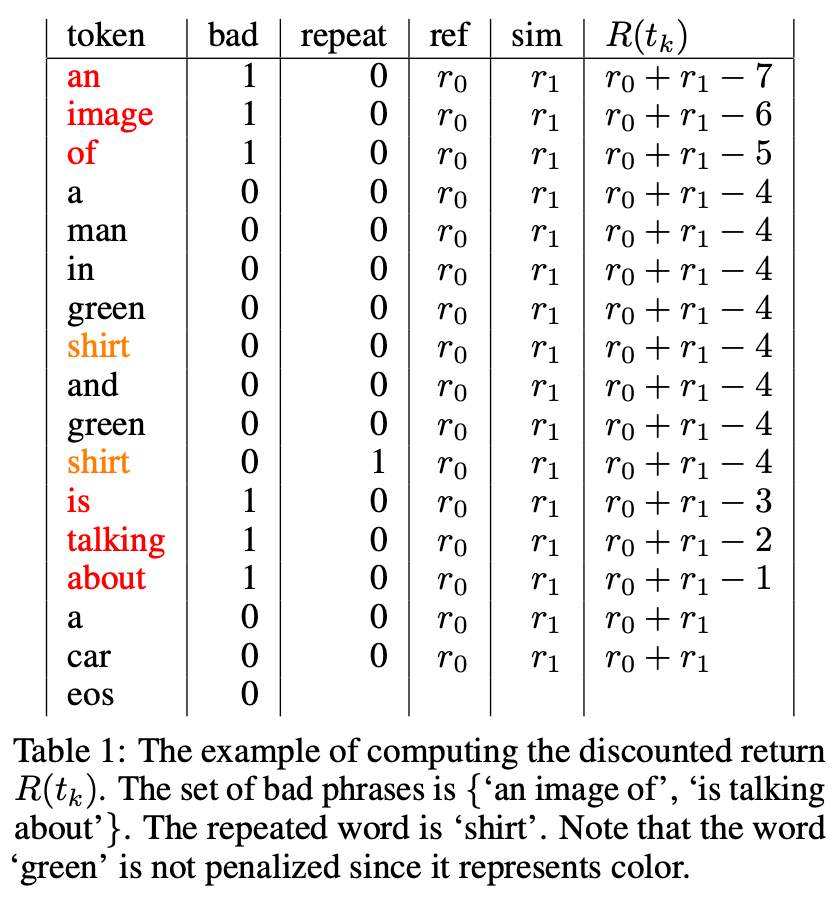
VLRM: 이미지 캡셔닝을 위한 비전-언어 모델을 보상 모델로 활용이 논문은 이미지 캡셔닝 모델, 특히 BLIP2를 강화 학습(Reinforcement Learning, RL)과 CLIP 및 BLIP2-ITM과 같은 비전-언어 모델(Vision-Language Models, VLM)을 보상 모델(Reward Model)로 활용하여 향상시키는 비지도 학습(unsupervised) 방식을 제안합니다. 이 방법을 통해 RL로 튜닝된 모델은 더 길고 포괄적인 설명을 생성할 수 있으며, MS-COCO Carpathy Test Split에서 인상적인 0.90 R@1 CLIP Recall 점수를 달성했습니다.1. 문제점 및 동기최근 개발된 이미지 캡셔닝 모델들은 인상적인 성능을 보여주었지만, 종종 캡션에 세부 정보가..