2022 CVPR, IEEE published
2021년에 ViT 의 모델 중 하나인 Swin Transformers와 SSL 을 연관지어 발전시킨 논문들이 정말 많았으며, 본 논문도 그 중 하나임
Background : UNETR
- UNETR은 3D UNET의 Encoder 경로를 Transformer 구조로 대체한 모델
- Transformer는 특성 상 Input과 Output Shape이 같으므로, Skip Connection 단계에서 서로 다른 Deconvolution을 진행해서 UNet과 shape를 맞춰줌
UNETR Architecture
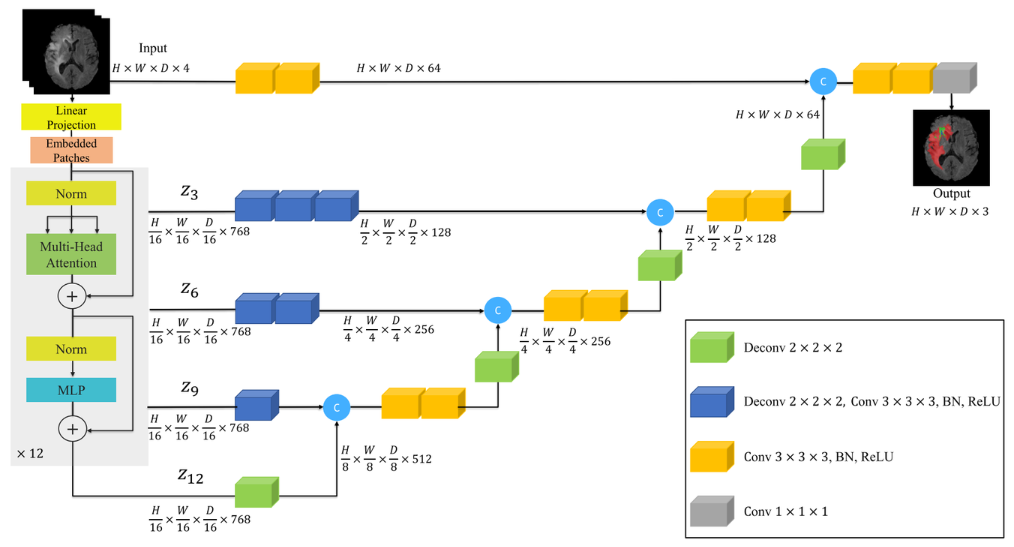
이 모델은 Transformer의 Attention 연산을 통해 Global 정보를 더 잘 획득하므로, 넓게 분포된 Tumor 영역도 잘 예측할 수 있다는 장점을 지님
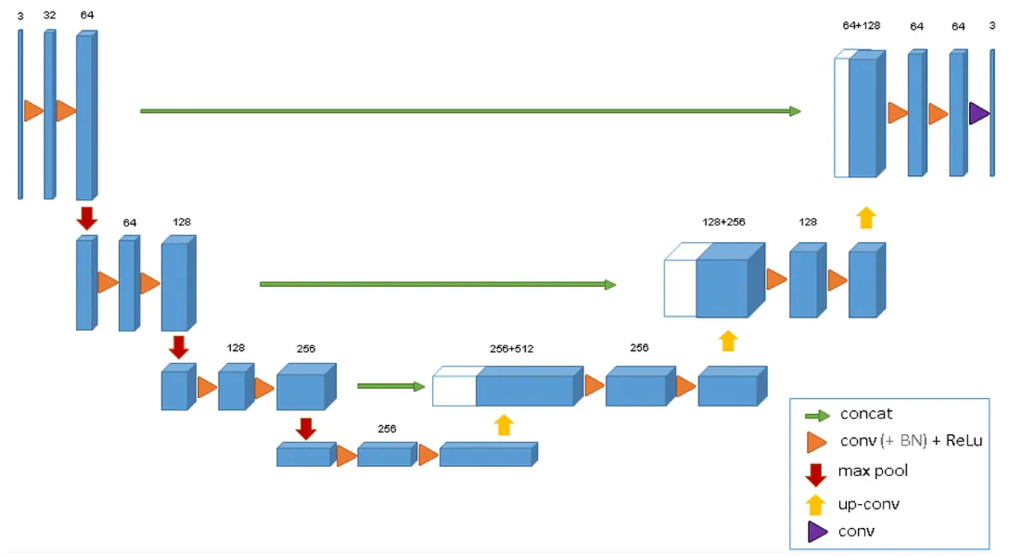
베이직한 3d U-Net과 비교하면, Encoder 부분이 Transformer 구조로 대체되고, skip connection 경로에 Dconv block이 추가된 것을 살펴볼 수 있다.
Background : Swin Transformer
- Transformer Encoder를 계층적으로 쌓은 모델
- Low Stage에서는 Patch Size를 작게 하는 전략 → Local Attention을 통한 local 정보 획득
- High Stage에서는 Patch Size를 크게 하는 전략 → Global Attention을 통한 global 정보 획득
- Shifted Window 알고리즘을 통해 window 간 attention도 진행함
⇒ 기존 ViT 대비 Local과 Global 정보를 효율적으로 획득할 수 있음
Swin Transformer Architecture
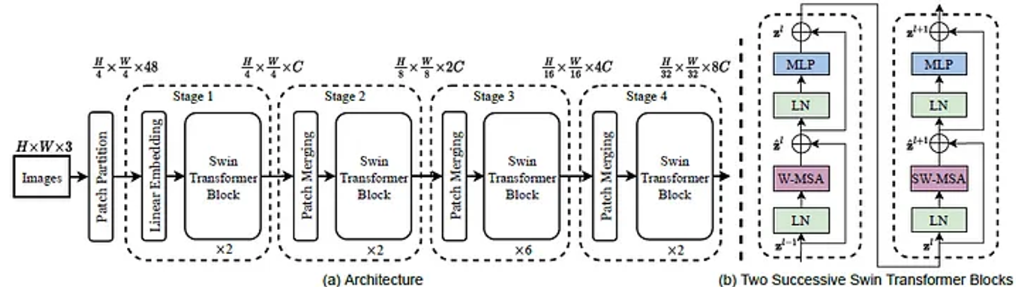
Swin Transformer
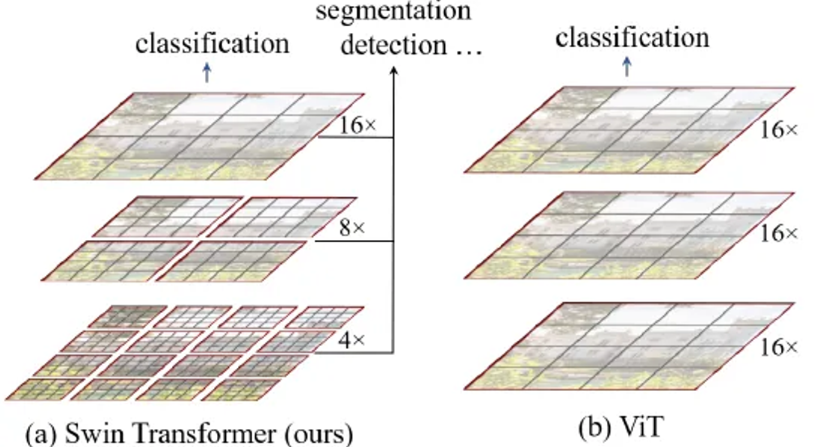
Shifted Window Based Self-Attention
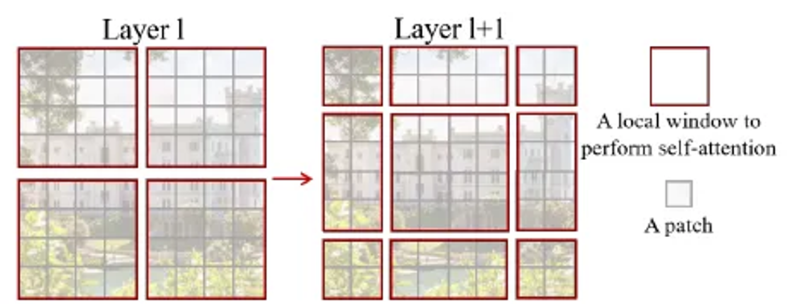
1. Window Based Self-Attention (W-MSA)
Self-attention is computed within local windows.
각 window가 M X M patches를 포함한다고 가정할 때, h X w patch 이미지를 기반으로 한 계산 복잡도는 다음과 같이 계산된다.
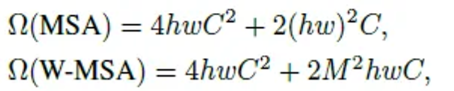
💡 Global self-attention computation (in standard ViT) is generally unaffordable for a large hw, while the window based self-attention is scalable.
2. Shifted Window Partitioning in Successive Blocks (SW-MSA)
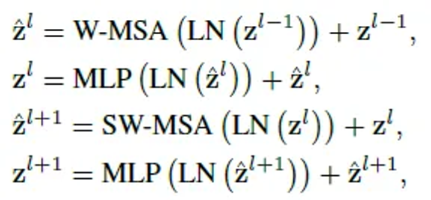
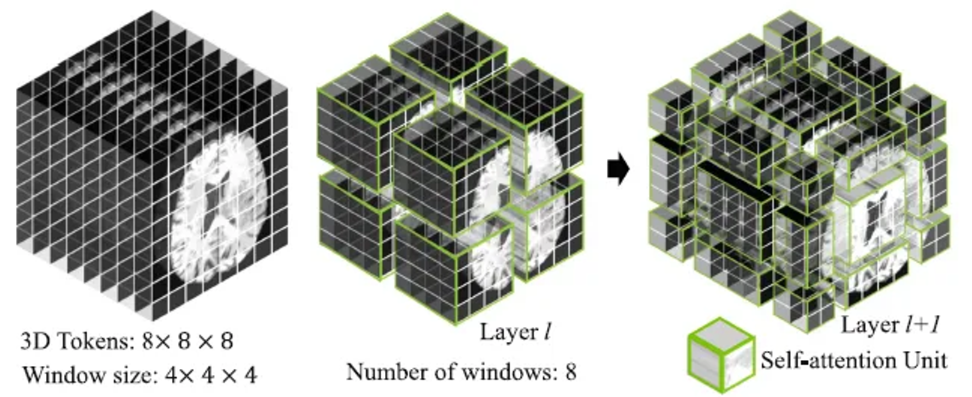
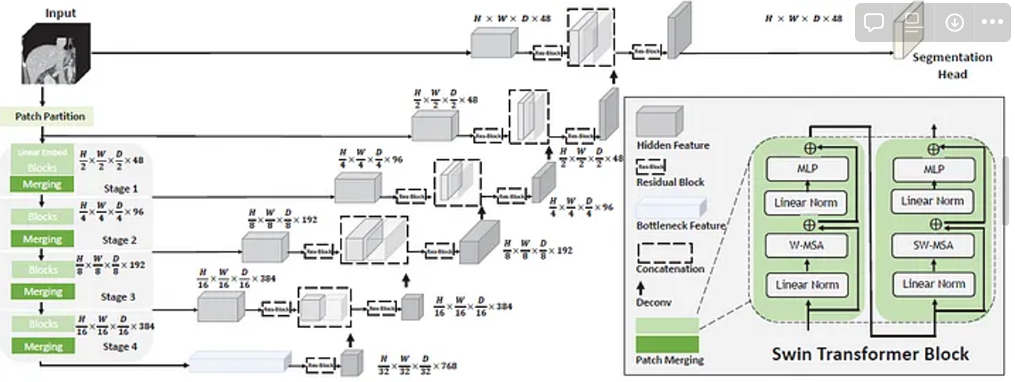
Background : Breaf Review of Swin UNETR
Swin UNETR 리뷰 참고 : https://sh-tsang.medium.com/review-swin-unetr-swin-transformers-for-semantic-segmentation-of-brain-tumors-in-mri-images-4fb757ad2915
- Swin UNet Transformers (Swin UNETR)은 3D brain tumor semantic segmentation task를 sequence to sequence prediction 문제로 재구성함
- multi-modal input data → 1D sequence of embedding
- 이를 Swin Transformer의 input으로 사용
Swin Transformer Block
(수정중)