paper : https://doi.org/10.48550/arXiv.2406.15897
Introduction
기존의 retrieval system은 전통적으로 dual-encoder를 사용해서 query(caption), audio를 각각 처리한 후 multimodal metric space에 share하는 방식이었다.
이후 audio와 query의 distance를 측정하여 ranking 해 찾는 방식
이 방식을 content-based retrieval이라고 한다.
content-based retrieval의 성능을 향상 시키기 위한 시도가 여러가지 있었는데 아래와 같다.
① 사전학습된 모델 사용
② augmentation
③ 인공 캡션 생성
이 논문에서는 새로운 hybrid method를 제안하는데 hybrid method는 retrieval space상에서 pure content-based retrieval system과 pure metadata-based retrieval system을 결합한 방식이다.

왼쪽 그래프를 보면 순서대로 random baseline을 사용했을때, metadata만 사용했을때(keywords), content-based system을 사용했을 때의 성능을 보여주는데 random baseline을 사용했을 때보다 pure metadata-based system(keywords)이 월등한 성능을 보임을 알 수 있다.
따라서, metadata가 retrieval을 위해 사용할 수 있다는 가능성을 시사한다고 볼 수 있다.
오른쪽 그래프는 audio signal과 metadata가 embedded, fused 되어 audio items (a, m)으로 표현되고 있다. 이 audio items는 query와의 distance로 성능이 측정된다.
Related work
metadata를 사용하는 것은 language-based audio retrieval system에서 처음있는 일은 아니다.
기존에 metadata를 이용해서 caption을 생성한 연구(X. Mei, 2023), few-shot prompting 접근 방식으로 ChatGPT를 이용해 description을 caption으로 변환한 연구(G. Zhu, 2024), keyword를 가지고 ChatGPT를 통해 caption을 augment 한 연구(P. Primus, 2023) 등이 있었다.
하지만 이것은 모두 metadata를 인공 caption으로 변환하여 텍스트 입력으로 작업한 것으로 훈련 크기를 늘리지만 추론 시에는 메타데이터를 무시한다.
hybrid retrieval method는 훈련과 추론 시 오디오 녹음과 쿼리를 일치시키기 위해 추가 정보로서 사용 가능한 메타데이터를 사용한다.
Methodology
hybrid retrieval method의 기본적인 방법은 두개의 독립적인 modality encoder를 사용하여 embedding을 만들고 그것을 fusing 하여 하나의 item으로 표현하는 것
이 실험에서 사용한 metadata의 종류는 3가지가 있는데 다음과 같다.
- Closed Set (CS) of Tags
- 미리 정해진 리스트에서 descriptive tag를 결정
- Open Set (OS) of Tags
- 정해진 숫자로 제한하지 않는 tag
- ex. Keywords
- Full-Sentences (FS) Descriptions
- 단일 문장 자연어 설명
- such as descriptions used as captions for audio recordings
fusion의 방식은 두 가지를 사용했다.
- Late fusion
- 모달리티의 결합은 개념적으로 단순
- cross modal interactions X

- Mid-level fusion
- 오디오와 메타데이터 각각의 임베딩을 별도로 추출한 후, 이들을 중간 레이어에서 결합하여 사용
- 오디오와 메타데이터 임베딩 간의 상호작용을 허용하기 위해 이 두 임베딩을 중간 레이어에서 결합한 다음, 추가적인 처리(트랜스포머 레이어)를 거침

Experimental setup
Dataset : ClothoV2, AudioCaps
- ClothoV2
- AudioCaps
- fig4
- ClothoV2 데이터셋에서 가장 많이 사용된 15개의 키워드의 상대적 빈도(relative frequency)
- 특정 키워드의 빈도가 메타데이터와 자연어 캡션에서 다르게 나타날 수 있음을 보여주며, 이로 인해 검색 성능을 최적화하기 위해 다양한 접근 방식을 고려해야 함

사용한 pre-trained models
- 오디오 임베딩을 위해 MobileNetV3 사용.
- AudioSet에서 사전 훈련된 후 지식 증류(knowledge distillation) 적용.
- AudioSet에서 더 큰 모델(또는 앙상블 모델)이 학습한 지식을 MobileNetV3에 전이시키는 과정에서 지식 증류를 사용하여, MobileNetV3가 AudioSet에서 학습된 강력한 특징을 학습하도록 함.
- 설명 및 메타데이터 임베딩을 위해 BERT 사용.
- WordPiece 토크나이저를 사용하여 토큰화됨.
- 자연어 처리(NLP) 모델에서 사용되는 서브워드(subword) 토크나이저
- 서브워드 단위로 분할합니다. 예를 들어, "playing"이라는 단어는 "play"와 "##ing"으로 분할
- 현재 배치에서 최대 시퀀스 길이로 패딩됨.
- 32개의 토큰을 초과할 경우 잘림.
- 변환된 CLS 토큰은 압축된 텍스트를 나타냄.
- WordPiece 토크나이저를 사용하여 토큰화됨.
Optimization
- gradient descent and the NT-Xent loss
- (Normalized Temperature-scaled Cross Entropy Loss)
- Contrastive Learning에서 널리 사용되는 손실 함수로, 특히 자기지도학습(self-supervised learning)에서 두 데이터 간의 유사성을 학습하는 데 중요한 역할
- Adam
- learning rate was reduced from 2×10−5 to 10−7 using a cosine schedule
- 코사인 스케줄: 이 방법은 학습률을 급격히 줄이는 대신 부드럽게 줄여, 모델이 학습 과정에서 갑작스럽게 변하지 않고 안정적으로 수렴
- SpecAugment
Evaluation Metrics
- 세 번의 실행을 평균하여 도출
- K = 10, 주요 비교 기준으로 평균 정밀도(mAP@K)를 사용.
- 추가로, 상위 1, 5, 10개의 검색 결과에 대한 재현율(Recall)
- 보고된 메트릭은 실제 성능에 대한 하한값이며, 이전 연구에서는 실제 성능이 더 높을 가능성이 있음을 강조
Results
- 메타데이터의 효과:
- 메타데이터를 사용하면 순수 콘텐츠 기반 접근 방식보다 검색 성능이 향상됨.
- ClothoV2 데이터셋에서는 OS 태그를 사용했을 때 mAP@10이 2.36pp, FS 설명을 사용했을 때 8.82pp 향상됨.
- AudioCaps 벤치마크에서는 CS 태그를 사용했을 때 mAP@10이 3.69pp 향상됨.

- Cross modal interaction의 효과:
- 오디오와 메타데이터 임베딩의 late fusion이 mid-level fusion보다 나은 성능을 보임. 단순히 키워드와 설명을 직접 일치시키는 것이 오류 가능성이 적음.
- 태그 결합의 효과:
- 개방형(OS) 및 폐쇄형(CS) 태그를 결합한 데이터셋으로 훈련하면 ClothoV2 벤치마크에서 성능 향상 확인.
- AudioCaps 벤치마크에서는 약간의 성능 감소가 있었지만, 하이브리드 방법은 여전히 성능을 향상시킴.
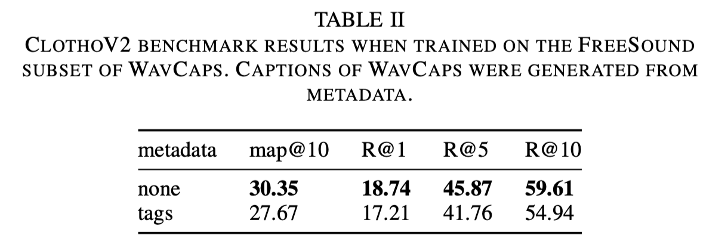
- 인공 캡션의 효과:
- 메타데이터로 생성된 인공 캡션을 사용하는 경우 하이브리드 접근 방식의 성능이 떨어짐. 모델이 메타데이터와 키워드 간의 높은 유사성에 의존하기 때문
- 텍스트 임베딩 모델 공유의 이점:
- 쿼리와 메타데이터 임베딩에 대해 텍스트 인코더를 공유하면 성능이 향상됨. 파라미터 공유가 하이브리드 접근 방식에 이점을 제공함.
Conclusion
- open and closed-set keywords and natural language descriptions 모두 검색 성능을 향상시키기 위한 적절한 후보
- 두 가지 버전(late, mid-level) 모두 콘텐츠 기반 기준 모델보다 성능이 향상
- late fusion이 약간 더 우수한 결과를 도출
- 일반적인 경향인지, 또는 MMT(Multimodal Transformer) 아키텍처에 의한 것인지를 확인하기 위해 더 심층적인 융합 방법 연구가 필요
- hybrid approach는 메타데이터에서 생성된 캡션과 잘 맞지 않음
- 모델이 훈련 중에 높은 캡션-메타데이터 유사성에 의존하게 되지만, 테스트 데이터에서는 이러한 유사성이 존재하지 않기 때문에 발생