"MLE-STAR: Machine Learning Engineering Agent via Search and Targeted Refinement" 논문은 기계 학습(ML) 모델을 자동으로 구현하는 LLM 기반 머신러닝 엔지니어링(MLE) 에이전트의 새로운 접근 방식을 제안합니다. 이 논문은 기존 MLE 에이전트의 한계를 극복하고, Kaggle 경쟁에서 뛰어난 성능을 달성하여 그 효과를 입증합니다.
1. 서론 및 기존 방법론의 한계
머신러닝의 발전은 다양한 실제 애플리케이션에서 고성능을 가능하게 했지만, 여전히 모델 개발은 데이터 과학자에게 많은 반복적인 실험과 데이터 엔지니어링을 요구하는 노동 집약적인 과정입니다. 최근 연구는 이러한 워크플로우를 간소화하기 위해 LLM(대규모 언어 모델)을 MLE 에이전트로 활용하는 데 집중하고 있습니다. 이러한 에이전트는 LLM의 코딩 및 추론 능력을 활용하여 ML 작업을 코드 최적화 문제로 개념화하고, 제공된 작업 설명 및 데이터셋을 기반으로 실행 가능한 Python 스크립트를 생성합니다.
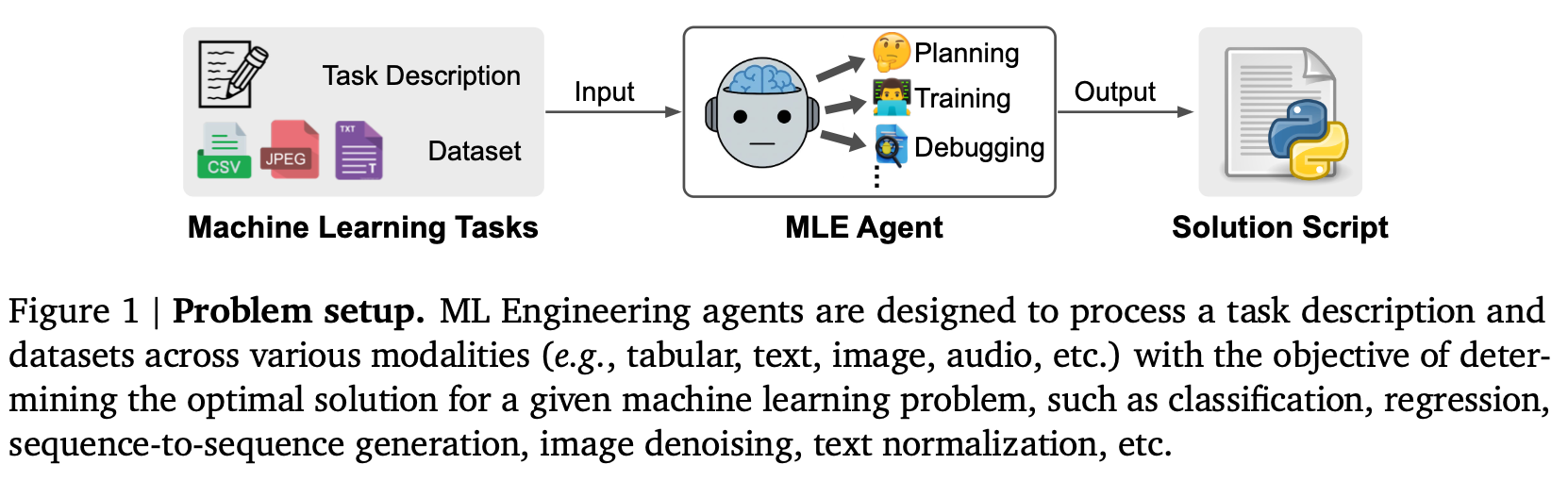
그러나 기존 MLE 에이전트들은 몇 가지 장애물에 직면해 있습니다.
- 내재된 LLM 지식에 대한 높은 의존성: 기존 에이전트들은 LLM 자체의 지식에 크게 의존하여, 종종 친숙하고 자주 사용되는 방법(예: tabular 데이터에 대한 scikit-learn 라이브러리)에 편향되는 경향이 있습니다. 이는 유망한 작업별 방법을 간과하게 만듭니다.
- 투박한 탐색 전략: 이 에이전트들은 일반적으로 각 반복에서 전체 코드 구조를 한 번에 수정하는 탐색 전략을 사용합니다. 이로 인해 특정 파이프라인 구성 요소(예: 다양한 특징 엔지니어링 옵션) 내에서 깊고 반복적인 탐색을 수행하는 능력이 부족하여, 종종 너무 일찍 다른 단계(예: 모델 선택 또는 하이퍼파라미터 튜닝)로 넘어가게 됩니다.
이러한 한계를 극복하기 위해 MLE-STAR가 제안되었습니다.
2. MLE-STAR: 핵심 아이디어 및 방법론
MLE-STAR는 웹 검색을 통해 외부 지식을 활용하여 효과적인 모델을 검색하고 초기 솔루션을 형성한 다음, 특정 ML 구성 요소를 대상으로 하는 다양한 전략을 탐색하여 이를 반복적으로 정제합니다. 이러한 탐색은 개별 코드 블록의 영향을 분석하는 어블레이션 스터디(ablation studies)에 의해 안내됩니다.
MLE-STAR 프레임워크는 크게 세 가지 단계로 구성됩니다:
- 웹 검색을 통한 초기 솔루션 생성.
- 타겟팅된 코드 블록 정제를 통한 솔루션 개선.
- 앙상블 전략 탐색을 통한 추가 개선.
또한, LLM의 바람직하지 않은 행동(예: 테스트 샘플 통계 사용)을 완화하기 위한 추가 모듈도 도입되었습니다.

2.1. 웹 검색을 통한 초기 솔루션 생성
MLE-STAR는 초기 솔루션을 생성하는 것으로 시작합니다. ML 작업에서 고성능을 위해서는 적절한 모델을 선택하는 것이 가장 중요합니다. 그러나 LLM이 모델 제안에만 의존하면 차선책으로 이어질 수 있습니다. 이를 해결하기 위해 MLE-STAR는 웹 검색을 도구로 사용하여 주어진 작업에 대한 M개의 효과적인 최신 모델을 검색합니다 [Algorithm 1].



- 후보 모델 검색 (Aretriever):
Aretriever에이전트는 작업 설명을 입력으로 받아, M개의 모델 설명(Tmodel) 및 해당 예제 코드(Tcode) 쌍을 검색합니다 [Figure 9]. 이 예제 코드는 LLM이 해당 모델에 익숙하지 않을 수 있으므로 실행 가능한 코드를 생성하기 위해 필요합니다. - 후보 모델 평가 (Ainit): 검색된 각 모델에 대해
Ainit에이전트가 ML 작업을 해결하기 위한 Python 스크립트(s_i_init)를 생성하고, 이를 통해 모델의 성능을 평가합니다 [Algorithm 1, Figure 10]. 생성된 스크립트는 홀드아웃 검증 세트에서 평가됩니다. - 초기 솔루션 병합 (Amerger): M개의 검색된 모델 평가 후, 성능 순으로 정렬된 모델들을 반복적으로 병합하여 통합된 초기 솔루션(
s0)을 구축합니다 [Algorithm 1].Amerger에이전트는 간단한 평균 앙상블을 사용하여 여러 모델을 병합하도록 안내됩니다 [Algorithm 1, Figure 11]. 이 과정은 검증 점수가 더 이상 개선되지 않을 때까지 계속됩니다 [Algorithm 1].

2.2. 코드 블록 정제를 통한 솔루션 개선
반복적인 정제 단계는 초기 솔루션 s0에서 시작하여 사전 정의된 수의 외부 루프(T) 단계 동안 진행됩니다 [Algorithm 2]. 각 단계에서 현재 솔루션(st)을 개선하여 st+1을 얻는 것이 목표입니다.




- 타겟팅된 코드 블록 추출 (Aabl, Asummarize, Aextractor):
- 효과적인 개선 전략을 탐색하기 위해 MLE-STAR는 ML 파이프라인 내의 특정 코드 블록을 식별하고 타겟팅합니다.
Aabl에이전트가 현재 솔루션st에 대한 어블레이션 스터디를 수행하도록 설계된 코드를 생성합니다 [Algorithm 2, Figure 12]. 이 스크립트는st의 특정 구성 요소를 수정하거나 비활성화하여 변형을 생성합니다. 이전 어블레이션 스터디의 요약은 다른 파이프라인 부분의 탐색을 장려하기 위해 입력으로 제공됩니다.- 어블레이션 스터디 실행 후,
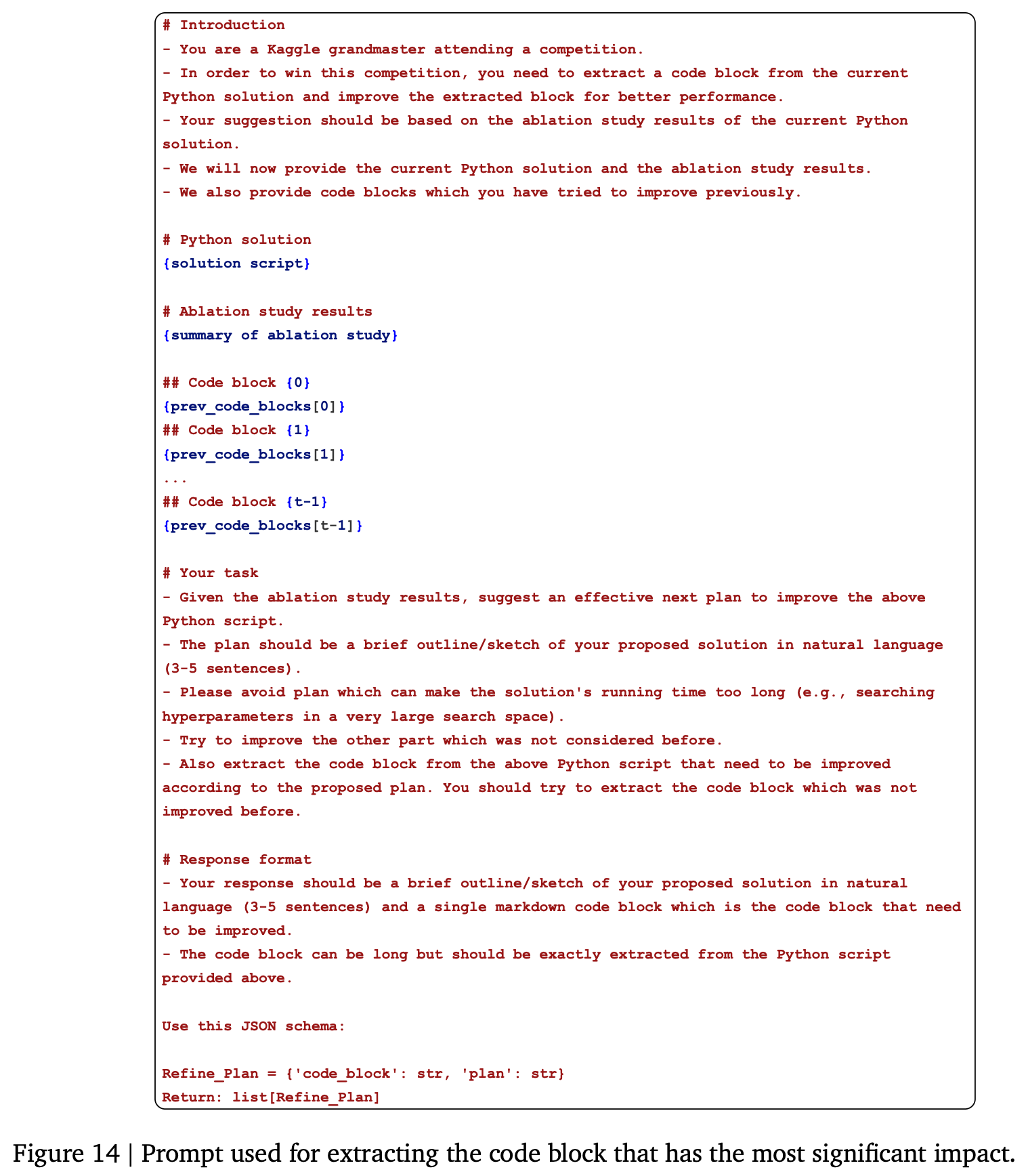
Asummarize모듈은 스크립트와 결과를 처리하여 간결한 어블레이션 요약(T_t_abl)을 생성합니다 [Algorithm 2, Figure 13, Figure 24]. Aextractor모듈은T_t_abl을 분석하여 성능에 가장 큰 영향을 미친st내의 코드 블록(ct)을 식별합니다 [Algorithm 2, Figure 14]. 이 단계에서ct에 대한 초기 정제 계획(p0)도 동시에 생성됩니다.
- 코드 블록 정제 (Acoder, Aplanner) - Inner Loop:
- 타겟팅된 코드 블록
ct가 정의되면, MLE-STAR는 메트릭h를 개선하기 위한 다양한 정제 전략을 탐색합니다. 이는ct에 대한 K개의 잠재적 정제를 탐색하는 내부 루프를 포함합니다 [Algorithm 2]. Acoder에이전트는p0을 구현하여ct를 정제된 블록c0t로 변환하고, 이를st에 대체하여 후보 솔루션s0t를 형성한 후 성능을 평가합니다 [Algorithm 2, Figure 15].Aplanner에이전트는 더 효과적이거나 새로운 정제 전략을 발견하기 위해 반복적으로 다음 계획(pk)을 제안합니다 [Algorithm 2, Figure 16]. 이 에이전트는 현재 외부 단계 내에서 이전 시도를 피드백으로 활용합니다.- K개의 정제 전략을 탐색한 후, 가장 성능이 좋은 후보 솔루션이 식별되고,
st보다 개선이 발견된 경우에만st+1로 업데이트됩니다. 이 반복 과정은T단계까지 계속됩니다.
- 타겟팅된 코드 블록


2.3. 앙상블 전략 탐색을 통한 추가 개선
최고의 단일 솔루션을 더욱 개선하기 위해, MLE-STAR는 새로운 앙상블 절차를 도입합니다 [Figure 3]. MLE-STAR는 여러 후보 솔루션(sl)이 보완적인 강점을 가질 수 있으며, 이를 결합하면 단일 솔루션에 의존하는 것보다 우수한 성능을 얻을 수 있다고 가정합니다. 따라서 MLE-STAR는 앙상블을 위한 효과적인 전략을 자동으로 발견하기 위해 자체 계획 기능을 활용합니다.



- 앙상블 계획 제안 (Aens_planner): L개의 개별 솔루션(
sl)이 주어졌을 때, MLE-STAR는 초기 앙상블 계획(e0, 예: 최종 예측 평균화)을 제안합니다 [Algorithm 3, Figure 17]. 고정된 반복 횟수(R) 동안Aens_planner는 이전 앙상블 계획의 이력과 그 결과 성능을 피드백으로 사용하여 후속 앙상블 계획(er)을 제안합니다 [Algorithm 3]. - 앙상블 계획 구현 (Aensembler): 각
er은Aensembler를 통해s_r_ens로 구현됩니다 [Algorithm 3, Figure 18]. - 최종 앙상블 솔루션 선택:
R개의 앙상블 전략을 탐색한 후, 가장 높은 성능을 달성한 앙상블 결과가 최종 출력으로 선택됩니다 [Algorithm 3].

2.4. 강건한 MLE 에이전트를 위한 추가 모듈
MLE-STAR는 LLM 생성 코드의 잠재적 문제점을 해결하기 위한 여러 추가 모듈을 포함합니다.


- 디버깅 에이전트 (Adebugger): Python 스크립트 실행 중 오류가 발생하면,
Adebugger모듈이 오류를 수정하려고 시도합니다 [Figure 19]. 이 과정은 스크립트가 성공적으로 실행되거나 최대 디버깅 횟수에 도달할 때까지 반복됩니다. - 데이터 누출 검사기 (Aleakage): LLM이 생성한 스크립트는 훈련 데이터셋 준비 중 테스트 데이터셋 정보에 부적절하게 접근하는 등 데이터 누출 위험이 있을 수 있습니다 [Figure 6].
Aleakage에이전트는 실행 전에 솔루션 스크립트를 분석하여 이러한 문제를 감지하고 수정된 버전을 생성합니다 [Figure 20, Figure 21]. 데이터 누출 검사기가 사용되지 않으면 검증 정확도는 개선되지만 테스트 정확도는 크게 떨어질 수 있습니다 [Table 5]. - 데이터 사용량 검사기 (Adata): LLM이 생성한 스크립트가 제공된 데이터 소스 중 일부를 간과하는 경우가 있습니다 (예:
.csv파일만 사용하고.xyz파일 무시) [Figure 7].Adata에이전트는 초기 솔루션과 작업 설명을 확인하여 모든 관련 데이터가 적절하게 사용되는지 확인하고 필요한 경우 스크립트를 수정합니다 [Figure 22]. 이는 성능 향상으로 이어질 수 있습니다 [Table 6].



3. 실험 및 결과
MLE-STAR의 효과를 검증하기 위해 MLE-bench Lite의 22개 Kaggle 경쟁을 사용하여 포괄적인 평가를 수행했습니다. 실험은 세 개의 랜덤 시드와 Gemini-2.0-Flash를 기본 LLM으로 사용했습니다. MLE-STAR는 네 개의 모델 후보를 검색하고, 네 개의 내부 루프와 네 개의 외부 루프를 통해 정제하며, 앙상블을 위해 다섯 라운드를 탐색합니다. 각 방법에는 24시간의 최대 시간 제한이 설정되었습니다.
3.1. 주요 정량적 결과
- MLE-STAR의 우수성: Table 1에 나타난 바와 같이, MLE-STAR는 다양한 기준 모델의 성능을 크게 향상시킵니다. Gemini-2.0-Flash에 적용되었을 때, MLE-STAR는 Kaggle 경쟁에서 AIDE의 메달 획득률을 25.8%에서 43.9%로, 중앙값 상회율을 39.4%에서 63.6%로 향상시킵니다. 특히, MLE-STAR with Gemini-2.0-Flash는 AIDE가 강력한 추론 모델(o1-preview)을 사용하는 것보다 골드 메달 획득에서 10% 더 뛰어난 성능을 보였습니다. Gemini-2.5-Pro를 사용하면 MLE-STAR는 60% 이상의 메달 획득률을 보입니다.
- DS-Agent와의 비교: DS-Agent는 Kaggle에서 사례 은행(case bank)을 수동으로 큐레이션해야 하는 단점이 있습니다. 네 가지 tabular 분류 작업(WBY, MCC, ST, ES)에 대한 비교에서, MLE-STAR는 Gemini-2.0-Flash를 사용하여 인간의 노력 없이도 DS-Agent를 크게 능가했습니다 [Table 2, Table 9].
- 추론 모델의 성능 영향: Gemini-2.5-Pro는 Gemini-2.0-Flash보다 더 나은 성능을 보였습니다 [Table 1]. 이는 MLE-STAR가 빠르게 발전하는 추론 기반 LLM의 발전을 활용하도록 설계되었음을 보여줍니다. 또한, Claude-Sonnet-4를 사용한 추가 실험에서도 유망한 결과가 나타나, MLE-STAR 프레임워크가 다양한 모델 유형에 대해 호환성과 일반화 가능성을 입증했습니다 [Table 3].



3.2. 앙상블 전략에 대한 어블레이션 연구
Table 4에 강조된 바와 같이, MLE-STAR는 앙상블 전략을 추가하지 않아도 경쟁 기준선인 AIDE보다 12% 이상 높은 메달 획득률을 달성하며 상당한 성능 향상을 보입니다 [Table 4]. 주목할 점은 여러 솔루션 후보를 앙상블함으로써 MLE-STAR는 더 큰 성능 향상을 달성한다는 것입니다. 이는 특히 골드 메달 획득 성공률을 지속적으로 개선하고, 이 앙상블 방법이 사용되지 않은 시나리오보다 더 큰 차이로 인간 전문가의 중앙값 성능을 능가합니다.

4. 고찰 및 정성적 관찰
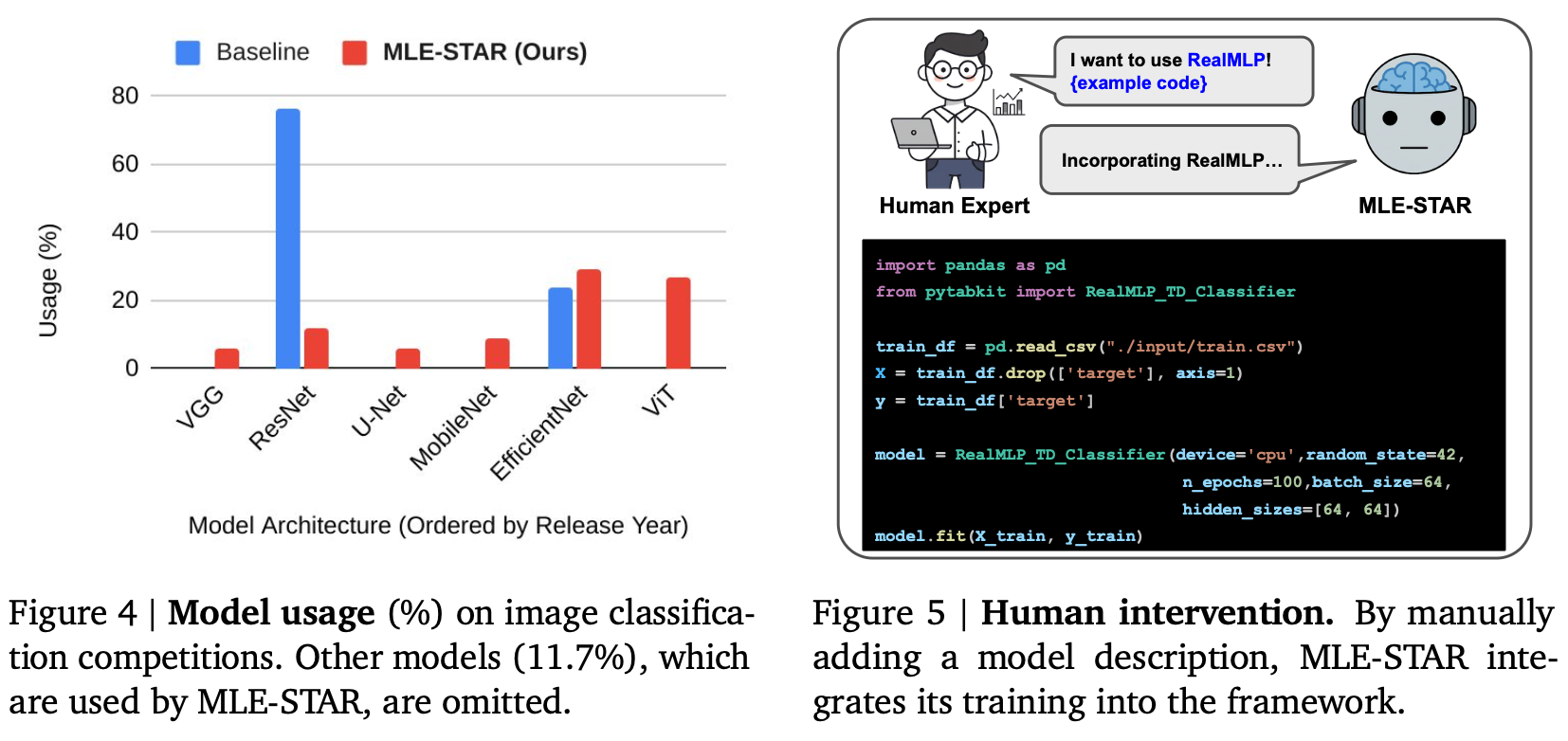
- 모델 사용에 대한 질적 관찰: Figure 4는 AIDE와 MLE-STAR의 이미지 분류 경쟁에서의 모델 사용을 보여줍니다. AIDE는 주로 ResNet(2015년 출시)을 사용했지만, 이는 현재는 구식으로 간주될 수 있습니다. 대조적으로, MLE-STAR는 EfficientNet 또는 ViT와 같은 더 최근의 경쟁력 있는 모델을 주로 활용하여 성능 향상을 이끌었습니다.
- 인간 개입: MLE-STAR는 최소한의 인간 개입으로도 최신 모델을 쉽게 채택할 수 있습니다. 사용자가 RealMLP에 대한 모델 설명을 수동으로 추가함으로써 MLE-STAR는 이전에 검색되지 않은 모델의 훈련을 프레임워크에 성공적으로 통합했습니다 [Figure 5].
- LLM의 오동작 및 교정: LLM이 생성한 코드가 비현실적인 내용을 포함하는 환각(hallucination)을 보이기도 합니다. 예를 들어, 테스트 데이터를 자체 통계로 전처리하는 비실용적인 접근 방식이 Figure 6에 나와 있습니다. MLE-STAR는 데이터 누출 검사기를 사용하여 이러한 문제를 식별하고 코드를 수정하여, 훈련 데이터에서 통계를 추출하고 이를 사용하여 테스트 데이터를 전처리함으로써 문제를 성공적으로 해결했습니다 [Figure 6]. 또한, LLM이 제공된 데이터 소스를 간과하는 경우(예: nomad2018-predicting 경쟁에서
geometry.xyz파일 사용을 무시하는 경우)도 관찰되었습니다 [Figure 7]. MLE-STAR는 데이터 사용량 검사기를 사용하여 모든 주어진 데이터가 활용되도록 수정하여 성능을 크게 향상시켰습니다 [Table 6, Figure 7]. - MLE-STAR 정제를 통한 점진적 개선: Figure 8은 MLE-STAR가 정제 단계를 진행함에 따라 솔루션의 점진적인 개선을 보여줍니다 [Figure 8]. 각 단계는 내부 루프를 통해 단일 코드 블록을 정제하는 데 중점을 둡니다. 초기 정제 단계에서 개선의 규모가 두드러지는데, 이는 MLE-STAR의 어블레이션 스터디 모듈이 가장 영향력 있는 코드 블록을 먼저 타겟팅하는 데 도움이 되기 때문으로 추정됩니다.

5. 결론 및 한계점
MLE-STAR는 다양한 ML 작업을 위해 설계된 새로운 MLE 에이전트입니다. 핵심 아이디어는 검색 엔진을 활용하여 효과적인 모델을 검색하고, 특정 ML 파이프라인 구성 요소를 타겟팅하는 다양한 전략을 탐색하여 솔루션을 개선하는 것입니다. MLE-STAR는 MLE-bench Lite Kaggle 경쟁의 64%에서 메달(36%는 골드 메달)을 획득함으로써 그 효과가 입증되었습니다.
한계점으로는 Kaggle 경쟁이 공개적으로 접근 가능하기 때문에 LLM이 관련 토론으로 훈련되었을 잠재적 위험이 있습니다. 그러나 논문은 MLE-STAR의 솔루션이 Kaggle의 토론과 비교하여 충분히 참신하다는 것을 LLM을 판독기로 사용하여 보여줍니다.
6. 광범위한 영향
MLE-STAR는 복잡한 ML 작업을 자동화함으로써 ML을 활용하고자 하는 개인과 조직의 진입 장벽을 낮추고, 잠재적으로 다양한 부문에서 혁신을 촉진할 수 있습니다. 또한, 최신 모델이 시간이 지남에 따라 업데이트되고 개선됨에 따라, MLE-STAR가 생성하는 솔루션의 성능도 자동으로 향상될 것으로 예상됩니다. 이는 프레임워크가 웹에서 효과적인 모델을 검색하는 검색 엔진을 활용하기 때문에, ML 분야가 발전함에 따라 MLE-STAR가 지속적으로 더 나은 솔루션을 제공하도록 보장합니다.
'Paper Review' 카테고리의 다른 글
| 논문 리뷰: Test-Time 컴퓨팅의 역 스케일링 (Inverse Scaling in Test-Time Compute) (2) | 2025.07.27 |
|---|---|
| "Prediction-Augmented Generation for Automatic Diagnosis Tasks" 논문 리뷰 (2) | 2025.07.26 |
| "Context Rot: How Increasing Input Tokens Impacts LLM Performance" 리뷰 (0) | 2025.07.23 |
| Google Gemini 모델 논문 리뷰 (1) | 2025.07.06 |
| "Thunder-LLM: Efficiently Adapting LLMs to Korean with Minimal Resources" 논문 리뷰 (0) | 2025.07.06 |