Paper link: https://arxiv.org/pdf/2012.12877.pdf
Introduction

- DeiT는 2020년 12월 경에 나온 논문으로, ViT가 거대한 데이터셋에서만 유의미한 결과를 얻을 수 있다는 한계점을 해결하기 위해 데이터와 컴퓨팅 자원을 효율적으로 사용할 수 있는 knowledge distillation 기법을 통해 모델을 효율적으로 학습시키고자 했다.
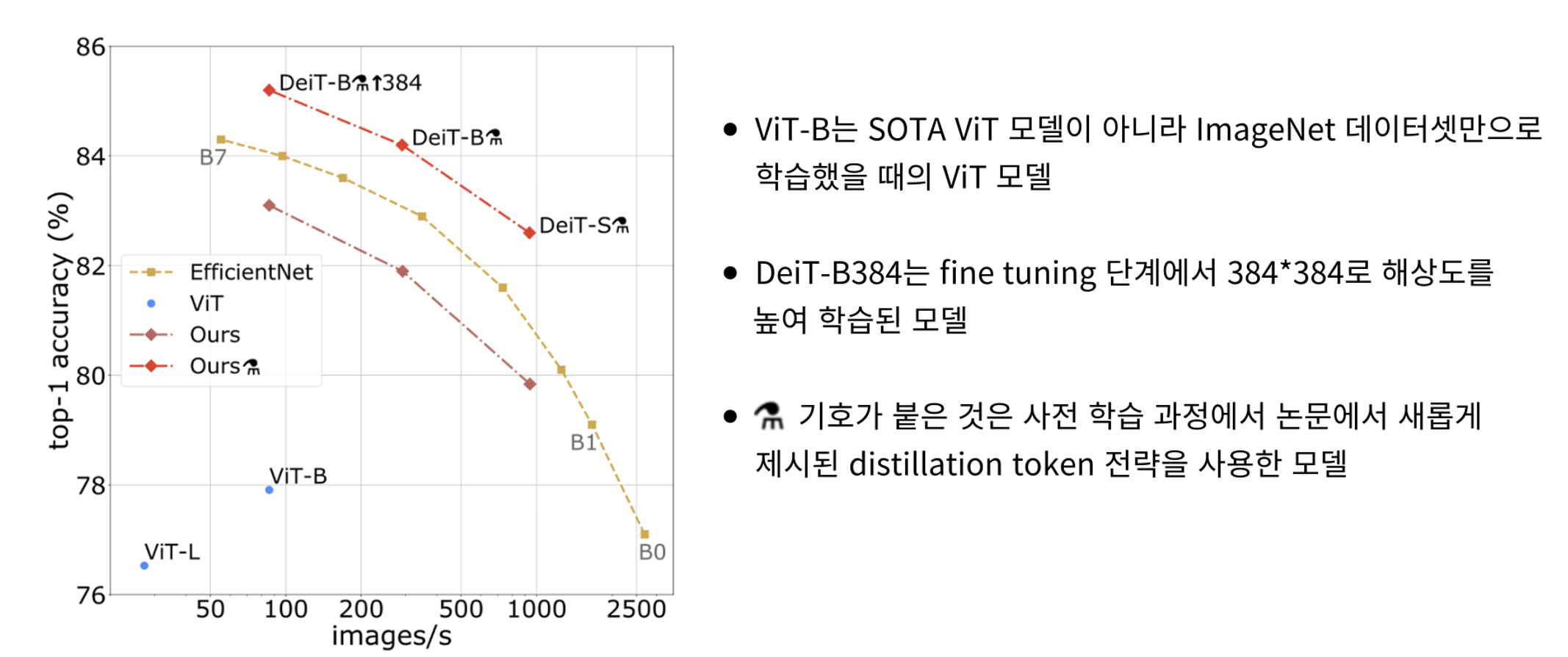
- ImageNet1k 데이터셋으로 훈련된 CNN 기반의 분류 모델 efficientNet 모델과의 성능 비교 그래프
- x축은 초당 처리된 이미지 수, y축은 정확도로 우측 상단에 위치한 모델의 성능이 좋음
- 같은 데이터로 학습하였을 때 CNN 기반의 EfficientNet보다도 distillation을 사용하여 자원을 효율적으로 사용한 DeiT 모델이 전반적으로 월등한 성능을 보여 주고 있음
Inductive Bias
- 모델이 학습 과정에서 본 적 없는 분포의 데이터를 입력 받았을 때 해당 데이터에 대한 판단을 내리기 위해 가지고 있는, 학습과정에서 습득된 Bias(편향)
- CNN(Convolution Neural Network)은 Convolution Filter가 이동하며 window 단위로 특성을 학습하기 때문에 window 간의 가중치 공유를 통해 Inductive Bias를 보유하게 됨
- 반면에 Transformer 모델은 인풋의 모든 토큰을 이용하여 연산하는 attention에 따라서 상대적으로 CNN에 비해 localiy한 가정이 없고, 따라서 inductive bias가 약함
- inductive bias가 부족하다는 것은 일반화 능력이 떨어진다는 것으로 그만큼의 데이터가 학습 과정에서 더 필요하다는 것을 의미
Knowledge Distillation
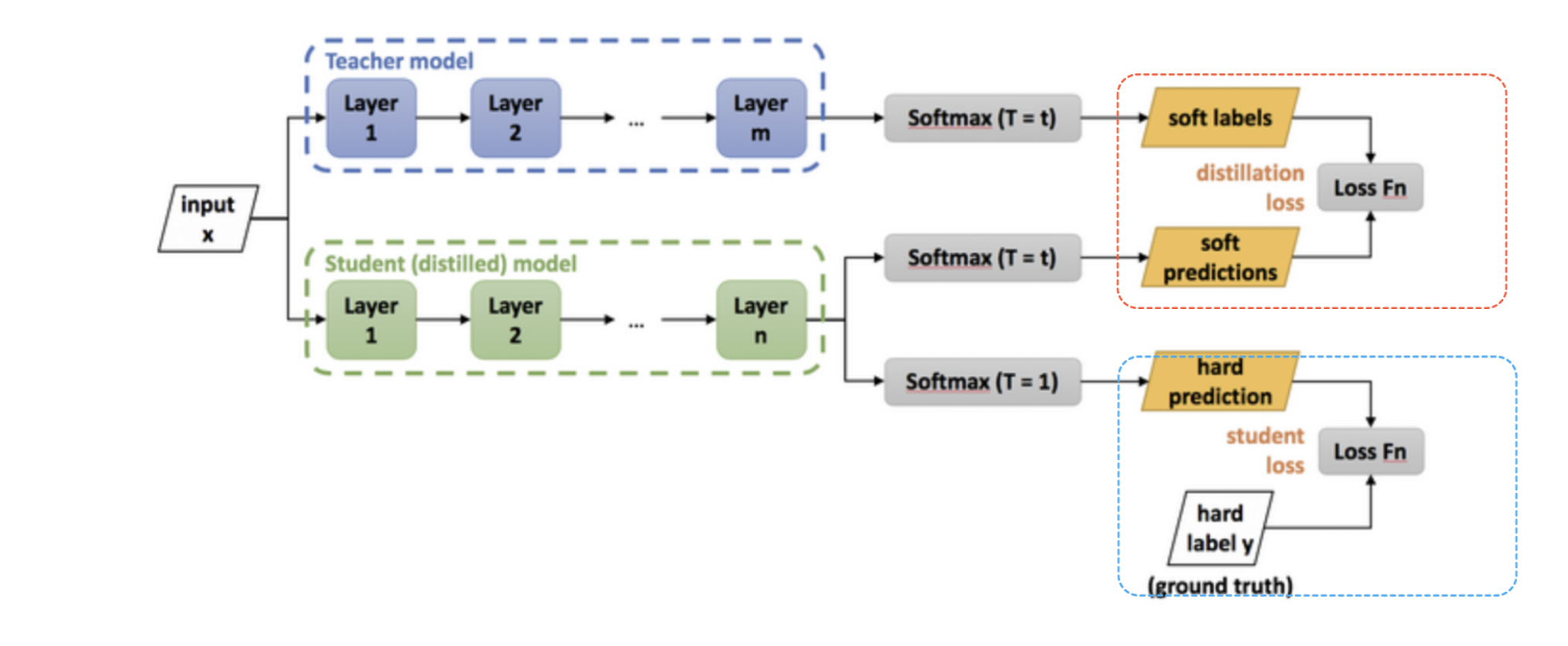
- 논문의 저자는 teacher model을 inductive bias를 많이 보유하고 있는 CNN을 teacher model로 선정하여 inductive bias를 student model로 전달하는 knowledge distillation 기법을 고안
- 크기가 더 작은 모델(student model)로도 큰 모델(teacher model)만큼의 성능을 낼 수 있도록 하는 기법
- 빨간색 박스는 student 모델과 teacher 모델의 softmax 값 차이를 cross entropy loss로 계산하여 학생 모델이 교사 모델을 모방할 수 있도록 하는 방식
- 파란색 박스는 student model의 분류 성능에 대한 loss로, 실제 레이블인 ground truth와 student의 결과 차이를 cross entropy로 계산
Soft Distillation
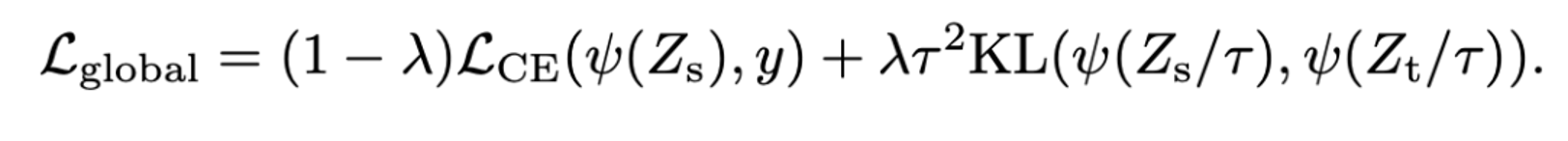
- teacher model의 softmax 값과 student model의 softmax 값 간의 KL Divergence를 최소화하는 방식
- 왼쪽항은 student model의 output과 ground truth와의 cross entropy 값, 오른쪽 항은 student와 teacher의 softmax 값을 temperature parameter을 사용하여 smoothing 한 후 KL divergence를 구하여 loss 값을 도출해내는 방식
Hard Distillation
- Teacher Model에서 argmax를 통해 가장 큰 Softmax 값을 가진 레이블을 one-hot 벡터 형태(y_t)로 hard하게 처리하여 Cross Entropy를 구하는 방식
- soft distillation의 λ와 τ가 없어졌기에 hyper-parameter로부터 조금 더 자유로운 방식이라고 할 수 있음

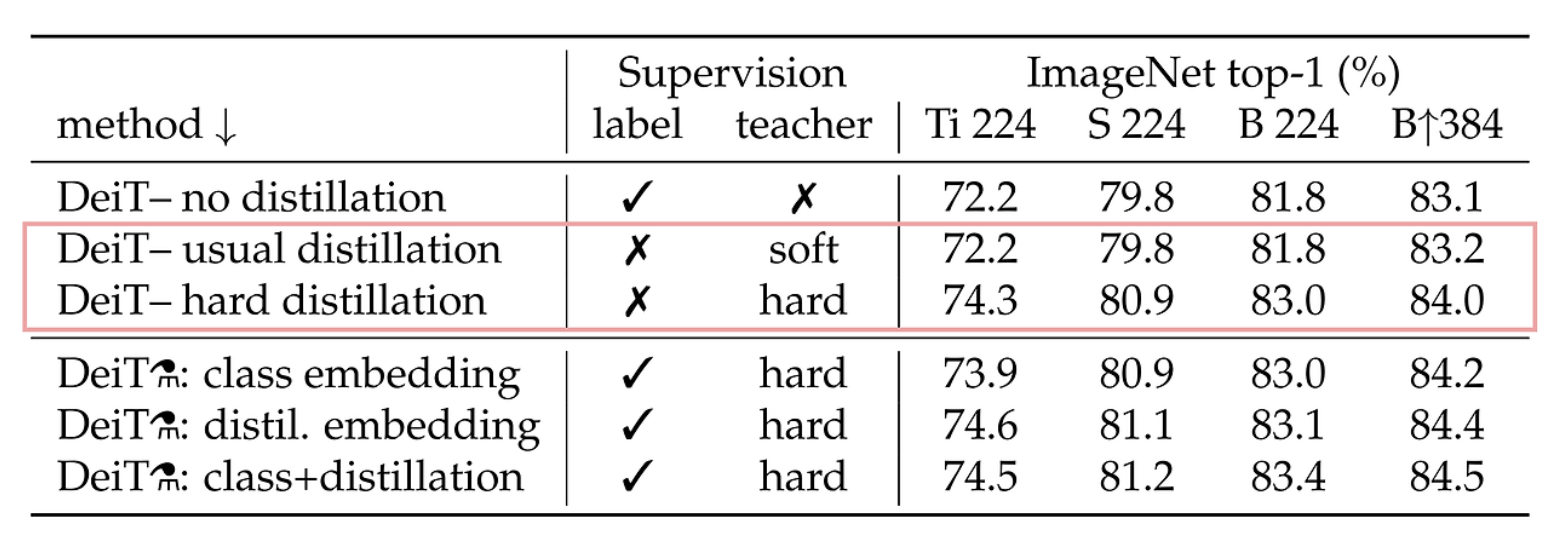
- 저자는 soft distillation과 hard distillation을 비교했을 때, hard label을 사용하는 것이 더 좋다는 것을 soft distillation보다 hard distillation이 높은 성능을 보인다는 것을 통해 주장
- 이 실험을 통해 hard distillation의 성능을 입증하였기에 후술되는 distillation 방식은 모두 hard label을 사용
Distillation Token
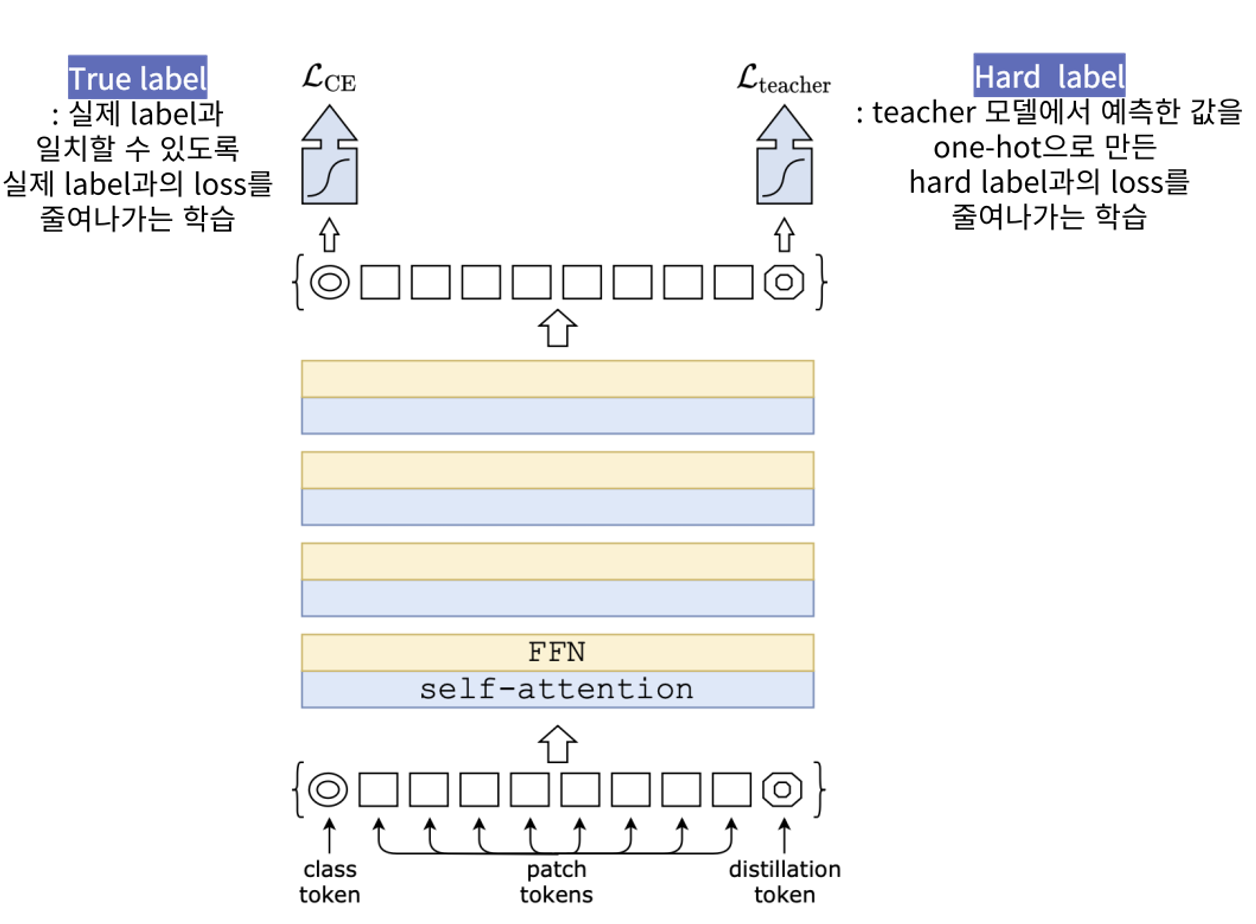
- 기존 ViT 모델의 input에 disilltaion token을 추가하여 Distillation Loss에 해당되는 부분을 담당하도록 함
- class token과 patch embedding들뿐만 아닌 distillation token까지 추가하여 이들 간의 관계를 self-attention을 통해 학습
- class token은 true label과 일치할 수 있도록 loss를 줄여 나가는 방식, distillation token은 teacher model에서 예측한 softmax 값을 argmax한 hard label과의 loss를 줄이는 방식
- 실제로 참인 label이 아닌 teacher model의 예측을 따라가는 것이기에 teacher model의 지식인 inductive bias를 전달받는 과정으로 볼 수 있음
class token과 distillation token은 input 단계에서 코사인 유사도가 0.06에 불과하지만, 네트워크를 거치면서 두 임베딩은 점점 비슷해지다가 0.96이라는 유사도를 가지게 됨 → 완전히 동일한 값을 가지지 않는다는 것은 서로 다른 정보를 학습하여 성능에 도움을 준다는 것
Experiments
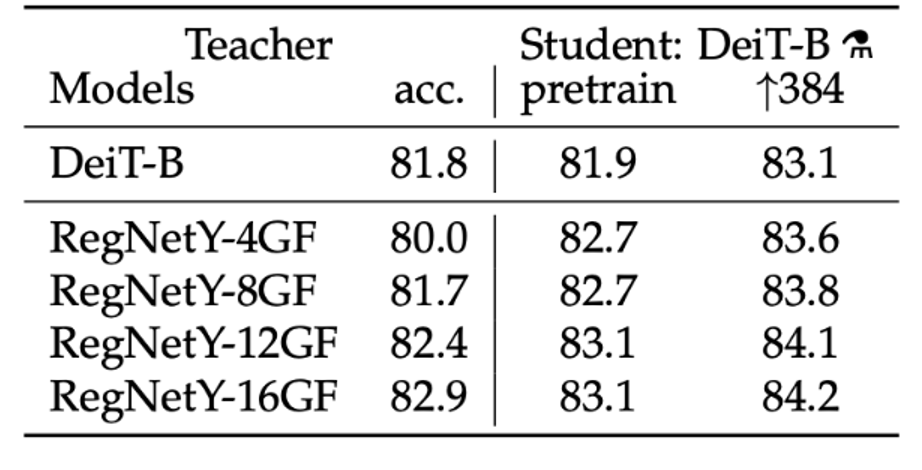
- 결과로는 CNN 모델을 teacher 모델로 사용했을 때 가장 높은 성능을 보임
- inductive bias를 가지고 있는 cnn 모델을 사전 학습한 teacher에서 student model로 inductive bias가 잘 전달되었기 때문
- DeiT-B의 정확도 81.8%과 거의 비슷한, 심지어 조금 낮은 CNN 모델인 RegNetY-8GF를 teacher model로 사용했을 때 더 큰 정확도를 가지는 것을 확인할 수 있음
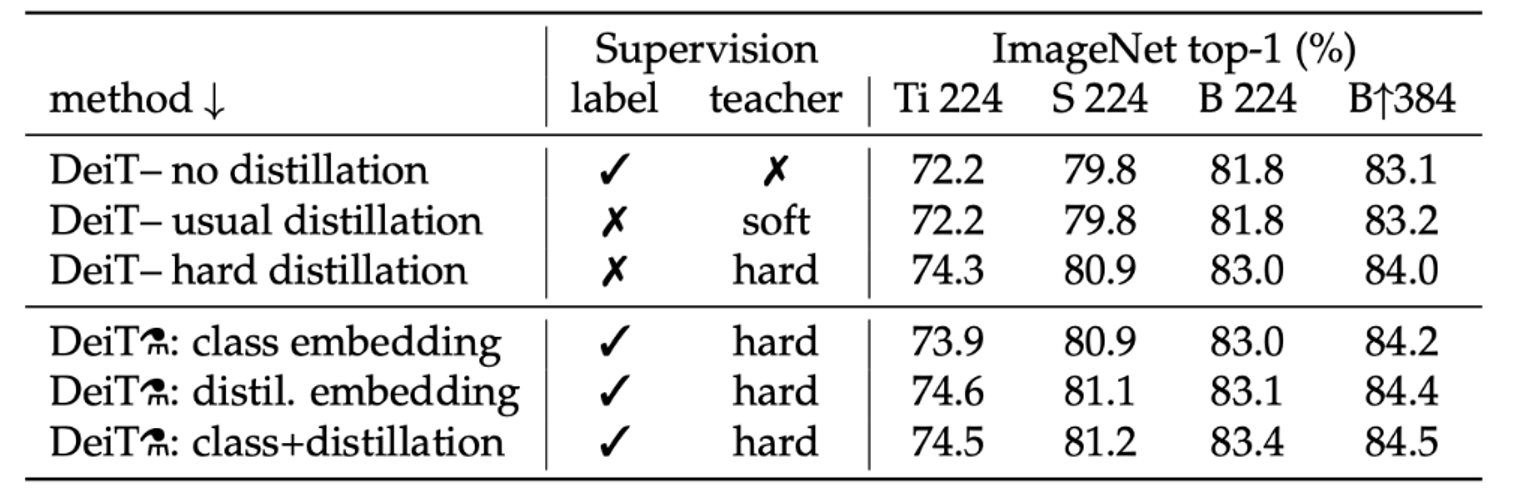
- soft label을 이용한 distillation과 hard label을 이용한 distillation 중 hard방식이 더 좋은 성능을 보임
- hard 방식을 통해 class token만을 이용한 결과, distillation token만 이용한 결과, 두 토큰을 결합하여 분류한 결과 중 class token보다도 distillation token 단독 사용이 더 높은 성능을 보이는 것을 확인할 수 있음
- 2개의 token을 동시에 사용하는 것이 가장 큰 성능 개선을 보여 줌을 알 수 있습니다. 이는 분류 task에서의 성능을 최대화하기 위해 여러 종류의 token을 결합하여 사용하는 것의 중요성을 부각
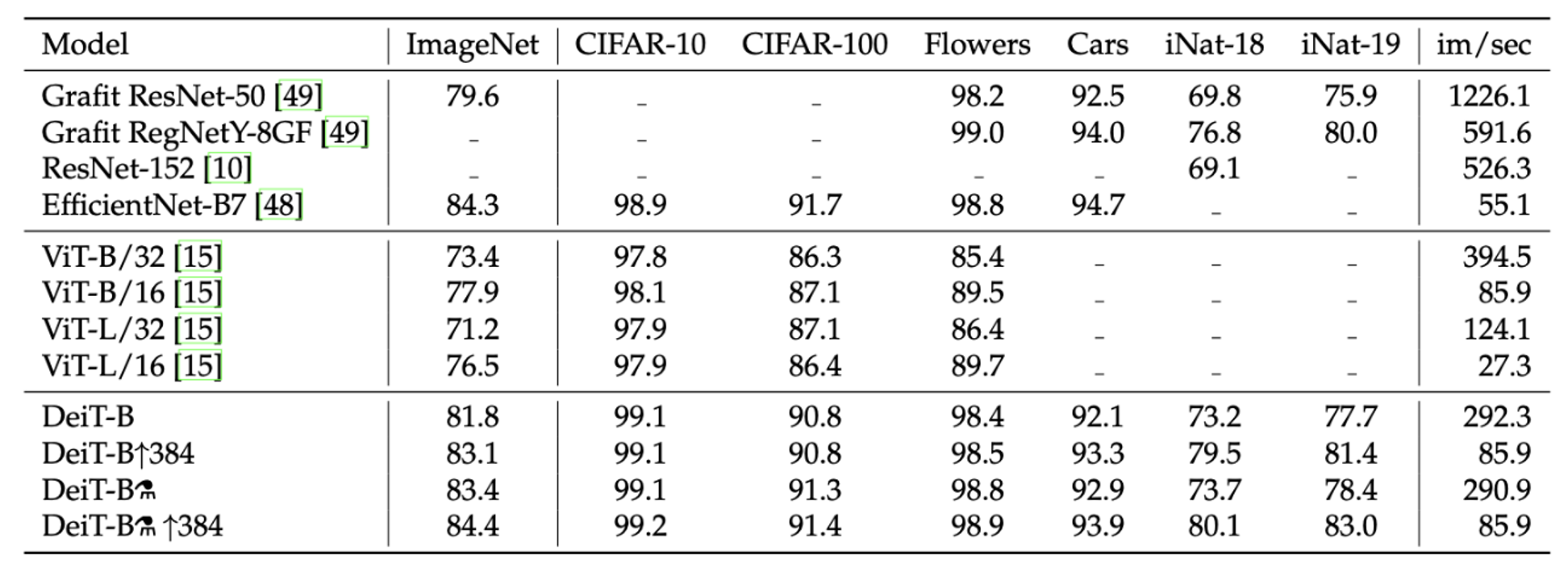
- 다른 데이터셋에서도 준수한 성능이 나오고 있음을 알 수 있으며, CNN 계열의 모델 성능을 따라잡는 모습
- imageNet으로 학습된 ViT base 버전보다 눈에 띄는 성능 개선 수준을 보여 주고 있기에 같은 아키텍처를 가진 모델에서 distillation token이 얼마나 효과 있는지에 대해 시사