advantage Actor Critic (A2C) 알고리즘을 사용하여 모델의 가중치가 업데이트되어 더 높은 보상을 생성하도록 합니다. 이 알고리즘의 직관은 "더 자세한 설명이 일반적으로 세부 정보가 적은 설명보다 더 높은 비전-언어 유사성 점수를 산출한다"는 경험적 관찰에 기반합니다. 이 접근 방식은 RLHF와 유사하지만, 차이점은 보상 모델에 있습니다. RLHF의 경우 보상 모델은 인간 선호도를 반영하는 특별한 데이터셋으로 훈련되지만, VLRM은 보상 모델을 훈련하지 않고 사전 훈련된 비전-언어 모델과 휴리스틱(heuristic) 조합을 사용합니다.
2.2. 훈련 가능한 파라미터 훈련 가능한 파라미터는 Q-Former(쿼리 및 언어 프로젝션 포함), 값 헤드(value head), 그리고 LLM의 LoRA 파라미터입니다. 이미지 인코더와 LLM은 고정된 상태로 유지됩니다.
- Q-Former: 107M
- Value head: 275M
- LLM LoRA: 6M
- 총계: 388M 초기에는 단일 완전 연결 계층을 값 헤드로 사용했지만, 이 방식은 일관성 없는 텍스트를 생성하는 문제로 이어졌습니다. 논문은 그림 2에 제시된 더 복잡한 값 헤드 아키텍처를 채택하여 이 문제를 해결했습니다.
2.3. 데이터셋 훈련을 위해 950만 개의 무작위 YouTube 비디오에서 추출한 키프레임을 사용합니다.
2.4. 보상 구성 요소 (Reward Components) 토큰 $t_k$에 대한 할인된 반환(discounted return) $R(t_k)$는 다음 다섯 가지 구성 요소로 이루어집니다:
- sim(image, text): 비전-언어 모델에서 얻은 유사성 점수. 이 구성 요소는 모델이 많은 세부 정보를 포함하는 설명을 생성하도록 보상합니다. BLIP2-ITM 모델 출력의 양의 로짓(logit)이 유사성 점수로 사용됩니다.
- ref(text): 참조 모델로 계산된 혼란도(perplexity)의 로그 값. 이 구성 요소는 텍스트의 자연스러움에 대해 모델에 보상합니다. OPT-2.7B가 참조 모델로 사용되었습니다. 이 구성 요소가 없으면 모델은 인간 관점에서 "기괴하고 부자연스러운 캡션"을 생성합니다.
- bad(s, t1, ..., tn): "an image of", "a youtube video of", 연도("in 1993"와 같은 형식), "a person is talking about "와 같은 무의미한 접두사나 환각(hallucination) 사용에 대한 페널티. 모델은 훈련 중 비전-언어 모델의 점수를 높이는 의미 없는 접두사를 찾아 각 캡션을 시작하는 경향이 있으며, 이는 유용한 정보를 제공하지 않습니다. 또한 모델은 이미지에 있는 연도를 지정하거나 (예: "in 1993") 사람이 대화하는 경우 "a person is talking about "와 같은 환각을 생성하는 경향이 있었습니다.
- repeat(s, t1, ..., tn): 반복되는 단어에 대한 페널티. 예외적으로 색상, 전치사, 관사는 반복되어도 페널티를 주지 않습니다.
- noeos(t1, ..., tn): end-of-sequence 토큰을 생성하지 않은 경우에 대한 페널티.
전체적인 반환($R(t_k)$)은 다음과 같이 계산됩니다: $R(t_k) = sim(text, image) + ref(text) - noeos(t_1, ..., t_n) - \sum_{s \ge k} bad(s, t_1, ..., t_n) - \sum_{s \ge k} repeat(s, t_1, ..., t_n)$
표 1은 $R(t_k)$ 계산의 예를 보여줍니다.

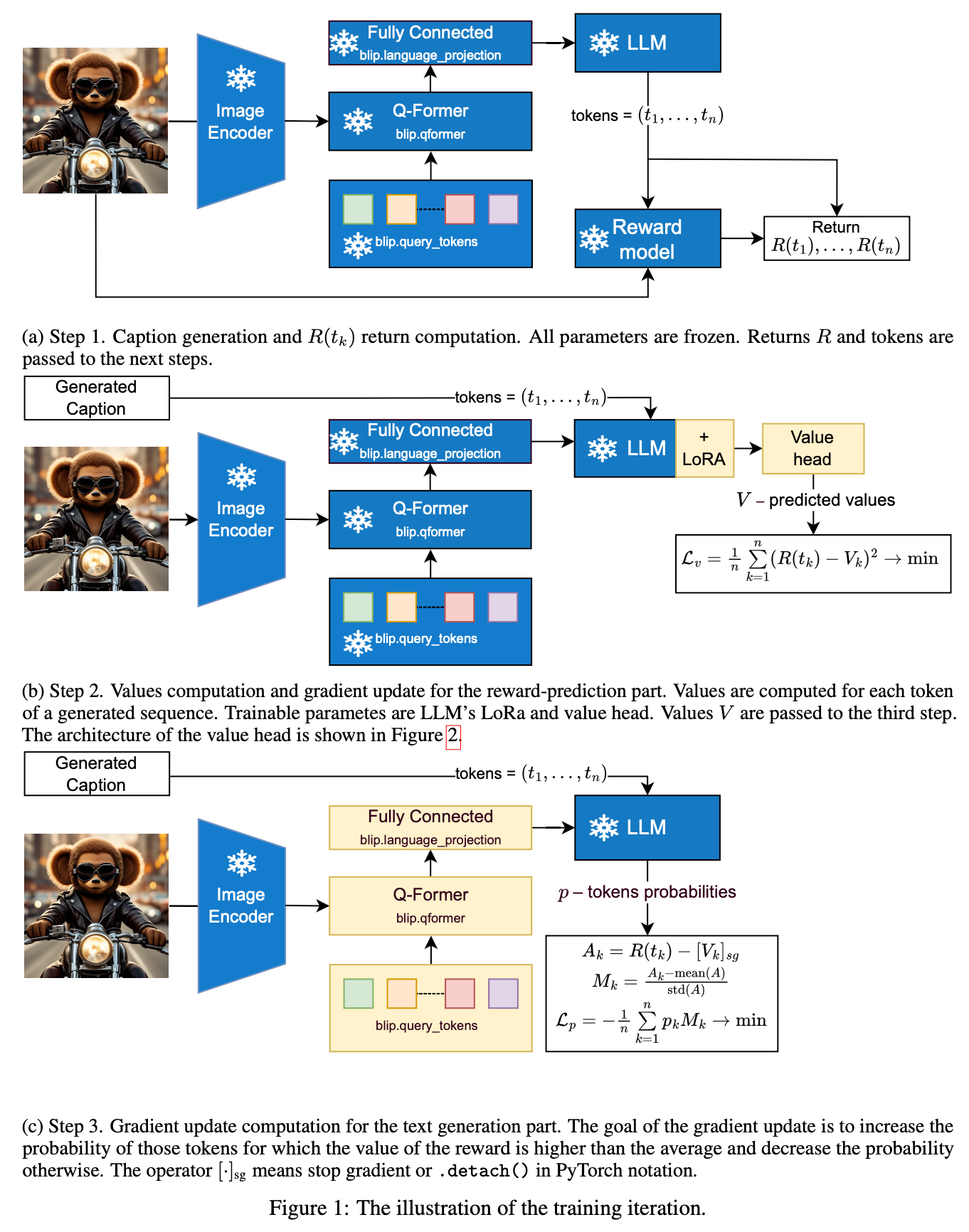
2.5. 훈련 단계 각 훈련 반복은 그림 1에 나타난 세 가지 단계로 구성됩니다:
- 1단계 (그림 1a): 캡션 생성 및 $R(t_k)$ 반환 계산. 주어진 이미지에 대해 캡션(토큰 $t_1, ..., t_n$)을 생성하고, (이미지, 캡션) 쌍에 대한 유사성 점수를 비전-언어 모델에서 얻습니다. 최종적으로 식 (1)을 사용하여 $R(t_k)$를 얻고, 이 반환 값과 생성된 토큰은 다음 단계로 전달됩니다.
- 2단계 (그림 1b): 값 계산 및 보상 예측 부분에 대한 그레이디언트 업데이트. 이 단계에서는 $R(t_k)$에 대한 예상 할인된 반환인 $V_k$(값)를 계산하고, $V_k$가 $R(t_k)$를 더 정확하게 예측하도록 그레이디언트 단계를 수행합니다. 이 단계에서 값을 계산하기 위해 LLM에 훈련 가능한 LoRA 파라미터를 추가합니다. $A_k = R(t_k) - V_k$로 정의되는 '어드밴티지(advantage)'는 세 번째 단계로 전달됩니다.
- 3단계 (그림 1c): 텍스트 생성 부분에 대한 그레이디언트 업데이트 계산. 이 단계에서는 '좋은' 토큰을 생성할 확률 $p_k$를 높이거나 '나쁜' 토큰의 확률을 낮추기 위한 그레이디언트 단계를 수행합니다. '좋음'과 '나쁨'의 개념은 $A_k$의 정규화된 값인 $M_k$를 기반으로 합니다. $M_k = \frac{A_k - mean(A)}{std(A)}$ 손실($L_p$)은 다음과 같습니다: $L_p = - \frac{1}{n} \sum_{k=1}^n p_k M_k \to min$ 직관적으로, $A_k$가 평균보다 훨씬 높으면 토큰 $t_k$의 확률 $p_k$가 증가하고, 평균보다 훨씬 낮으면 감소하며, 평균에 가까우면 확률은 거의 변하지 않습니다.
3. 실험 및 결과
3.1. 훈련 가능한 파라미터 논문은 쿼리 토큰, Q-Former, 언어 프로젝션 부분을 미세 조정하는 것이 가장 좋은 결과를 제공한다고 밝혔습니다. 다른 조합(예: 이미지 인코더에 대한 LoRA, LLM에 대한 LoRA 추가)도 시도되었으나 저자들의 관점에서 더 나쁜 품질로 이어졌습니다.
3.2. 값 헤드 단일 완전 연결 계층을 값 헤드로 사용했을 때, 네트워크는 초기에는 잘 훈련되다가 일정 훈련 단계 후 붕괴되어 일관성 없는 텍스트를 생성하는 문제가 발생했습니다. 그림 2에 제시된 더 복잡한 값 헤드 아키텍처(275M 파라미터)를 채택한 후 이 문제가 해결되었습니다.

3.3. 참조 구성 요소 이 ref(text) 구성 요소는 사람이 읽을 수 있는 캡션을 생성하는 데 필수적입니다. 이 구성 요소가 없으면 모델은 기괴하고 부자연스러운 캡션을 생성하지만, 유사성 점수와 CLIP Recall 지표는 높아지는 경향을 보입니다. BLIP2의 OPT-2.7B를 참조 모델로 사용했을 때 생성된 캡션이 더 자연스럽게 보였습니다. LLaMa-2-7B도 시도되었으나, 그 경우 캡션은 기본 OPT-2.7B 모델보다 품질이 낮았습니다.
3.4. Bad Phrases 페널티 훈련 중 모델은 "an image of", "a video of", "a camera shot of"와 같이 시각-언어 모델이 제공하는 점수를 높이는 의미 없는 접두사를 찾아 캡션을 시작하는 경향이 있었습니다. 또한 이미지 촬영 연도를 지정하거나(예: "in 1993") 사람이 대화하는 상황에서 "a person is talking about "와 같이 실제로는 불가능하거나 모델이 알 수 없는 환각을 생성하는 경향도 나타났습니다. 이러한 원치 않는 생성 경향을 제거하기 위해 Section 3.4에 설명된 bad phrase penalty(나쁜 구문 페널티)가 도입되었습니다. 발견된 나쁜 구문 목록은 표 6에 제시되어 있습니다.

3.5. 결과 모델 논문은 두 가지 모델을 제시합니다:
- VLRM: 주요 결과로 제안된 모델로, 원본 BLIP2와 유사한 스타일이지만 더 많은 세부 정보를 가진 텍스트를 생성합니다.
- VLRM-RS (Retrieval Specialization): 가장 높은 CLIP Recall 값을 얻는 것을 목표로 훈련된 모델입니다.
VLRM과 VLRM-RS의 차이는 $R(t_k)$ 계산 방식에 있습니다. VLRM-RS는 ref(text) 구성 요소 없이 훈련되었고, sim 구성 요소에 CLIP 모델 기반의 합산이 추가되었습니다 (식 5 참조).

성능 비교: MS-COCO Karpathy Test Split에서 VLRM과 VLRM-RS는 원본 BLIP2에 비해 R@1에서 각각 +38.8%와 +41.5%의 상당한 성능 향상을 보였습니다. 표 3은 CLIP Recall 지표를 보여줍니다:

표 4와 5의 예시를 통해 VLRM 모델들이 원본 BLIP2에 비해 훨씬 길고 자세한 설명을 생성하며, 색상 사용 측면에서도 더 활발하게 세부 정보를 포함하는 것을 확인할 수 있습니다. 특히 객체가 여러 색상을 가질 경우 쉼표로 나열하는 속성도 보여줍니다.


4. 결론
이 논문은 강화 학습과 비전-언어 모델을 보상 모델로 사용하여 기존 이미지 캡셔닝 모델을 미세 조정하는 방법인 VLRM을 제안합니다. 이 방법은 인간이 레이블링한 데이터 없이도 생성 품질을 크게 향상시키며, 모든 이미지 캡셔닝 모델에 적용 가능합니다. 논문은 VLRM을 인간 수준의 다중 모달 AI 시스템을 구축하는 중요한 단계로 간주합니다.
'Paper Review' 카테고리의 다른 글
| HyperCLOVA X THINK 리뷰 (1) | 2025.07.03 |
|---|---|
| Hunyuan-A13B 리뷰 (1) | 2025.07.03 |
| wav2vec 2.0 논문 리뷰 (1) | 2025.06.15 |
| Convolutional Vision Transformer (CvT) 논문 리뷰 (0) | 2025.06.15 |
| "Training data-efficient image transformers & distillation through attention" DeiT 논문 리뷰 (2) | 2025.06.15 |