HyperCLOVA X THINK 개요 및 목표
HyperCLOVA X THINK는 HyperCLOVA X 제품군의 첫 번째 추론 중심 대규모 언어 모델입니다. 이 모델은 두 가지 주요 목표를 가지고 개발되었습니다:
- 고급 추론 능력: 사실적 지식 암기를 넘어 논리적 추론 및 다단계 문제 해결 능력을 제공합니다.
- 주권 AI(Sovereign AI) 촉진: 한국어에 특화된 언어적 유창성과 문화적 민감도를 제공하며, 지역적 가치 및 규제에 부합하는 데이터 거버넌스를 목표로 합니다. 특히 한국을 중심 목표로 설정했습니다.
이 모델은 약 6조 개의 고품질 한국어 및 영어 토큰으로 사전 학습되었으며, 표적 합성 한국어 데이터로 보강되었습니다. 또한 컴퓨팅-메모리 균형을 이루는 Peri-LN Transformer 아키텍처를 µP 스케일링과 함께 사용하여 구현되었습니다.
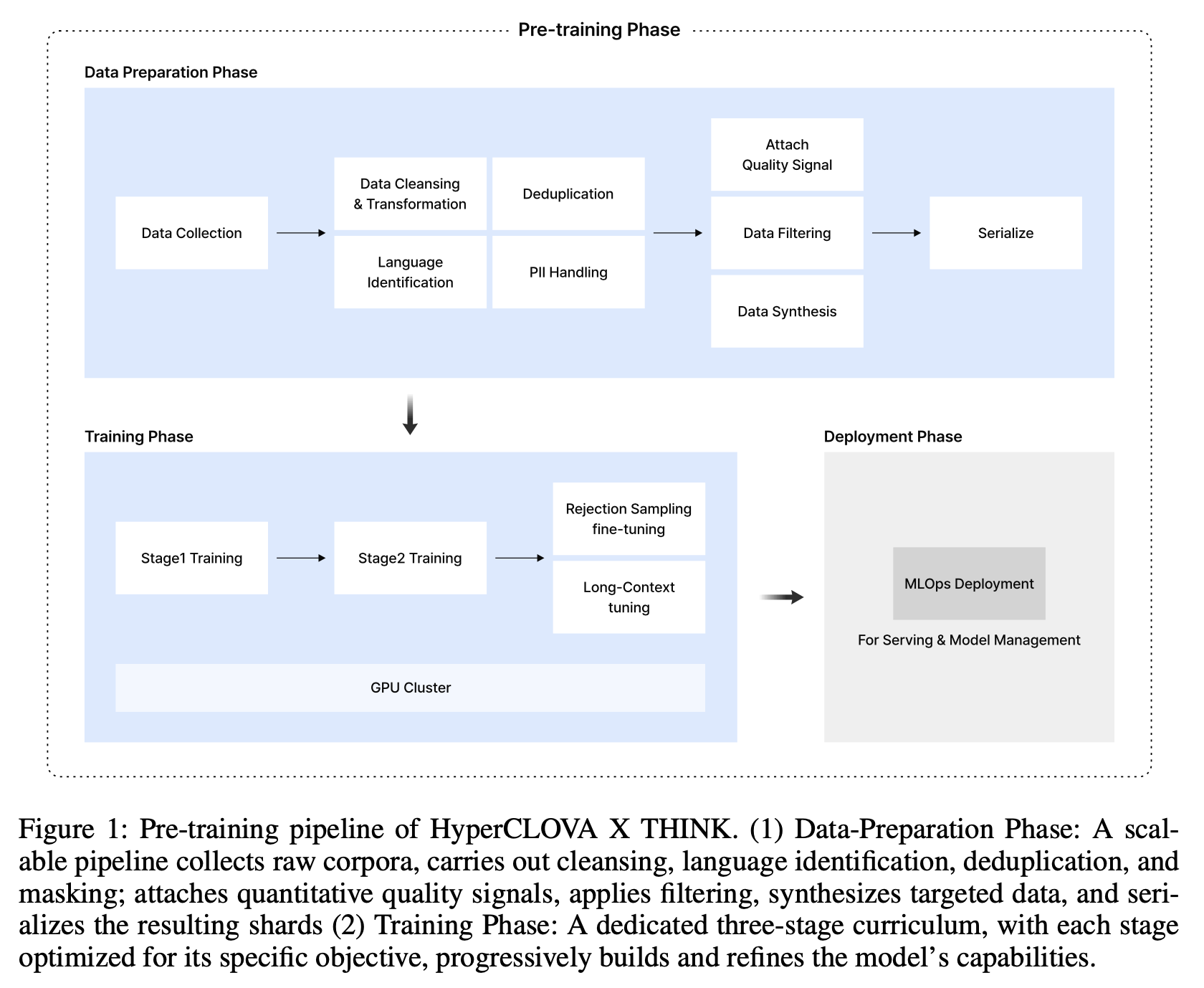
사전 학습 방법론
THINK의 사전 학습은 다음과 같은 주요 요소들을 포함합니다:
- 데이터 준비 (Data Preparation):
- 규모 및 품질: 약 6조 개의 토큰으로 구성된 말뭉치는 고품질 한국어 및 영어 텍스트와 표적 합성 한국어 데이터의 균형을 이룹니다. 이는 언어적 폭을 넓히면서 문화 및 도메인 관련성을 유지하는 데 도움이 됩니다.
- 데이터 파이프라인: 확장성, 재사용성, 빠른 갱신을 목표로 설계되었으며, 스키마 표준화와 품질 평가 및 필터링이 분리되어 있습니다. 원시 문서는 경량화된 정제, 필드명 표준화, 통합 스키마 저장을 거치며, 이후 구조적 및 언어적 지표를 포함한 정량적 품질 신호가 첨부되고 개인 식별 정보(PII)가 마스킹됩니다. 필터링 단계에서는 임계값 규칙이 적용되어 최적화된 샤드 파일로 직렬화됩니다.
- 한국어 특화 데이터 필터링: 폭넓고 신뢰할 수 있는 고품질 말뭉치를 얻기 위해 한국어의 언어적, 타이포그래피적 특성에 맞춘 2단계 필터링 프레임워크를 사용합니다.
- 1단계: Weber et al. (2024b) 및 Lozhkov et al. (2024)의 규칙 세트를 확장하여 한국어 형태론에 맞게 재설계되었습니다. 기호-단어 비율, 평균 단어 길이, 문장 수, 마스킹된 PII 비율, 정규화된 길이 대 원시 길이 비율 등 5가지 대표적인 정량적 신호가 각 문서에 대해 계산됩니다.
- 2단계: FastText 및 트랜스포머 인코더를 사용하여 모델 기반 점수 매김을 수행합니다. 바이너리(binary) 방식에서는 위키와 유사한 구절이 긍정적 예시로, 노이즈가 많은 웹 페이지가 부정적 예시로 사용되며, 순 확률(posterior probability)이 연속적인 품질 점수를 제공합니다. 순서형(ordinal) 방식에서는 언어 모델이 교육적 유용성, 정보성, 서술적 일관성에 대해 0-5점 등급을 할당합니다.
- 합성 데이터 생성: 영어와 같은 주요 언어에 비해 고품질 한국어 말뭉치가 부족한 점을 해소하기 위해 교육, 법률, 역사적 사실, 문화적 감정 등 한국어 콘텐츠가 특히 부족한 영역에 중점을 두고 고품질 합성 데이터 생성 프로그램을 시작했습니다. 이 과정은 기존 문서 재작성 및 큐레이션된 시드 프롬프트에서 새로운 텍스트를 생성하는 두 가지 상호 보완적인 트랙을 따르며, 필터링 및 검증을 핵심으로 합니다. 4단계 워크플로우(데이터 설계, 시드 획득 및 생성, 필터링 및 정제, 통합)를 통해 고품질의 합성 데이터를 사전 학습 말뭉치에 주입합니다.
- 모델 아키텍처 (Model Architecture):
- 컴퓨팅-메모리 균형 Transformer: 고정된 매개변수 예산 내에서 컴퓨팅 집약적 학습 비용과 메모리 집약적 추론 지연 시간을 최소화하기 위해 얕고 넓은(shallower-but-wider) Transformer 구성을 채택했습니다. 이는 블록 수를 줄이고 확보된 매개변수를 더 큰 은닉 및 피드포워드 차원에 재할당하여 이루어지며, 학습 토큰 처리량을 15% 증가시키면서도 모델링 품질을 유지합니다.
- 안정성 지향 Transformer: Maximal Update Parametrization(µP)과 Peri-Layer Normalization(Peri-LN)을 결합하여 스케일업 안정성을 확보합니다. µP는 작은 프록시 모델에서 학습률과 정규화 설정을 조정한 후 이를 대규모 모델에 제로샷(zero-shot)으로 이식할 수 있게 하여, 탐색 비용을 크게 줄입니다. Peri-LN은 모든 Transformer 서브레이어의 입력 및 출력을 정규화하여 은닉 상태 분산의 선형 성장을 제한하고 레이어별 기울기 노름(gradient norm)을 안정적으로 유지합니다. Peri-LN 모델은 Pre-LN 모델보다 더 적은 기울기 및 손실 스파이크를 보이며, 동일한 학습 시간 예산 내에서 평균적으로 15% 더 낮은 학습 손실을 달성합니다.
- 사전 학습 커리큘럼 (Pre-Training Curriculum):
THINK는 세 단계로 구성된 사전 학습 커리큘럼을 채택하여 각 단계마다 특정 역량 목표에 중점을 둡니다.- 1단계: 기초 지식 구축 (Foundational Knowledge Construction): 다수의 도메인에 걸쳐 광범위한 지식 기반을 구축합니다. 주로 한국어와 영어로 구성된 다국어 말뭉치로 최대 8K 토큰 길이의 시퀀스를 사용하여 총 6조 개의 토큰을 소비하며 학습이 진행됩니다.
- 2단계: 도메인 특화 능력 향상 (Domain-Specialized Capability Boosting): 추가로 1조 개의 토큰을 도입하여 모델의 도메인 전문 지식과 추론 능력을 강화합니다. 일반 웹 텍스트의 가중치를 점진적으로 낮추고, 2.1절에서 구축된 합성 데이터를 포함한 고품질 도메인 집중 말뭉치의 비중을 늘립니다.
- 3단계: 확장된 컨텍스트 정렬 (Extended Context Alignment): 컨텍스트 윈도우를 128K 토큰까지 확장하고 긴 사고 사슬 추론을 내재화합니다. 이를 위해 길이 기반의 비율 유지 리샘플링과 내부적으로 생성되고 거부 샘플링으로 필터링된 긴 사고 사슬 말뭉치로 추가 학습을 진행합니다.

사후 학습 방법론
THINK의 사후 학습은 슈퍼바이즈드 파인튜닝(SFT)과 다단계 강화 학습 파이프라인으로 구성됩니다. 이 모델은 상세한 '추론 모드'와 간결한 '비추론 모드' 사이를 동적으로 전환할 수 있도록 통합된 방식으로 학습되었습니다.
- 슈퍼바이즈드 파인튜닝 (Supervised Fine-Tuning, SFT):
- 기초 행동 주입: 모델에 원하는 행동과 추론 패턴을 주입하는 기초 단계입니다.
- 데이터셋: 수학, 코딩, STEM, 일반 능력 등 다양한 소스에서 데이터를 수집하여 구성됩니다. 추론 데이터의 경우, 각 샘플에는 프롬프트, 어시스턴트 씽크(자유 형식의 추론 사슬), 그리고 어시스턴트 응답(추론을 기반으로 한 간결한 최종 출력)이 포함됩니다.
- 데이터 품질 및 일관성: 다단계 필터링 파이프라인을 적용하여 출력 형식 확인, 언어 필터링 및 언어 일치 검사를 수행합니다. 추론 데이터의 경우 최종 답변의 자동 검증 가능성도 확인하며, 비추론 데이터의 경우 LLM-as-a-Judge 방식을 사용하여 유용성과 안전성 점수가 낮은 샘플을 필터링합니다.
- 검증 가능한 보상 기반 강화 학습 (Reinforcement Learning with Verifiable Rewards, RLVR):
- 목표: 검증 가능한 피드백 메커니즘을 통해 추론 능력을 향상하고 정확한 보상 및 벌칙을 통해 모델 성능을 최적화하는 것이 주 목적입니다.
- 강화 학습 알고리즘: Group Relative Policy Optimization (GRPO)를 채택합니다.
- KL Divergence Penalty 제거: 탐색을 제한하고 연산 오버헤드를 유발하여 제거했습니다.
- 상수 정규화: 응답 길이 및 프롬프트 난이도와 관련된 편향을 완화하기 위해 적용되었습니다.
- 탐색을 위한 완화된 상한선: clip-higher 접근 방식을 채택하여 정책 엔트로피를 높이고 다양한 추론 경로를 촉진합니다.
- 데이터 효율성: 오프라인 및 온라인 난이도 필터링 기법을 사용하여 학습 효율성을 최적화합니다.
- 오프라인 필터링: 너무 쉽거나 너무 어려운 프롬프트를 제외하여 적절한 난이도 수준의 프롬프트만 포함되도록 합니다.
- 온라인 필터링: GRPO를 사용하여 각 배치에서 모든 생성된 응답이 완전히 옳거나 완전히 틀린 프롬프트를 제거하여, 모델의 진화하는 능력에 따라 학습 세트의 난이도를 지속적으로 조정합니다.
- 보상 형성 (Reward Shaping):
- 형식 보상 (Format Reward): 응답이 따라야 할 형식 규칙의 준수 정도에 따라 계산됩니다.
- 언어 보상 (Language Reward): 프롬프트와 동일한 언어로 생성된 문자의 비율을 기반으로 계산되어 다국어 추론 능력을 향상시킵니다.
- 검증 가능한 보상 (Verifiable Reward): 수학, 코드 생성, 코드 입출력(Code IO), 객관식 문제 등 여러 문제 범주에 걸쳐 적용되며, 검증 결과에 따라 이진 값(1.0 또는 0.0)으로 할당됩니다.
- 과도한 길이 보상 (Overlong Reward): Soft Overlong Penalty와 Overlong Loss Masking을 사용하여 응답 길이가 미리 정의된 최대값을 초과할 때 점진적으로 증가하는 벌칙을 적용하고, 잘린 샘플의 손실을 마스킹하여 학습 안정성을 확보합니다.
- 최적화된 롤아웃 샘플링 프로세스: 비동기 샘플링 절차를 구현하여 추론 노드를 지속적으로 동시에 활용함으로써 유휴 시간을 줄이고 자원 활용도를 높입니다. 온라인 난이도 필터링으로 인해 샘플이 필터링될 수 있는 지연을 상쇄하기 위해 버퍼링된 동시 샘플링 접근 방식을 유지합니다.
- 추론 길이 제어 가능성 (Reasoning Length Controllability, LC):
- 필요성: 대규모 추론 모델(LRM)이 복잡한 추론 능력을 크게 향상시키지만, 최적의 추론 길이에 비해 과도하게 생각하거나(overthink) 부족하게 생각하는(underthink) 경향을 보이는 경우가 많아 길이 제어 가능성이 중요합니다.
- 구현: Aggarwal and Welleck (2025)에서 도입된 길이 페널티 보상 함수(L1-Exact 및 L1-Max)를 추가로 통합합니다. 입력 지시에 'Think for maximum N tokens'를 추가하여 N을 이산 토큰 예산 집합에서 샘플링합니다. L1-Exact 페널티로 약 300단계 학습 후 L1-Max 페널티로 약 100단계 학습하여 길이 제어 능력을 획득하고 가능한 한 추론 길이를 줄입니다.
- 인간 피드백 기반 강화 학습 (Reinforcement Learning from Human Feedback, RLHF):
- 목표: 모델 출력을 인간 선호도 및 실제 사용 가능성과 일치시킵니다. 추론/비추론 RLHF와 RLVR을 결합하여 모델 행동을 동시에 개선합니다.
- 훈련: 인간 선호도 데이터(전문 평가자가 주석을 달거나 내부 평가 모델의 점수로 추론)를 사용하여 보상 모델을 먼저 학습합니다. 그런 다음 GRPO를 핵심 RLHF 알고리즘으로 사용하여 보상 모델이 예측한 기대 보상을 최대화하도록 정책을 최적화합니다. RLVR과 달리, SFT 체크포인트에 근접성을 유지하기 위해 0.1의 KL 페널티를 적용합니다.
- 동시 학습: RLHF 학습 후 RLVR 단계에서 최적화된 모델의 추론 능력이 약간 저하되는 현상을 해결하기 위해, RLVR과 RLHF가 동시에 학습되도록 학습 배치를 섞는 공동 학습 전략을 채택합니다.
평가 및 성능
HyperCLOVA X THINK는 유사한 크기의 기존 모델에 비해 상당히 낮은 학습 컴퓨팅 자원으로 경쟁력 있는 성능을 제공합니다.
- 한국어 중심 벤치마크:
- 일반 능력: KMMLU, CSAT, KorMedMCQA, KoBALT-700 벤치마크에서 평가되었으며, 전반적으로 다른 모델들을 능가하는 성능을 보였습니다.
- 문화 및 언어: HAERAE-1.0, CLIcK, KoBigBench에서 한국어 특화 문화, 지리, 역사 지식 등을 평가했으며, 뛰어난 성능을 입증했습니다.
- 명령어 추종: LogicKor 및 KoMTBench에서 한국어 명령어를 따르는 모델의 능력을 측정했으며, 역시 우수한 결과를 보였습니다.
- 수학 및 코딩 벤치마크: GSM8K, MATH500, HumanEval, MBPP와 그 한국어 버전에서 평가되었으며, 다른 기준 모델들과 유사한 성능을 보였습니다.
- 학습 효율성:
- THINK는 고효율 아키텍처와 고품질 데이터를 기반으로 한 학습 전략으로 개발되었으며, 그 결과 유사한 크기의 모델보다 상당히 적은 GPU 시간이 소요되었습니다. 이는 전략적인 데이터 큐레이션과 학습 효율성이 고성능 LLM 개발에 중요하며, 단순한 자원 투입을 넘어선다는 것을 보여줍니다.
- 교차 언어 전이성 (Cross-Lingual Transferability):
- 교차 언어 일관성: 병렬 영어-한국어 MCQA 예측 결과에 대한 모델의 예측을 네 가지 경우(✓,✓), (✓,✗), (✗,✓), (✗,✗)로 분류하여 평가했습니다. THINK는 광범위하게 학습된 Qwen3 32B 모델보다 몇 점 뒤처지지만 74.5%의 (✓,✓) 비율을 달성하며 비대칭 오류를 16.5%로 제한했습니다. 이는 목표 지향적인 이중 언어 학습이 대규모 다국어 모델의 스케일 이점을 상당 부분 상쇄할 수 있음을 나타냅니다.
- 기계 번역: Flores 벤치마크를 사용하여 한국어-영어 양방향 기계 번역 성능을 xCOMET-XL로 측정했습니다. THINK는 한국어-영어 방향에서 90.3의 경쟁력 있는 xCOMET 점수를 달성했으며, 영어-한국어 방향에서는 85.8점으로 모든 다른 모델을 능가했습니다. 이는 THINK의 학습 파이프라인이 영어 지식을 보존할 뿐만 아니라 고품질 한국어로 번역하는 모델의 능력을 향상시킨다는 것을 보여줍니다.
- 비전 증강 변형:
- 비전 인코더를 통합한 비전 증강 변형은 KCSAT STEM 벤치마크에서 GPT-4.1과 같거나 능가하는 성능을 보여주었습니다. 이는 THINK가 텍스트 기반 추론에 최적화되었음에도 불구하고 시각 모달리티로 효과적으로 확장될 수 있음을 입증합니다. 특히, 추론 모드를 비활성화하면 성능이 21.7%로 크게 떨어지는데, 이는 언어 사전 학습 중에 습득한 고급 추론 기술이 시각 중심 STEM 문제에 효과적으로 확장될 수 있음을 시사합니다.
확장 및 향후 계획
- 비전-언어 추론 도입: THINK는 원래 텍스트에서 고급 추론을 위해 개발되었지만, 전용 다중 모달 사후 학습 파이프라인을 통해 비전 기반 추론으로 효과적으로 확장될 수 있음을 보였습니다. KCSAT STEM과 같은 한국어 교육 테스트에서 모델의 비전-언어 추론 능력을 평가했습니다. 이 평가는 시각적 이해와 추상적 문제 해결의 통합 과정을 포함하며, SigLIP-2 비전 인코더와 LLaVA-1.5-HD 기반 프레임워크를 사용했습니다.
- 가지치기(Pruning) 및 증류(Distillation): 논문은 가지치기 및 지식 증류 기술을 THINK에 적용하여 매개변수 수를 줄이면서 정확도를 유지하는 방법을 소개합니다. 이 기술은 제한된 자원 환경에 적합한 모델을 생산할 수 있게 합니다. 실제로 HyperCLOVA X SEED 0.5B는 이 기술을 사용하여 유사한 크기의 다른 모델보다 훨씬 낮은 비용으로 학습되었음에도 불구하고 대부분의 벤치마크에서 뛰어난 성능을 보였습니다. THINK의 가지치기 및 증류 버전은 곧 오픈 소스로 출시될 예정이며, 이는 학술 및 산업 파트너에게 이점을 제공하고 주권 LLM의 미래 개발 및 활용을 촉진할 것입니다.
결론
HyperCLOVA X THINK는 HyperCLOVA X 제품군의 첫 번째 추론 중심 LLM으로, 고급 추론 능력과 한국을 위한 주권 AI 촉진이라는 두 가지 주요 목표를 효율적으로 달성하기 위해 학습되었습니다.
이 모델은 약 6조 개의 고품질 한국어 및 영어 토큰과 표적 합성 한국어 데이터로 구성된 사전 학습 데이터셋을 활용합니다. 컴퓨팅-메모리 균형을 이루는 Peri-LN Transformer와 µP를 사용하여 안정적인 확장성과 비용 효율적인 학습을 보장합니다. 3단계 커리큘럼은 모델이 128K 토큰으로 컨텍스트 윈도우를 확장하고 강력한 긴 사고 사슬 추론을 수행할 수 있도록 합니다. 사후 학습은 슈퍼바이즈드 파인튜닝과 검증 가능한 보상 기반 강화 학습을 포함하며, 상세한 추론 및 간단한 답변 작업 모두를 처리하는 큐레이션된 데이터 필터링 프로세스를 활용합니다.
실험 결과, HyperCLOVA X THINK는 KMMLU, CSAT, KoBALT-700, HAERAE-1.0, KoBigBench와 같은 한국어 중심 벤치마크에서 다른 추론 모델들과 경쟁력 있는 성능을 보여줍니다. 분석 결과, 모델의 매우 효율적인 학습 비용과 강력한 이중 언어 일관성이 강조됩니다. 또한, 비전 증강 변형은 KCSAT STEM 벤치마크에서 GPT-4.1에 필적하는 성능을 달성했습니다.
이 논문은 모델 응답을 개선하기 위해 테스트 시 추가 컴퓨팅을 사용하는 것이 모델 능력의 한계를 확장하고 컴퓨팅-비용 효율성을 향상시키는 효과적인 방법임을 보여줍니다. NAVER AI 윤리 가이드라인에 따라 안전 조치를 취했지만, 생성된 텍스트의 무해성은 완전히 보장될 수 없으므로 독성 발언, 편향 또는 유해한 콘텐츠가 포함될 수 있음을 명시합니다. 그러나 책임 있는 AI 개발 및 배포를 위해 지속적으로 노력할 것을 약속합니다.
'Paper Review' 카테고리의 다른 글
| SpeechSSM 논문 리뷰 (1) | 2025.07.06 |
|---|---|
| "Self-Adapting Language Models (SEAL)" 논문 리뷰 (1) | 2025.07.04 |
| Hunyuan-A13B 리뷰 (1) | 2025.07.03 |
| "VLRM: Vision-Language Models act as Reward Models for Image Captioning" 논문 리뷰 (3) | 2025.06.15 |
| wav2vec 2.0 논문 리뷰 (1) | 2025.06.15 |