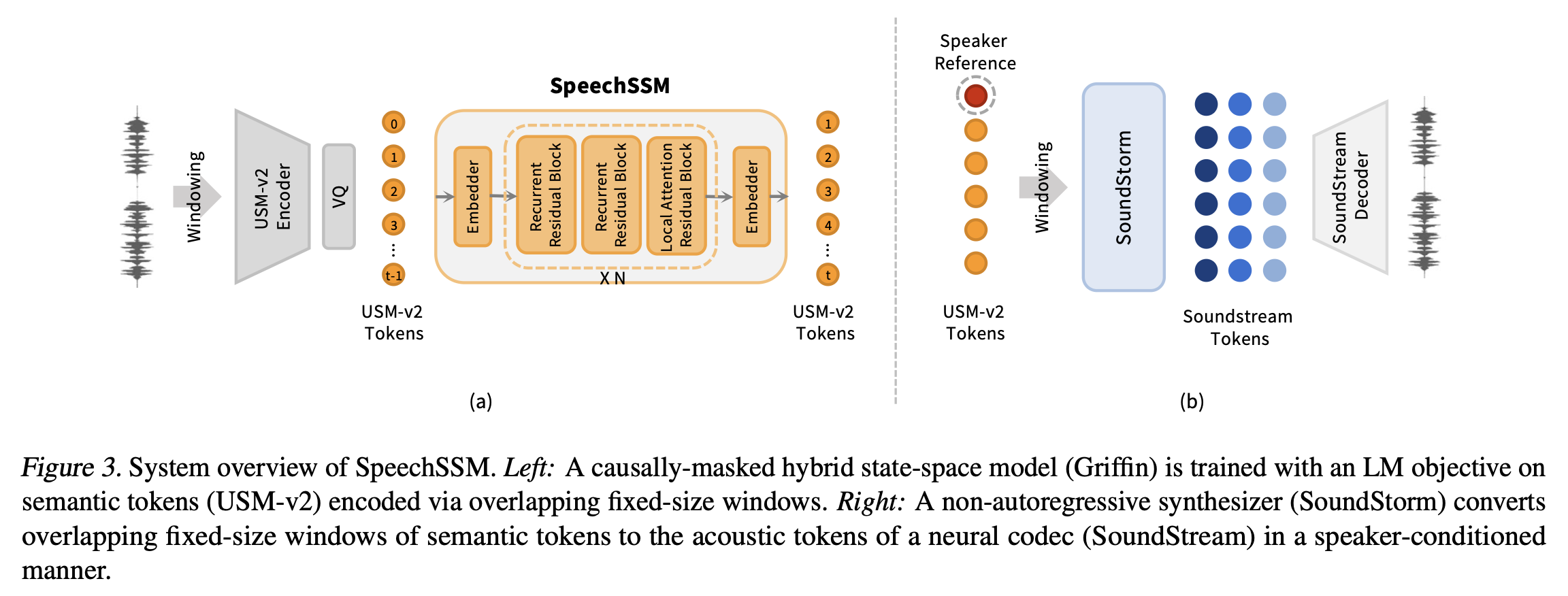
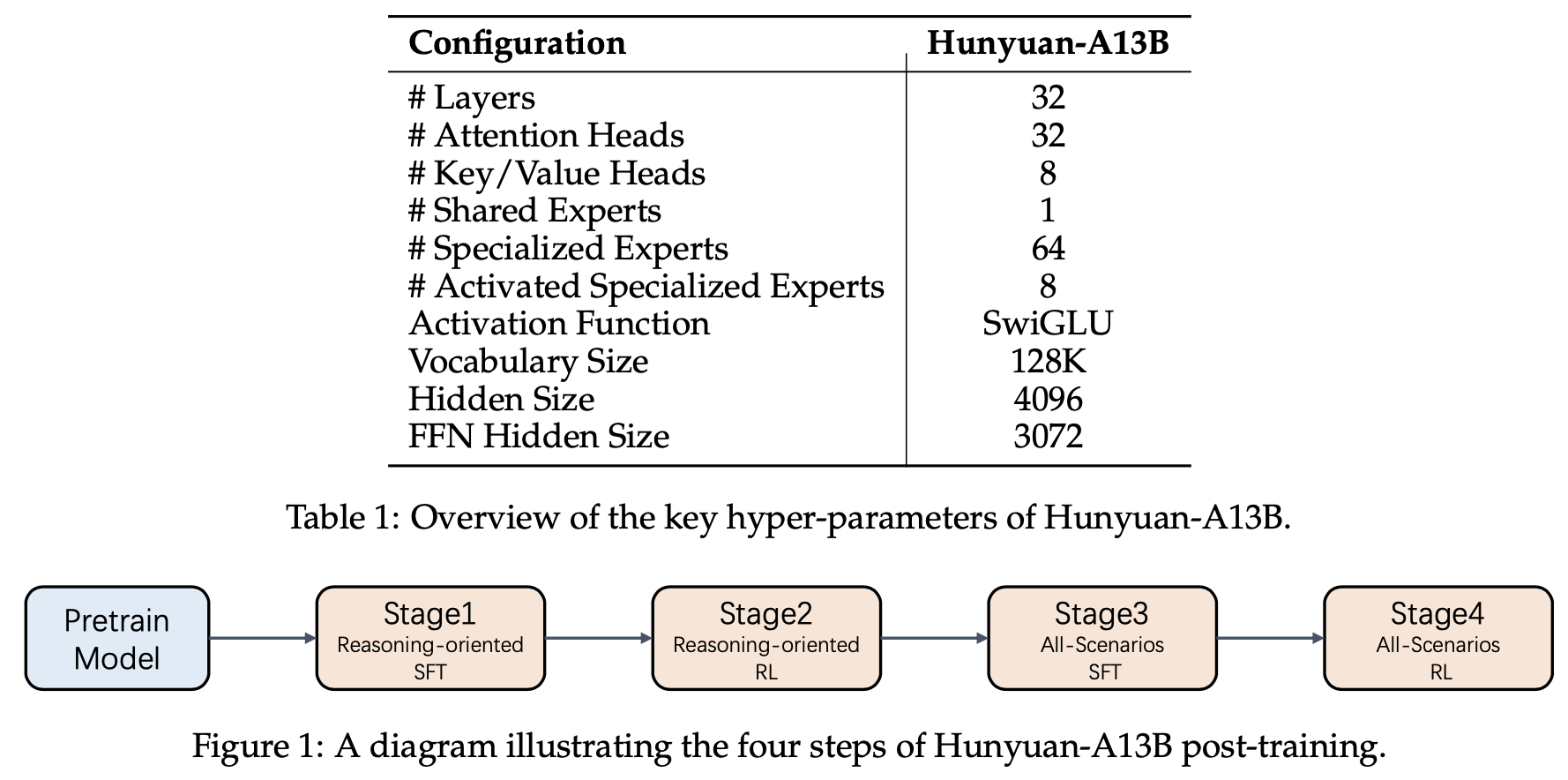
이 논문은 대규모 언어 모델(LLM)의 사전 훈련 과정에서 발생하는 천문학적인 계산 비용(8비트 가중치 하나당 10^13~10^15 FLOPs) 문제를 해결하고자 하는 강력한 동기에서 출발합니다. 기존에는 LLM의 기능을 확장하거나 특정 작업에 적응시키기 위해 경사 기반 미세 조정(gradient-based fine-tuning)이나 RLHF(Reinforcement Learning from Human Feedback)와 같은 방법들이 사용되었는데, 이들은 매우 효과적이지만 엄청난 계산 비용과 방대한 훈련 데이터를 요구합니다. 이 연구는 이러한 비용이 많이 드는 패러다임을 "Assembly-of-Experts" (AoE)라는 새로운 모델 구성 방법을 통해 혁신하고자 합니다. AoE는 부모 모델의 파라미터..