1. 서론 및 연구의 목적
이 논문 "Long-Form Speech Generation with Spoken Language Models" (Se Jin Park 외)는 수 분에 걸친 긴 길이의 음성 생성 모델링을 다룹니다. 이는 긴 형식의 멀티미디어 생성 및 오디오 기반 음성 비서와 같은 애플리케이션에 필수적인 요구사항입니다. 현재의 음성 언어 모델들은 수십 초 이상의 그럴듯한 음성을 생성하는 데 어려움을 겪고 있으며, 이는 음성 토큰의 높은 시간 해상도로 인한 일관성 손실, 긴 시퀀스 학습 또는 외삽(extrapolation)과 관련된 아키텍처 문제, 그리고 추론 시 메모리 비용 등 여러 가지 이유 때문입니다. 이러한 문제를 해결하기 위해 이 논문은 선형 시간 시퀀스 모델링의 최신 발전을 기반으로 한 SpeechSSM을 제안합니다. SpeechSSM은 텍스트 중간 매개체 없이 단일 디코딩 세션에서 16분 길이의 음성 오디오를 학습하고 샘플링할 수 있는 최초의 음성 언어 모델입니다.
2. 기존 음성 언어 모델의 한계 및 과제
생성형 음성 언어 모델(Generative Spoken Language Models, GSLM)은 가역 오디오 표현의 자기회귀(AR) 모델로, 지능적인 음성과 운율, 차례 바꾸기 등과 같은 부수 언어적 측면을 직접 학습하고 생성할 수 있게 합니다. 그러나 실제 사용 사례에서는 긴 형식의 오디오를 이해하고 생성하는 능력이 요구됩니다. 예를 들어, 음성 상호 작용은 수 분 동안 지속될 수 있으며, 모델이 실시간으로 증가하는 대화 기록을 유지해야 합니다.
이러한 긴 형식 오디오는 기존 음성 언어 모델에 상당한 도전 과제를 제시합니다:
- 복잡한 음성 오디오: 음성 오디오는 텍스트의 의미론적 내용이 부수 언어적 내용 및 음향적 특성과 얽혀 있어, 고수준 음성 특징 학습을 방해할 수 있습니다.
- 높은 시간 해상도의 오디오 표현: 음성 단어의 지속 시간을 다루는 데 10개 이상의 음성 토큰이 필요할 수 있습니다. 따라서 모델은 더 긴 시간 범위에 걸쳐 의미론을 유지하고 통합해야 하며, 동일한 시간 범위에 걸쳐 일관된 내용을 생성해야 합니다.
- Transformer 아키텍처의 한계: 바닐라 Transformer는 프롬프트 길이에 따라 비용이 2차적으로 증가하고, 디코딩 길이에 따라 단계별 비용이 선형적으로 증가하여 긴 범위 의존성 작업에서 성능이 저조합니다.
- 평가 방법의 부족: 긴 형식 음성 생성의 참신성 때문에, 이러한 생성물에 대한 분석 및 평가는 지금까지 연구되지 않았습니다.
3. SpeechSSM 제안 및 주요 설계
이 연구는 긴 형식 음성 생성 문제를 해결하기 위해 SpeechSSM을 제안합니다. SpeechSSM은 특히 긴 형식 생성을 위해 설계된 새로운 (텍스트 없는) 음성 언어 모델입니다. 이 모델은 유한한 메모리 내에서 무한한 긴 형식 음성을 모델링하고 생성하는 최초의 모델이며, 또한 최초의 상태 공간 음성 LM입니다.
SpeechSSM은 일반적이고 무한한 음성 생성 시스템을 위한 다음 요구 사항을 충족하도록 설계되었습니다:
- 디코딩 중 일정한 메모리: 메모리 부족 없이 무기한 자기회귀 샘플링을 가능하게 합니다.
- 무한 컨텍스트: 임의로 멀리 떨어진 의존성을 (이론적으로) 표현할 수 있습니다. 이를 위해 필요한 과거 컨텍스트는 고정된 크기의 상태에 맞아야 합니다.
- 생성 길이 외삽: 특히 학습 시 보지 못한 오디오 지속 시간을 넘어 시간 경과에 따라 음성 품질이 일관되게 유지되어야 합니다.
- 효율적인 학습: 긴 시퀀스를 가능하게 하고 외삽에 대한 의존도를 줄이기 위해 시퀀스 길이에 대한 학습 시간 의존성이 2차 미만이어야 합니다.
이를 위해 SpeechSSM은 하이브리드 상태 공간 모델을 채택했습니다.
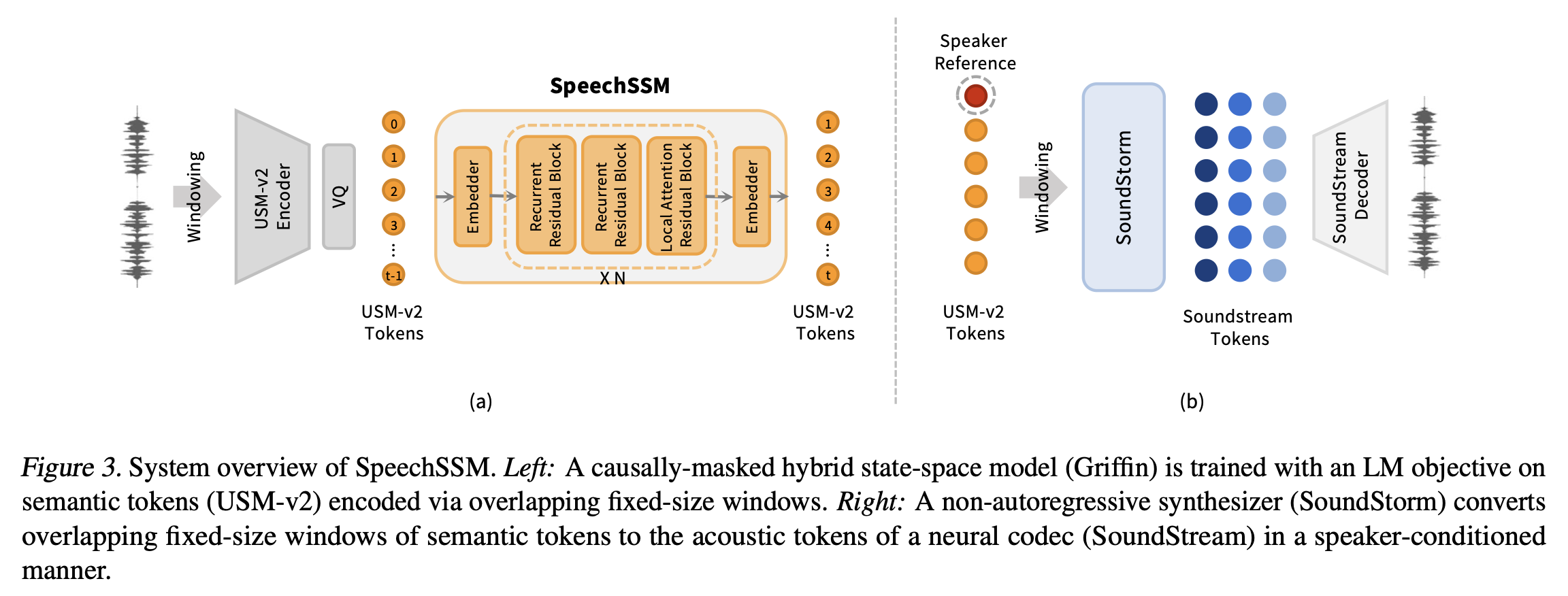
주요 설계 선택 사항은 다음과 같습니다:
- 아키텍처: Griffin (De et al., 2024)을 디코더 전용 하이브리드 SSM으로 사용합니다. 이는 게이트형 LRU(Linear Recurrent Units)와 로컬(슬라이딩 윈도우) 다중 쿼리 어텐션(MQA) 블록을 특정 패턴으로 교차시킵니다. 로컬 어텐션은 최근 컨텍스트를 효율적으로 포착하고, 게이트형 재귀 상태는 임의의 거리에 걸쳐 정보를 전달합니다.
- 초기화: RecurrentGemma-2B IT 모델로 초기화하여 텍스트 초기화된 음성 언어 모델의 성공을 따릅니다.
- 의미론적 토큰화(Semantic Tokenizer): 사전 학습된 USM-v2 음성 토크나이저를 사용하여 의미론적 토큰을 생성합니다. USM-v2는 가장 화자 불변(speaker-invariant)적인 토큰 중 하나로 나타났습니다.
- 의미론-음향 생성(Semantic-to-Acoustic Generation): SpeechSSM에서 출력된 의미론적 토큰을 조건으로 하는 SoundStorm 모델을 사용하여 SoundStream 토큰을 비자기회귀적으로 생성합니다. 이는 화자 특성을 음향 단계로 분리하여 SpeechSSM이 시간 축을 따라 의미론적 일관성을 모델링하는 데 집중할 수 있게 합니다.
- 윈도우 기반 토큰화 및 디코딩: 긴 형식의 음성을 처리하면서 의미론적 토크나이저 및 음향 디코더의 메모리 요구 사항을 제한하기 위해 겹치는 윈도우 방식을 사용합니다. 오디오를 30초 세그먼트로 나누고 4초 겹침을 적용하여 토큰화 및 디코딩을 수행합니다.
- 묵시적 EOS(End-of-Sequence) 방지: EOS 토큰으로 훈련하지 않으며, 마지막 윈도우를 예시의 시작 부분 음성으로 패딩하여 "묵시적 EOS"를 방지했습니다.
4. 개선된 음성 LM 평가 방법
논문은 기존 음성 생성 평가 지표들이 노이즈가 많고 변별력이 떨어진다고 지적하며, 새로운 긴 형식 평가 방법을 제안합니다.
- LibriSpeech-Long 벤치마크: 긴 형식 음성 생성을 위한 새로운 벤치마크로, 기존 LibriSpeech 데이터셋의 원시 오디오 파일에서 파생됩니다. 4분 길이의 발화로 재처리되어, 긴 프롬프트와 긴 참조를 기반으로 한 평가를 가능하게 합니다.
- 임베딩 기반 의미론적 지표 (Semantic Similarity): 생성된 음성의 전사(transcription)와 참조 전사의 의미론적 임베딩 간의 거리를 측정합니다. 짧은 형식에서는 Sentence-BERT를, 긴 형식에서는 Gecko (Lee et al., 2024)를 사용합니다.
- LLM 기반 평가 (LLM-as-a-Judge): LLM(거대 언어 모델)을 사용하여 자동화된 평가를 수행하며, 특히 사이드 바이 사이드(side-by-side) 평가를 제안합니다. 이는 ASR 문제로 인한 노이즈를 완화하고, 프롬프트와 연속 부분을 함께 전사하여 LLM이 대비에 집중하도록 돕습니다.
- 시간에 따른 품질 측정:
- MOS-T (Mean Opinion Score over Time): 디코딩 과정에 따라 계층화된 음향 지표를 계산하기 위해, 각 분에서 5초 길이의 샘플을 추출하여 음성의 자연스러움을 평가합니다.
- SC-L (Semantic Coherence over Length): 시간에 따른 원본 프롬프트에 대한 의미론적 충실도를 평가하기 위해, 각 연속 전사를 200단어 스팬으로 나누어 프롬프트 임베딩과의 코사인 유사도를 측정합니다.
5. 실험 결과 및 논의
5.1. 단편 형식 연속 생성 (7초 연속 / 3초 프롬프트)
- 화자 유사도(SpkrSim): SpeechSSM과 SpeechTransformer의 연속 음성은 프롬프트와 가장 높은 화자 유사도를 보였습니다. 이는 화자 프롬프트가 가능한 음향 단계를 사용하는 이점 때문으로 분석됩니다.
- 자연성 평균 의견 점수(N-MOS): SpeechSSM의 자연성은 비교 가능한 Transformer와 비슷하거나 더 좋으며, 실제 음성에 매우 가깝습니다. 이는 USM-v2의 큰 어휘(32k)와 SoundStream으로의 전환 덕분입니다.
- sWUGGY 및 sBLiMP: SpeechSSM의 sWUGGY 점수는 훨씬 나빴고, sBLiMP 점수는 중간에서 평균 이상이었습니다. 이는 이러한 탐색 작업이 어휘 크기에 매우 민감하며, 큰 어휘에서 노이즈가 증가할 수 있음을 시사합니다.
- 전사 혼란도(Transcript PPL): SpeechSSM은 가장 낮은 전사 혼란도를 보였지만, 이 지표는 모델 반복성을 나타낼 수 있어 주의가 요구됩니다.
- 제안된 NLG 지표 (SBERT, Win%vs. model): SBERT 점수는 SpeechSSM의 연속이 실제 연속과 (약간) 더 의미론적으로 가깝다는 것을 보여줍니다. 사이드 바이 사이드 평가에서는 SpeechSSM이 가장 좋은 모델(Spirit LM)에 비해 17%의 승률을 기록했습니다. 이는 LLM 기반 평가가 콘텐츠에 초점을 맞춰 더 변별력이 높음을 시사합니다.
5.2. 긴 형식 연속 생성 (4분 / 16분 연속 / 10초 프롬프트)
- 화자 유사도: SpeechTransformer와 SpeechSSM의 화자 유사도는 단편 형식 설정(0.79)에서 0.89로 증가했으며, 이는 더 긴 프롬프트와 연속에 대한 자신감 증가 때문입니다. 다른 모든 모델은 시간이 지남에 따라 화자 발산으로 인해 화자 유사도가 감소했습니다.
- 전사 혼란도 및 Win Rate: SpeechSSM은 가장 좋은 전사 혼란도를 달성하고 다른 모든 모델에 비해 우세했습니다. 16분 연속 평가에서는 SpeechSSM과 Transformer 기준 모델 간의 격차가 더욱 벌어졌는데, 이는 긴 형식 모델링에서 SSM 기반 아키텍처의 우위를 시사할 수 있습니다.
- Ground Truth 대비 Win Rate: 모든 모델이 실제 데이터에 비해 효과적으로 0%의 승률을 보였습니다. 이는 생성 길이가 증가함에 따라 유창성, 일관성, 논리성 및 흥미성의 결함이 점점 더 분명해지기 때문이며, 긴 형식 음성 생성에 대한 새로운 어려운 벤치마크임을 보여줍니다.
- 시간에 따른 외삽 (MOS-T, SC-L):
- MOS-T: GSLM 및 TWIST는 첫 1분부터 음향 품질이 낮았고, Spirit LM은 더 느리게 저하되었습니다. SpeechSSM은 4분 동안 지능적이고 (느슨하게) 일관된 음성을 생성하며 음향 품질을 유지했습니다.
- SC-L: 다른 비교 모델들은 약 200단어(약 1분, 학습 길이 주변)에서 의미론적 일관성(SC) 점수가 급격히 떨어지고 그 이후 평준화됩니다. 반면, SpeechSSM은 생성 후반부까지 높은 SC를 유지하며, 4분 사례에서는 실제 데이터에 가장 가깝습니다.
- 학습 길이 초과 일반화: SpeechSSM-4m이 16분 평가를 받을 때 성능 저하가 거의 없어 학습 길이를 가장 잘 일반화합니다.
5.3. 샘플링 효율성
- 처리량(Throughput): SpeechSSM은 Transformer와 달리 상수 크기 상태를 유지하는 재귀 레이어로 인해 더 높은 처리량을 달성합니다. 특히 16k 토큰 시퀀스를 배치 디코딩할 때 SpeechSSM은 SpeechTransformer보다 120배 이상의 처리량을 달성할 수 있습니다.
- 시간 지연(Latency): SpeechSSM은 단계별 속도가 향상되어 단일 샘플 디코딩 시간이 더 빠릅니다. 2B SpeechSSM은 16384 토큰(약 10.9분)을 100초 조금 넘는 시간에 디코딩합니다.
5.4. 즉흥 연설 생성 (Extemporaneous Speech Generation)
- SpeechSSM-X는 216k 시간의 즉흥 독백 코퍼스에서 훈련된 SpeechSSM 모델로, 보다 비공식적이고 즉흥적인 스타일의 자연스러운 독백 음성을 생성할 수 있으며, 다중 문장 수준에서 유사한 일관성을 보입니다.
6. 결론 및 시사점
이 논문은 긴 형식 음성의 생성 모델링 작업을 다루며, 무한히 생성할 수 있고 메모리 부족 없이 작동하는 최초의 음성 LM인 SpeechSSM을 제시합니다. 또한 긴 형식 음성 연속을 위한 새로운 평가 방법과 LibriSpeech-Long 벤치마크를 제안했습니다.
분석 결과, SpeechSSM은 짧은 시간 범위에서는 기존 음성 LM과 대등한 성능을 보였지만, 수 분 길이의 생성에서는 기존 모델 및 Transformer 기준 모델을 크게 능가했습니다. 이 연구는 오디오북, 팟캐스트, 비디오 관련 콘텐츠와 같은 긴 형식 미디어를 포함한 새로운 오디오 생성 애플리케이션을 단순화하고 가능하게 할 것으로 기대됩니다.
연구진은 음성 언어 모델의 효율성 증가가 오디오 딥페이크나 저품질 합성 미디어의 확산을 증가시킬 수 있음을 인지하고 있습니다. 그러나 이 연구가 기존의 텍스트 LLM과 현대적인 음성 프롬프트 가능한 TTS 시스템을 결합하여 이미 달성 가능한 것(더 높은 콘텐츠 품질에서)을 악화시키지 않는다고 믿습니다. 이 작업이 LLM으로 인해 텍스트 미디어에서 나타난 상황과 유사하게, 딥러닝의 직접적인 방법이 표현력 있는 음성의 대규모 생성을 가능하게 한다는 대중의 인식을 높이기를 희망합니다.
'Paper Review' 카테고리의 다른 글
| "Assembly of Experts: Linear-time construction of the Chimera LLM variants with emergent and adaptable behaviors" 리뷰 (0) | 2025.07.06 |
|---|---|
| "Wider or Deeper? Scaling LLM Inference-Time Compute with Adaptive Branching Tree Search" 논문 리뷰 (0) | 2025.07.06 |
| "Self-Adapting Language Models (SEAL)" 논문 리뷰 (1) | 2025.07.04 |
| HyperCLOVA X THINK 리뷰 (1) | 2025.07.03 |
| Hunyuan-A13B 리뷰 (1) | 2025.07.03 |