Xception :
Deep Learning with Depthwise Separable Convolutions
Francois Chollet, Google, Inc
논문 리뷰 : 중앙대학교 안익균
원문 링크 : https://arxiv.org/abs/1610.02357
이 문서는 논문 원본의 내용을 충실히 전달하고자 하는 목적으로 작성되었다.
쉬운 이해를 위해 최대한 한국어로 작성했으며 추가적인 설명이 필요한 부분은 별도 조사를 통해 추가하였다.
Abstract
Inception 모듈은 regular convolution과 depthwise separable convolution의 중간에 있는 모듈이라고 저자는 주장한다. Depthwise separable 모듈은 Inception 모듈의 tower(입력 특성 맵을 여러 가지 방법으로 처리하는 합성곱 연산의 집합)를 극단적으로 구현한 것이라고 할 수 있다. 이런 극단적인 구조를 사용하여 Inception 모듈을 변형했고, 모델의 성능이 개선되었음을 밝혔다. ( = Xception)
Inception V3와 같은 파라미터를 설정하여 평가했기에 모델의 파라미터 수의 증가가 아닌, 모델의 구성과 효율성 때문에 성능이 증가했다고 주장했다.
1. Introduction
CNN은 강력한 Vision분야의 알고리즘이다.
AlexNet과 ZFNet, VGG, Inception이 사용된 GoogLeNet 또한 V1부터 V3, 그리고 Inception-ResNet 발전되었음을 간단히 소개했다.
저자들은 Inception module이 어떤 방식으로 작동하고 왜 성능이 잘 나오는지 밝히기 위해 논문을 작성했다.
1.1 The Inception hypothesis
합성곱은 W x H x C 차원을 가지는 이미지에 필터를 적용한다. 이 말은 채널간 연관성(cross-channel correlations)과 공간적 연관성(spatial correlations)를 동시에 mapping한다는 것이다.
Inception 모듈에 적용된 아이디어는 위 과정을 쉽고 효율적으로 하기 위해 독립적으로 연관성을 본 후 실행한다는 것이다.
구체적으로 살펴보자 : Inception 모듈은 먼저 1x1 필터로 원래 이미지를 3~4개의 구분된 공간으로 나눈다. 이 1x1필터는 채널간 연관성만을 먼저 확인하는 역할을 하게 된다.
이후 3x3, 5x5같은 필터를 사용하여 채널+공간 연관성을 학습한다.
이런 독립적인 과정이 포함된 Inception 모듈이 채널간 연관성과 공간 연관성을 충분히 decoupled했고, 이 때문에 Inception 모듈이 성능이 좋을 것이라는 가설을 설정한다.
(첨부한 Figure 1.은 Inception V3모델임. 위 설명을 그림으로 표현한 것)
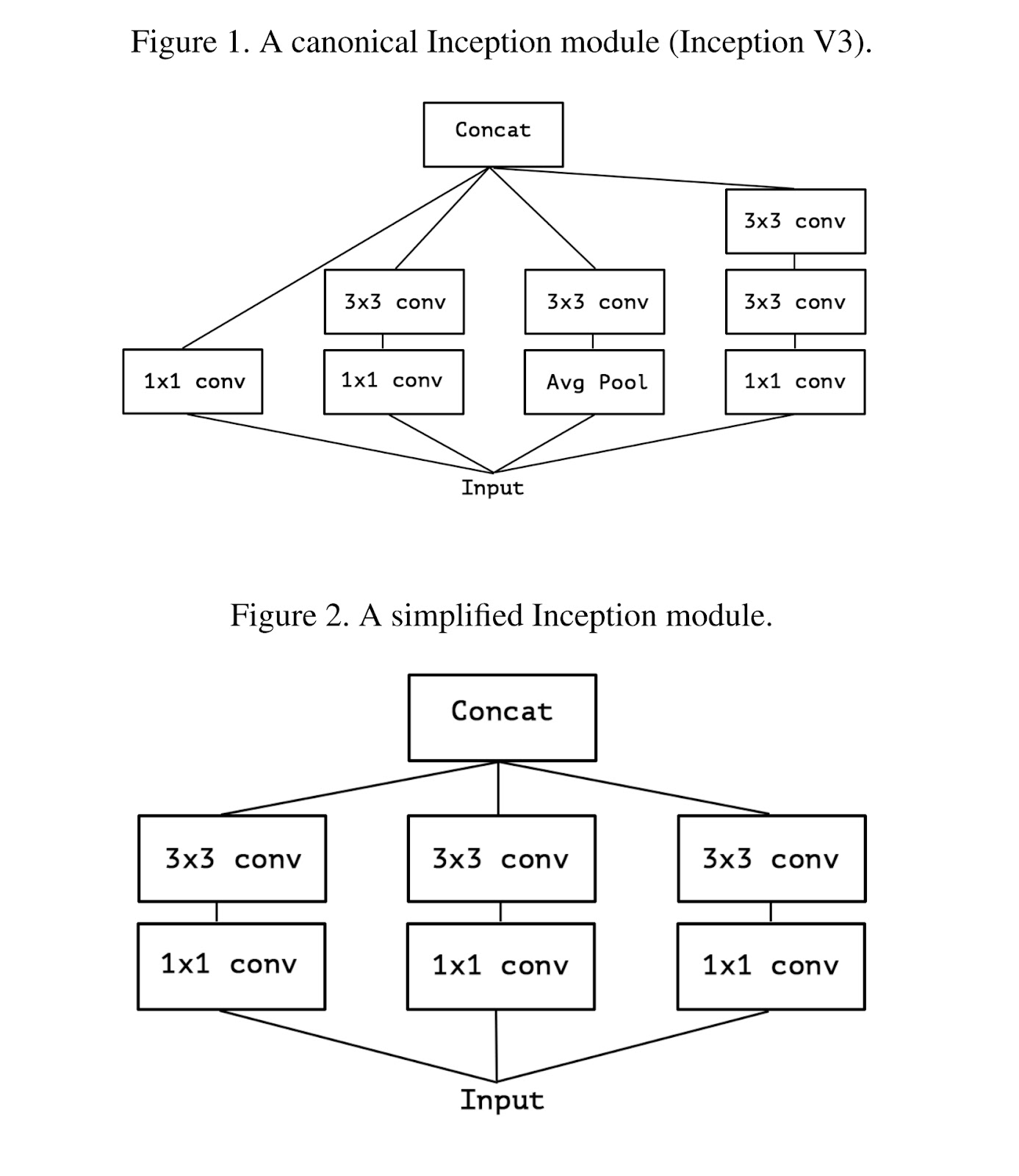
여기서 생기는 의문은 아래와 같다.
Inception hypothesis가 맞다면 채널간 연관성과 공간 연관성을 더 완벽하게 분리해서 각각 mapping한다면 더 성능이 좋겠다! 저자들은 이를 증명하고자 한다.
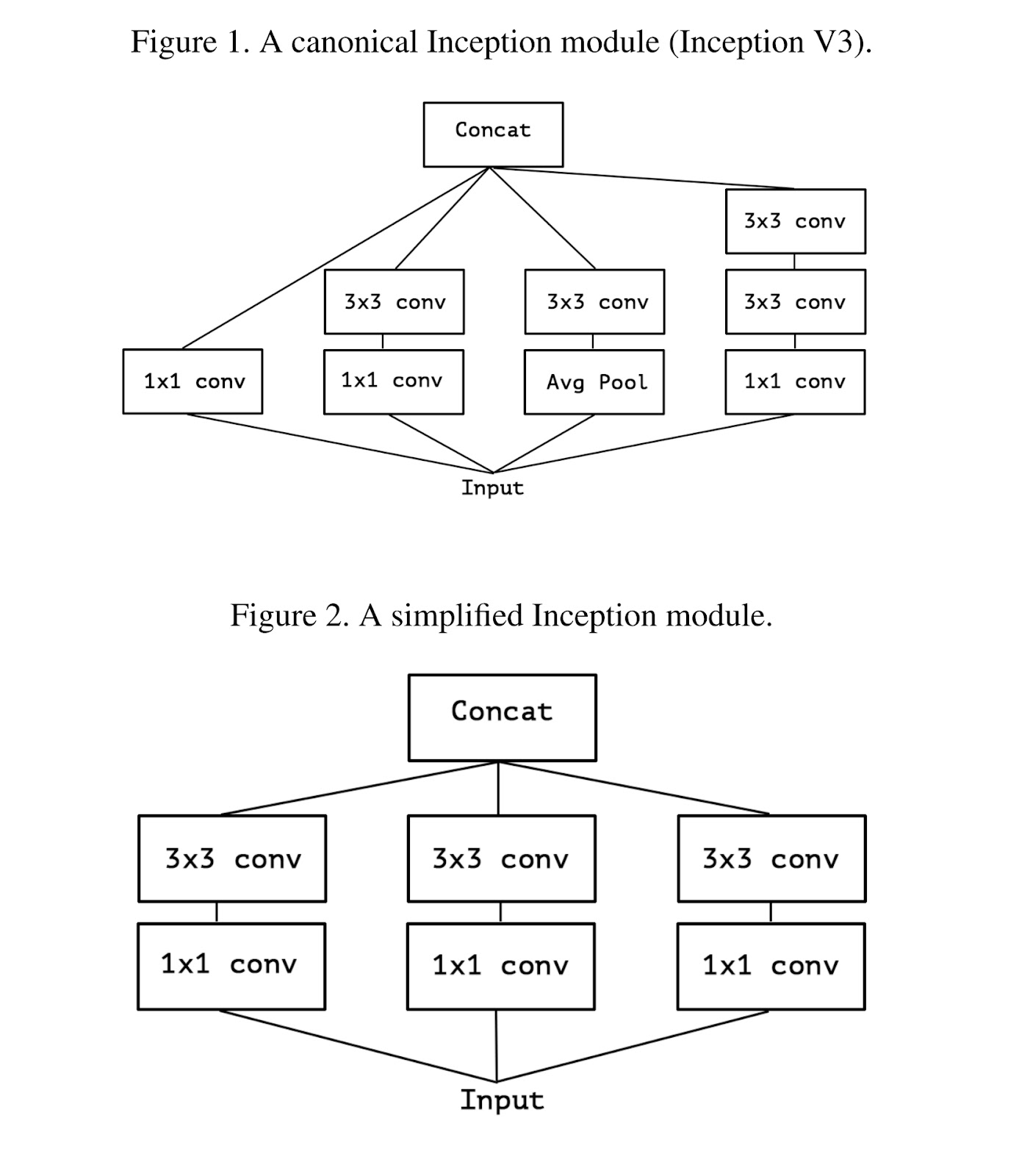
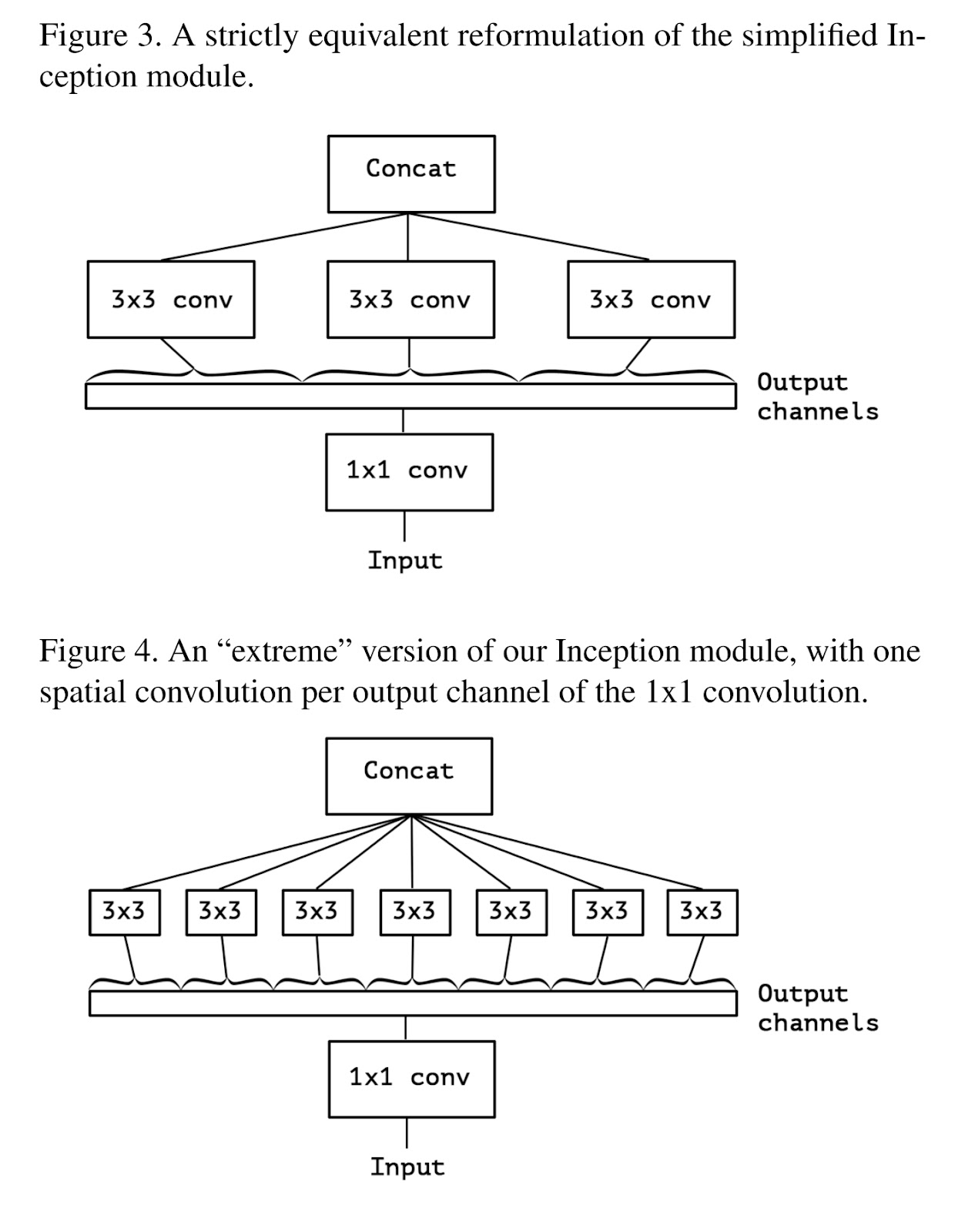
Figure 2. 은 Figure 1.을 간단히 만든 것이다. Figure 2.를 보면 1x1 conv로 채널을 어느 정도 겹치게 묶어서 분리해주고 있다. 더 완벽한 분리를 위해 Figure 3.의 구조를 고안했다. 채널을 겹치지 않게 분리하는 것이다. 이를 표현하기 위해 Figure 3.는 Output channels을 일자로 핀 형태로 표현했고 겹치지 않는 다는 것을 알려주기 위해 범위를 그려 3x3 conv에 이어주었다.
1.2 The continuum between convolutions and separable convolutions
위에서 설정한 가설을 확인하기 위해 ‘extreme’한 Inception 모듈을 만들었다. 1x1 conv를 통해 채널을 모두 나누고 그 결과에 각각 3x3 conv를 취하는 것이다. Figure 4. 는 이를 표현하고 있다. Figure 3. 의 컨셉을 더욱 ‘extreme’하게 만든 모형이 된다.
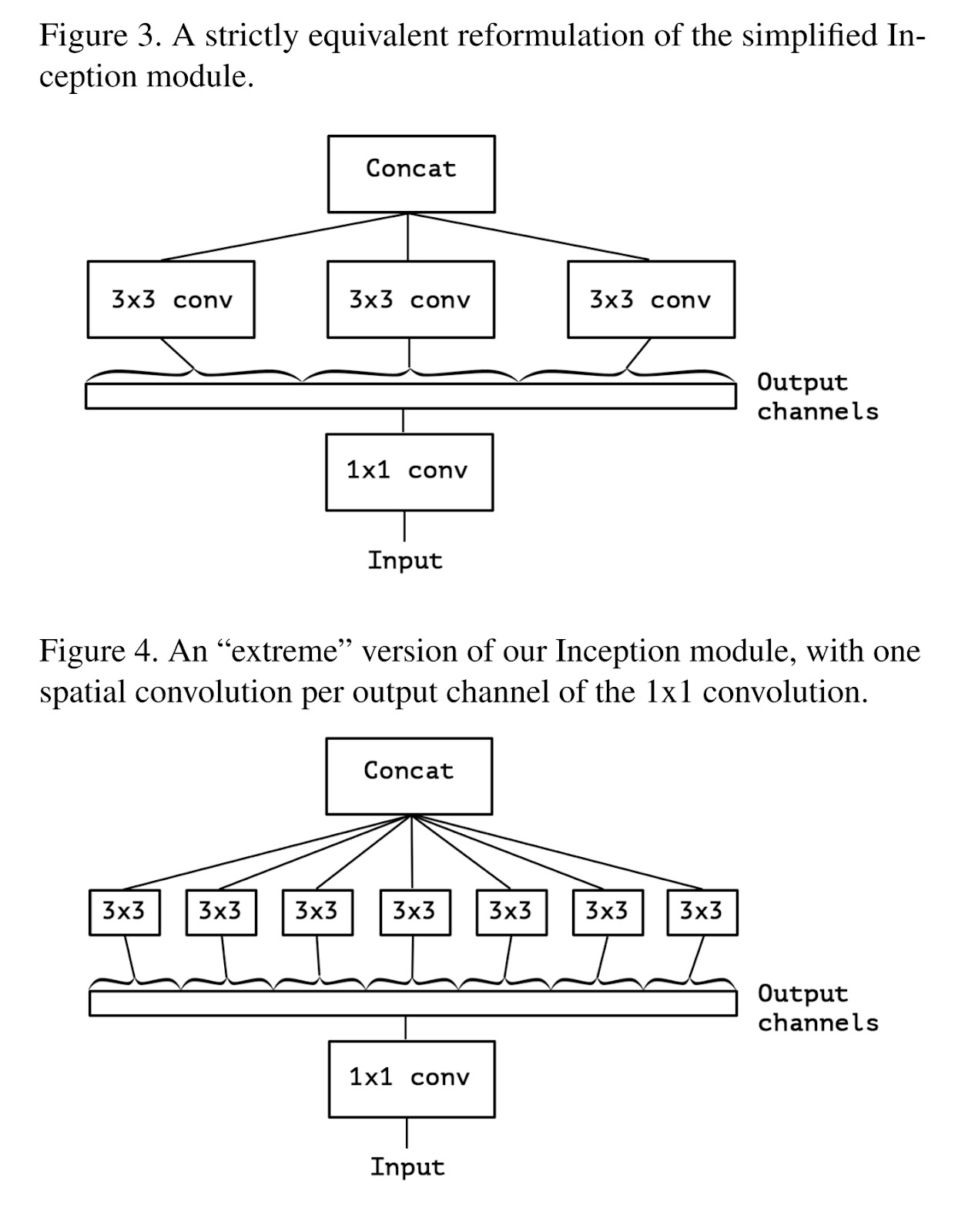
이런 모형은 depthwise separable convolution[1] 과 비슷하다고 저자들은 설명한다.
depthwise separable convolution :
‘separable convolution’으로 불리기도 하는 이 합성곱은 depthwise conv와 pointwise conv 연속된 두 단계로 구성된다.
1.depthwise conv : 모든 각각의 채널에 대해 spatial conv를 적용한다.
2.pointwise conv : 1x1 conv를 통해 채널들을 투영하여 새로운 채널 공간으로 보낸다.
하지만 ‘extreme Inception’과 ‘depthwise separable conv’ (d-s-conv)와는 차이가 있다.
먼저 순서의 차이이다. ‘extreme Inception’은 1x1을 사용하여 채널을 분리하지만 ‘d-s-conv’ 는 각 채널에 conv적용하고 1x1을 나중에 사용하여 채널을 통합한다.
두 번째로 non-linearity의 존재이다. extreme Inception은 첫 번째 실행 후에 ReLU를 사용한다. 하지만 d-s-conv는 사용하지 않는다. 저자들의 실험적인 결과를 통해 첫 번째 차이보다 두 번째 차이가 더 중요했다고 주장한다. (non-linearity 관련 내용은 뒤에서 소개)
또한 Inception 모듈을 각 극단적 conv에 중간적인 형태라고 설명하고 있다.
하나의 극단적인 경우는 일반적인 conv이다. single-segment case라고 표현하였고 한번에 채널간, 공간 연관성을 모두 계산한다. 또 하나의 극단적인 경우는 d-s-conv이다. one segment per channel라고 표현하였고, 각 채널마다 공간 연관성을 계산 한다는 의미이다. Inception은 그 사이에 있는 모듈이다. 왜냐하면 채널을 3~4개로 나누고 공간 연관성을 계산하기 때문이다. 저자들은 이런 Inception 모듈을 조금 더 d-s-conv쪽에 가깝게 만들어 가설을 확인하고자 한다.
2. Prior work
VGG, Inception architecture, Depthwise separable conv, Residual Connection, ICLR등 여러 선행 연구가 도움이 되었다고 간략하게 소개했다.
3. The Xception architecture
저자들은 d-s-conv에 크게 의존하는 CNN 네트워크를 제안한다. 그리고 ‘ 공간 연관성과 채널간 연관성이 CNN의 feature map에서 완벽하게 분리될 수 있다’라는 가설을 세웠다.
새로운 CNN네트워크는 Xception이라고 부르고, ‘Extreme Inception’이라는 의미이다.
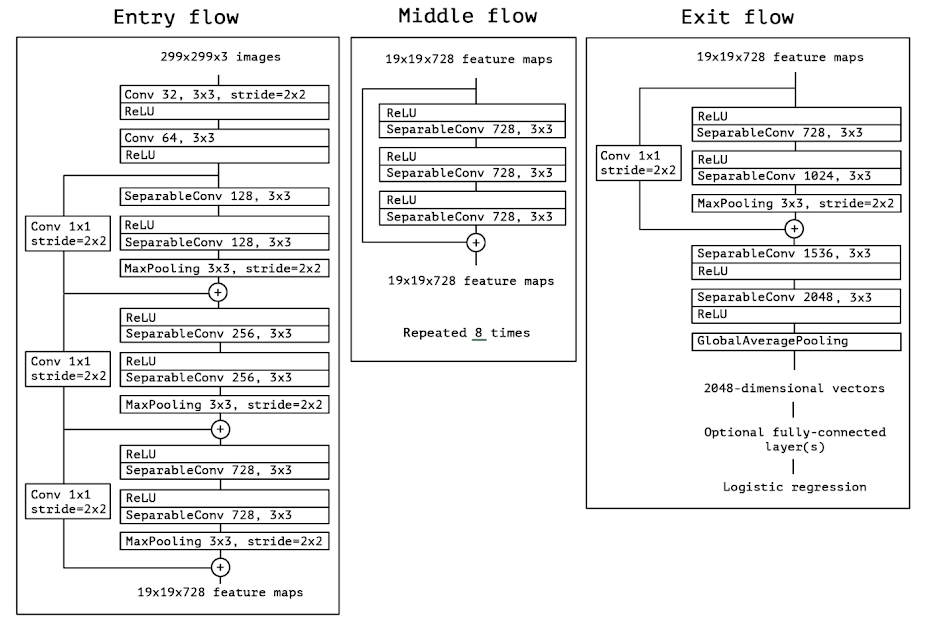
총 36개의 conv로 이루어졌고 14개의 module로 구성되었다. 마지막에 Logistic regression layer를 통해 output을 출력하며 처음과 마지막을 제외하고 Residual connection을 사용했다. 짧게 요약하면 Xception은
‘linear stack of depthwise separable convolution layers with residual connection’이다.
4. Experimental evaluation
주로 Xception과 Inception V3를 비교한다. 모델의 scale이 거의 비슷하기 때문이다.
ImageNet 데이터셋과 JFT으로 각 모델은 훈련했다.
ImageNet : 1M data 1k classes
- Optimizer : SGD
- Momentum : 0.9
- Initial learning rate : 0.045
- Learning rate decay : decay of rate 0.94 every 2 epochs
JFT : 350M data, 17k classes
- Eval : Mean Average Precision for top 100 predictions(Map@100)
- Optimizer : RMSprop
- Momentum : 0.9
- Initial learning rate : 0.001
- Learning rate decay : decay of rate 0.9 every 3,000,000 samples
(이후 평가에 대해서는 ImageNet과 JFT의 하위데이터인 FastEval14k를 사용했음.)
4.5 Comparison with Inception V3
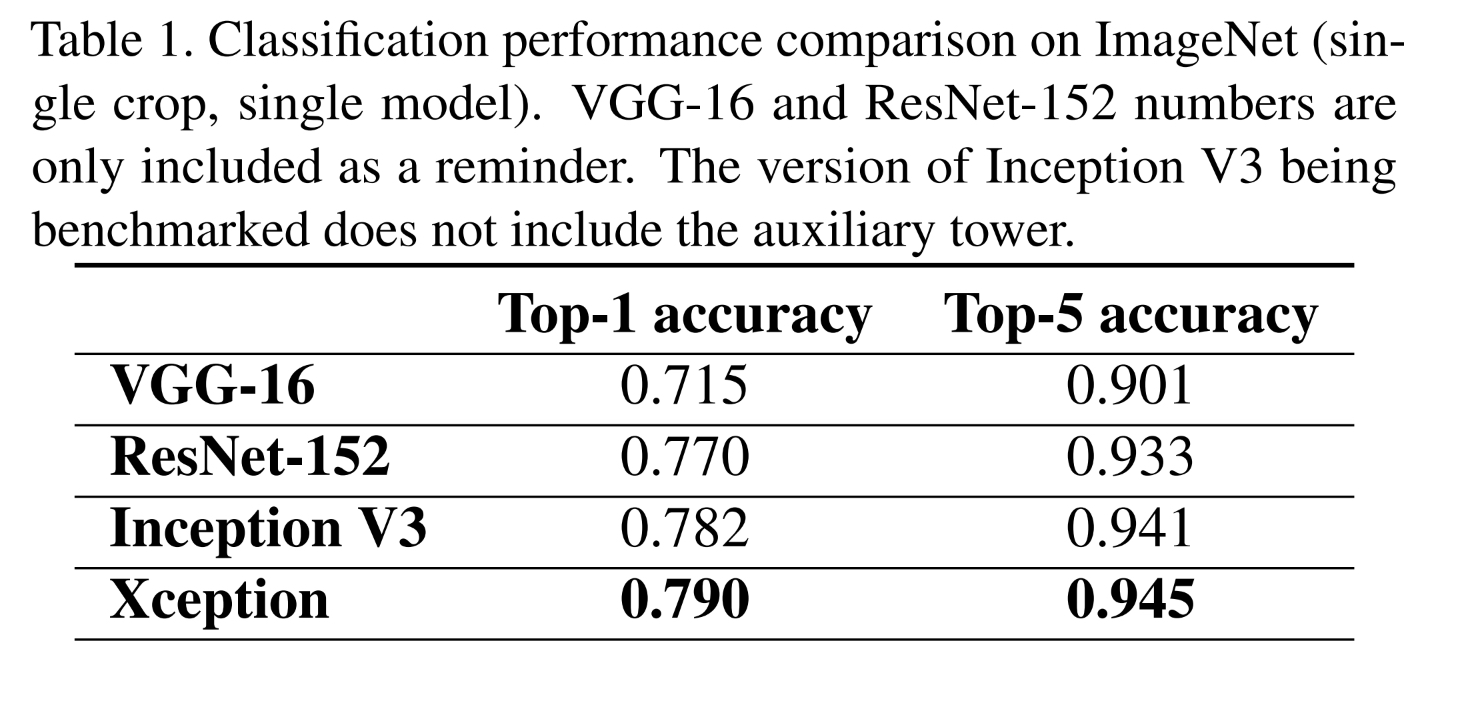
Xception이 ImageNet 데이터셋에서 Top 1 , Top 5, 두 지표 모두 성능이 높게 나왔다.
하지만 저자들은 성능차이는 더 클 것으로 주장한다. 그 이유는 아래와 같다.
Inception V3는 ImageNet에서 학습되었고 미세한 parameter optimization이 있었다. 그렇기에 데이터에 over-fit되었다는 것이다.
반면 Xception은 JFT에 맞춰 학습되었기 때문에 over-fit 하지 않다는 것이다.

실험과정에서는 마지막 Logistic regression전에 FC layers 추가한 것과 안한 것을 실험했다.
FC layers가 성능에 도움이 된 것으로 파악되었고 Xception이 성능이 더 좋다.
4.6 Effect of the residual connections
저자들은 residual connection의 유무를 달리하여 성능테스트를 했다. 결과적으로는 residual connection을 사용하는 것이 성능과 수렴 속도 모두 확실한 도움이 되었다.
4.7 Effect of an intermediate activation after pointwise conv
1.2절에서 저자들은 d-s-conv에는 non-linearity가 없다고 언급했었다. 이와 관련된 실험을 진행했다. pointwise conv를 실행하기 전 non-linearity를 추가한것이다. 결과는 예상밖이었다. 이전 Inception 모듈들에서와는 반대로 성능이 더 안 좋아진것이다. Inception모델 처럼 어느정도 깊이가 있는 feature space에서는 도움이 되었지만 d-s-conv처럼 얕은 feature space에서는 오히려 정보 손실을 야기했을 것이라고 주장한다.
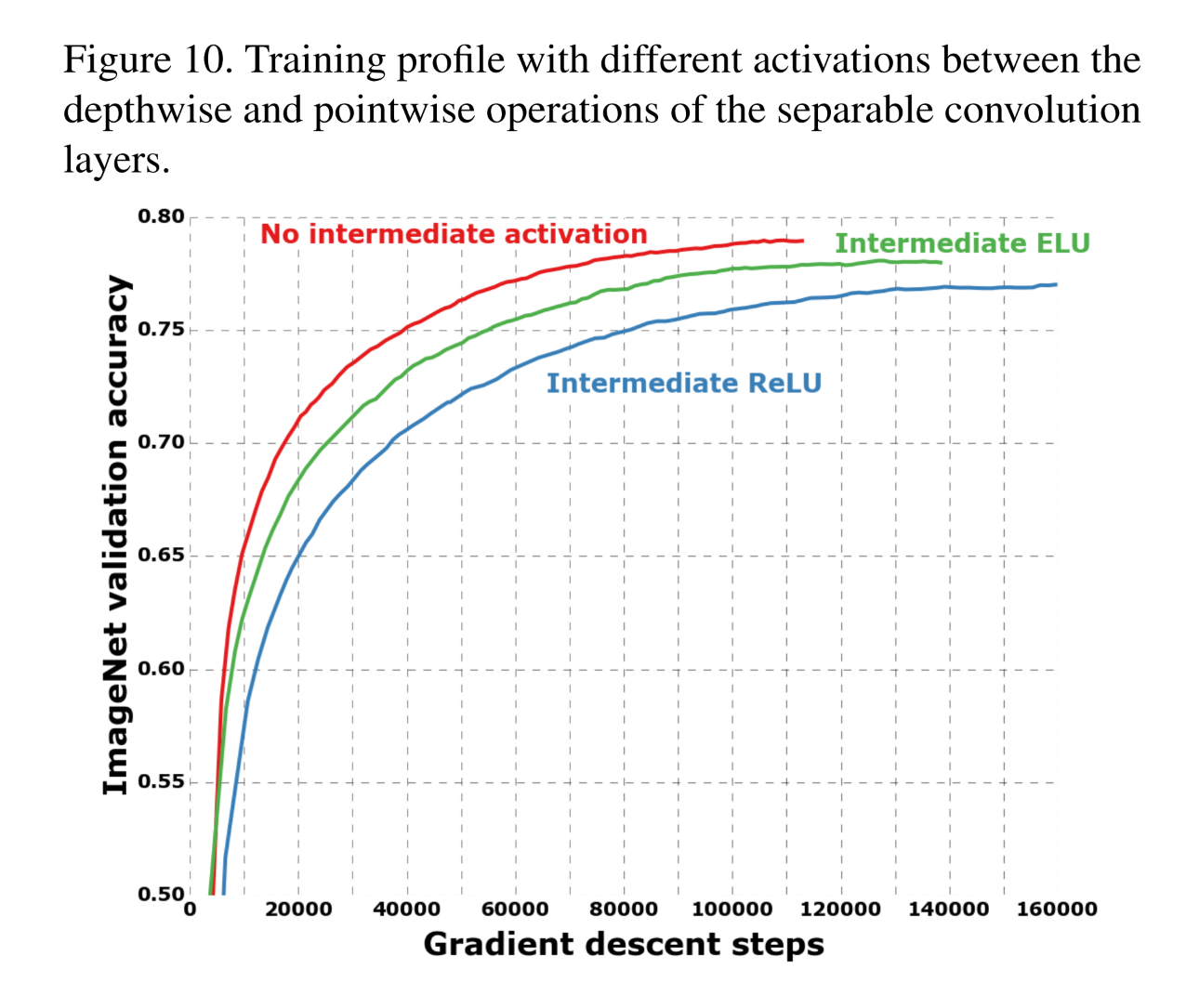
위 그림은 activation ftn의 유무 차이를 두고 d-s-conv에 적용해 성능평가를 한 것
6. Conclusions
일반적인 Conv와 d-s-conv를 양 극단으로 생각했을 때 그 중간 지점에 Inception있다.
이런 Inception을 조금 더 d-s-conv에 가깝게 변형하여 Xception을 만들었고 비슷한 scale의 모델로 더 좋은 성능을 달성했다.
7. My opinion
딥러닝의 신호탄이 된 2012년 발표되어 AlexNet은 계속해서 발전하였다. 모델의 크기를 키우고 싶지만 경사소실 문제로 어려움을 겪는 와중 VGG, GoogLeNet은 각자의 방식으로 모델의 깊이를 한층 더 깊게 만들었고 이후 2015년도에 나온 ResNet은 Residual connection을 활용하여 이전 모델들보다 약 5배정도 큰 모델을 만들어 인간 정확도를 뛰어넘었다. Xception은 2016년에 공개된 논문으로 GoogLeNet 모델 안에 있는 Inception 모듈에 대한 심화적인 연구이다. 그렇기에 Inception 모듈과 발전과정을 알아야 흐름을 파악하기에 용이하다. 또한 이 논문에는 그 동안의 경험적인 방법론을 다수 채택하고 있다. (ex Residual Connection) 개인적으로는 이 논문을 통해 CNN의 Spatial, channel 개념을 더 명확하게 이해할 수 있었다. 이를 이해하는 과정에서 배움이 있었다고 생각한다.
[1] depthwise separable convolution : L. Sifre. Rigid-motion scattering for image classification, 2014. Ph.D. thesis.