paper: https://arxiv.org/abs/2306.00830
Adapting a ConvNeXt model to audio classification on AudioSet
In computer vision, convolutional neural networks (CNN) such as ConvNeXt, have been able to surpass state-of-the-art transformers, partly thanks to depthwise separable convolutions (DSC). DSC, as an approximation of the regular convolution, has made CNNs m
arxiv.org
ConvNeXt 는 ‘A ConvNet for the 2020s’ 논문을 통해 발표된 모델입니다. ViT가 발표된 이후 Vision task에서는 Transformer에 연구가 집중되고 있는 상황에서 CNN 계열 모델에 최신 기법들을 적용하고 실험을 통해 높은 성능을 확인함으로서 CNN이 여전히 강하다! 는 것을 보였습니다. ResNet50을 base로 다양한 기법들을 적용하였는데요, 이에 대해서는 오늘 리뷰할 본 논문에서 언급된 부분에 대해서만 간단히 살펴보겠습니다.
ConvNeXt
- Changing stage compute ratio

기존 ResNet의 stage 구성인 3,4,6,3 을 Swin Transformer의 1:1:3:1 비율에 맞춰서 3,3,9,3 으로 변경해주었습니다.
- Changing stem to "Pathcify"
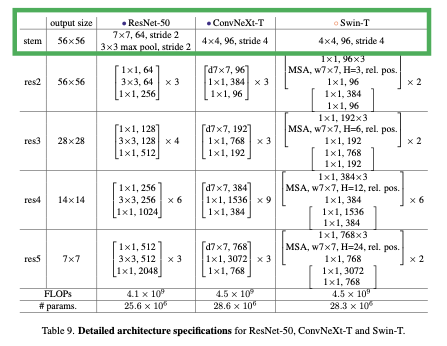
stem은 네트워크의 첫번째 layer 즉 데이터 입력을 받아 임베딩 하는 부분을 의미합니다. 원래 ResNet에서는 이 stem lyaer에 7 x 7 convolution, stride 2, max pooling이 포함되어있습니다. Swin transformer의 stem에서는 입력 이미지를 겹치지 않게 patch로 분할해 임베딩 하는데, 이것을 적용해 ConvNeXt에서는 4x4 커널 사이즈에 stride 4를 통해 입력 이미지를 패치화 해줍니다.
- Depthwise seperable convolution
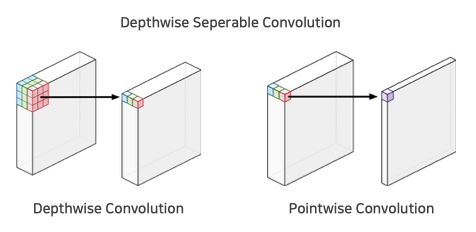
Depthwise seperable convolution은 채널별로 독립적으로 convolution 연산을 수행하는 Depthwise convolution과 1 x 1 컨볼루션으로 채널을 압축하는 pointwise convolution을 합친 것입니다. 이를 통해 연산량 (FLOPs)를 줄였습니다.
- Inverted Bottleneck
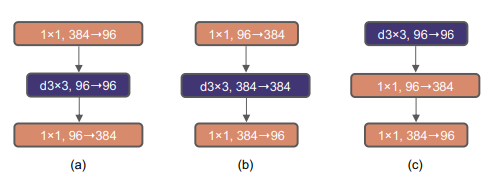
기존 ResNet은 그림(a)와 같이 1x1 convoluition 으로 채널을 줄인 후 3x3 conv를 진행하고 다시 1x1으로 채널을키우는 Bottleneck 구조를 가지고 있습니다. ConvNeXt는 Mobilenet V2에서 연산량을 줄이기 위해 사용한 그림(b)의 Inverted Bottleneck 구조를 사용하였고, 여기에 더해 deptwise convolution layer를 위쪽으로 이동시켜 최종적으로 (c)의 구조를 가집니다.
주요 feature가 담긴 저차원의 feature map을 확장시켜 넓은범위에서 주요 feature를 다시 파악하고, 기존 저차원에 담긴 주요 feature map과 skip connection을 진행하면서 효율적으로 더욱 많은 feature를 학습하기 위함입니다.
- Etc
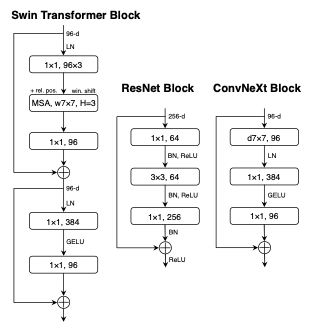
이 외에도 ReLU 를 GELU 로 대체하고, Batch Normalization을 Layer Normalization으로 변경했습니다. 또한 Activation과 Normalization을 매 layer 마다 적용하던 것을 stage별로 한 번씩만 적용하는 것으로 바꿨습니다.
Adapting a ConvNeXt architecture to audio classification
오늘 리뷰할 논문에서는 이 ConvNeXt를 AudioSet에서 사용하여 오디오 분류 작업을 진행하기 때문에 이에 맞춰 모델을 변경하였습니다.
- stem layer
Stem layer에서 기존 ConvNeXt의 출력 patch 크기는 56 x 56 으로 설정되어있었는데요, 이는 입력 이미지가 보통 정사각형 형태로 들어오기 때문입니다. 하지만 본 논문에서는 음성 데이터를 시각화한 스펙트로그램이 입력으로 들어가게 되는데 이는 가로축에 시간, 세로축에 주파수를 나타내 가로가 훨씬 긴 직사각형 형태를 가집니다. 따라서 여기에 맞춰 출력 patch의 크기를 252 x 56 으로 설정해주었습니다. 56 × 56, 122 × 122, 504 × 56 등 다양한 출력 patch의 크기를 테스트해봤으나 252 x 56 이 가장 높은 성능을 보였다고 합니다.
- 분류 헤드
기존 ConvNeXt는 1000개의 클래스를 가지는 ImageNet-1K 에서 사전 학습 되었기 때문에 1000차원의 분류 헤드를 가지고 있습니다. AudioSet 은 527개의 클래스를 가지고 있어 분류헤드를 527차원으로 교체하였습니다.
Experiment
- Dataset
- Data augmentation
- SpecAugment: Time warping, Time masking, Frequency masking
- Mixup: 두 개의 샘플 data를 혼합하여 새로운 데이터 생성
- Speed Perturbation: 발화의 속도 조절
- Training setup
- 512개 audio samples, eight V100-32GB GPUs, for 75k iterations
- AdamW optimizer
- “One-cycle” learning rate scheduler: maximum LR: 4e-3, reached after 30% of the training steps
- Weight decay (WD) 0.05, 0.4 drop path
- ImageNet1K에서 사전 학습된 모델의 체크 포인트 사용하여 초기화
Result

PANNs의 CNN14, 트랜스포머 계열 모델인 AST, PaSST-S 그리고 같은 ConvNext-Tiny 인데 JAX 언어로 구현된 Audax2 오디오 처리 프레임워크를 사용한 ConvNext-Tiny까지 총 4가지 모델과 비교하였습니다.
논문에서 제안된 모델이 mAP가 0.471로 가장 높았고, PaSST와는 비슷한 mAP를 보이지만 파라미터 수는 약 3배 적고 Throughput은 약 2배 더 빨라 저희 모델이 성능이 가장 좋은 것을 확인할 수 있습니다.