이 논문은 이미지, 오디오, 비디오, 텍스트 이해 능력 전반에 걸쳐 뛰어난 성능을 보이는 새로운 다중 모달 모델 제품군인 Gemini를 소개합니다. Gemini는 Google에서 개발되었으며, 각 도메인에서 최첨단 이해 및 추론 성능과 함께 모달리티 전반에 걸쳐 강력한 범용 역량을 구축하는 것을 목표로 이미지, 오디오, 비디오 및 텍스트 데이터를 공동으로 학습했습니다.
1. Gemini 모델 제품군
Gemini 1.0은 세 가지 주요 크기로 제공되며, 각각 다른 계산 제약 조건 및 애플리케이션 요구 사항을 처리하도록 맞춤 제작되었습니다:
- Gemini Ultra: 가장 강력한 모델로, 추론 및 다중 모달 작업 등 광범위한 고도로 복잡한 작업에서 최첨단 성능을 제공합니다.
- Gemini Pro: 성능 최적화된 모델로, 비용 및 지연 시간 측면에서 효율적이며 광범위한 작업에서 상당한 성능을 제공합니다. 강력한 추론 성능과 광범위한 다중 모달 기능을 보여줍니다.
- Gemini Nano: 가장 효율적인 모델로, 온디바이스 배포를 위해 설계되었습니다. Nano-1(1.8B 파라미터)과 Nano-2(3.25B 파라미터) 두 가지 버전으로 학습되었으며, 온디바이스 작업에서 뛰어난 성능을 보입니다.
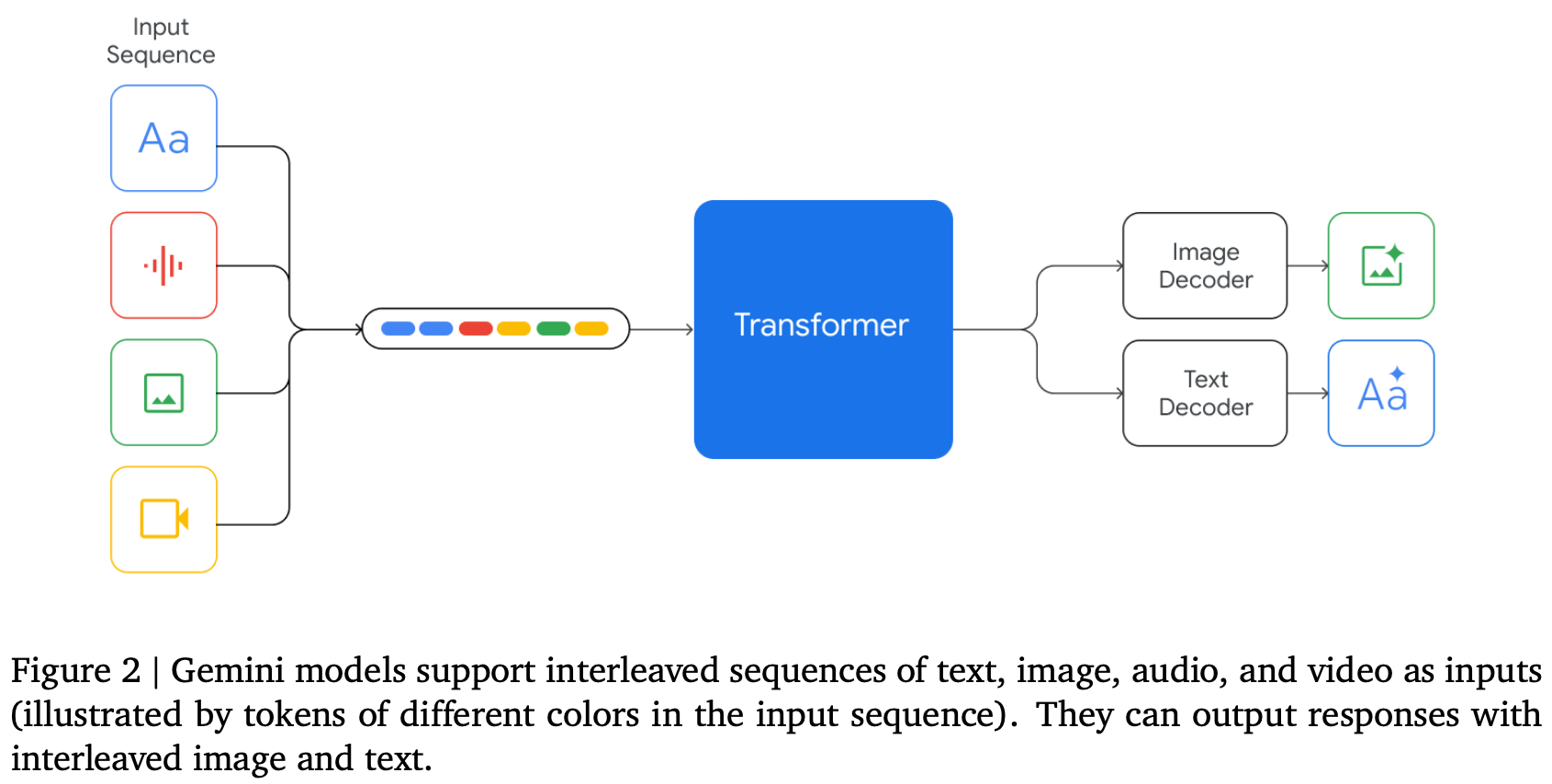
2. 다중 모달리티 및 기능
Gemini 모델은 이미지, 오디오, 비디오 및 텍스트 데이터에서 동시에 공동으로 학습되어 다중 모달리티를 지원합니다. 이는 모델이 텍스트 입력과 다양한 오디오 및 시각적 입력을 (예: 자연 이미지, 차트, 스크린샷, PDF, 비디오) 함께 받아들일 수 있으며, 텍스트 및 이미지 출력을 생성할 수 있음을 의미합니다.
- 교차 모달 추론: Gemini는 오디오, 이미지, 텍스트의 입력 시퀀스를 기본적으로 이해하고 추론할 수 있는 인상적인 교차 모달 추론 기능을 선보입니다. 예를 들어, 학생의 필기 물리 문제 및 풀이를 이해하고, 문제를 수학적 조판으로 변환하며, 학생의 오류를 식별하고, 올바른 풀이를 제공할 수 있습니다. 또한 그림의 함수를 인식하고, 하위 플롯을 생성하는 코드를 추론하며, 사용자 지침을 따르고, 추상적 추론을 수행하여 matplotlib 코드를 생성할 수 있습니다.
- 비디오 이해: 비디오는 큰 컨텍스트 창에서 일련의 프레임으로 인코딩되어 비디오 이해를 달성합니다. 비디오 프레임이나 이미지는 텍스트 또는 오디오와 함께 자연스럽게 모델 입력의 일부로 인터리브될 수 있습니다. 모델은 다양한 입력 해상도를 처리할 수 있습니다.
- 오디오 이해: Gemini 모델은 Universal Speech Model (USM) (Zhang et al., 2023) 기능을 통해 16kHz 오디오 신호를 직접 수집할 수 있어, 오디오가 텍스트 입력으로 단순히 매핑될 때 손실되는 미묘한 차이를 포착할 수 있습니다. Gemini Pro 모델은 ASR 및 AST (자동 음성 인식 및 자동 음성 번역) 작업에서 USM 및 Whisper 모델보다 모든 데이터 세트에서 크게 뛰어난 성능을 보입니다. 특히 희귀 단어와 고유 명사에서 더 잘 이해되는 응답을 생성합니다.
- 이미지 생성: Gemini 모델은 중간 자연어 설명에 의존하지 않고도 기본적으로 이미지를 출력할 수 있습니다. 이는 이미지와 텍스트가 인터리브된 프롬프트로 이미지를 생성할 수 있게 합니다.
- 길이 컨텍스트: Gemini 모델은 32,768 토큰의 시퀀스 길이로 학습되었으며, 컨텍스트 길이를 효과적으로 활용합니다. 이는 문서 검색 및 비디오 이해와 같은 새로운 사용 사례를 가능하게 합니다.
3. 학습 및 인프라
Gemini 모델 제품군을 학습하는 데는 학습 알고리즘, 데이터 세트 및 인프라의 혁신이 필요했습니다.
- 하드웨어: Gemini 모델은 크기와 구성에 따라 TPUv5e와 TPUv4를 사용하여 학습되었습니다. 특히 Gemini Ultra는 여러 데이터 센터에 걸쳐 Google 소유의 대규모 TPUv4 가속기 플릿을 사용했습니다.
- 소프트웨어 및 병렬화: JAX (Bradbury et al., 2018)와 Pathways (Barham et al., 2022)의 '단일 컨트롤러' 프로그래밍 모델은 전체 학습 실행을 단일 Python 프로세스로 오케스트레이션하여 개발 워크플로를 크게 단순화합니다. MegaScale XLA 컴파일러는 학습 단계 계산을 정적으로 스케줄링하여 계산과 최대한으로 중첩되도록 합니다.
- 고가용성: 대규모 학습에서 발생할 수 있는 하드웨어 실패에 대응하기 위해, Gemini 모델은 모델 상태의 중복된 메모리 내 복사본을 활용하여 계획되지 않은 하드웨어 실패 시 손상되지 않은 복제본에서 직접 신속하게 복구할 수 있습니다. 이로 인해 가장 큰 규모의 학습 작업에서 전체 처리량(goodput)이 85%에서 97%로 크게 증가했습니다.
- 데이터 세트: Gemini 모델은 다중 모달 및 다국어 데이터 세트로 학습됩니다. 이 데이터 세트에는 웹 문서, 서적 및 코드의 데이터와 이미지, 오디오 및 비디오 데이터가 포함됩니다. 학습 코퍼스의 큰 샘플에 대해 토크나이저를 학습하면 추론된 어휘와 모델 성능이 향상됩니다. 데이터 품질 필터링 및 안전 필터링이 적용되며, 평가 데이터의 오염을 방지하기 위해 학습 코퍼스에서 평가 데이터를 제거합니다.
4. 성능 평가 및 벤치마크
Gemini 모델은 언어, 코딩, 추론 및 다중 모달 작업에 걸쳐 광범위한 내부 및 외부 벤치마크 스위트에서 평가되었습니다. Gemini Ultra 모델은 평가된 32개 벤치마크 중 30개에서 최첨단 성능을 달성했습니다. 특히 MMLU(Massive Multitask Language Understanding) 시험 벤치마크에서 인간 전문가 성능을 초과한 최초의 모델입니다(90% 이상).
주요 벤치마크 결과는 다음과 같습니다:
- 텍스트 및 추론:
- MMLU: Gemini Ultra는 90.04%의 정확도로 모든 기존 모델을 능가합니다. 이 벤치마크는 57개 주제에 걸친 지식을 측정합니다.
- 수학: Gemini Ultra는 초등학교 수학 벤치마크(GSM8K)에서 94.4% 정확도를 달성했으며, 중고등학교 수학 대회 문제(MATH 벤치마크)에서도 53.2%로 경쟁 모델들을 능가합니다.
- 코딩: Gemini Ultra는 HumanEval에서 74.4%의 문제 해결률을 보이며, 웹 유출이 없는 새로운 Python 코드 생성 벤치마크인 Natural2Code에서는 74.9%로 가장 높은 점수를 기록했습니다.
- 복합 추론 시스템: Gemini 모델의 추론 능력은 검색 및 도구 사용과 결합하여 AlphaCode 2와 같은 강력한 추론 시스템을 구축하는 데 활용되었습니다. Gemini Pro 기반의 AlphaCode 2는 Codeforces 경쟁 프로그래밍 플랫폼에서 참가자의 상위 15% 이내에 랭크되었습니다.
- 다국어:
- 번역: post-trained Gemini API Ultra 모델은 WMT 23 번역 벤치마크에서 모든 언어 쌍에 걸쳐 GPT-4 및 PaLM 2-L을 능가하며, 평균 BLEURT 점수 74.4를 기록했습니다.
- 다국어 수학 및 요약: Gemini Ultra는 다국어 수학 벤치마크 MGSM에서 79.0% 정확도를 달성했으며, XLSum 요약 벤치마크에서 평균 17.6 rougeL 점수를 기록했습니다.
- 이미지 이해: Gemini Ultra는 다양한 이미지 이해 벤치마크에서 최첨단 성능을 보입니다. MMMU 벤치마크에서 62.4%의 새로운 최첨단 점수를 달성하여 이전 최고 모델을 5% 이상 능가했습니다. OCR 관련 이미지 이해 작업에서 외부 OCR 도구 없이도 뛰어난 성능을 보여줍니다.
- 비디오 이해: Gemini Ultra는 비디오 캡셔닝 및 비디오 질의응답 작업에서 최첨단 성능을 달성하여 강력한 시간적 추론 능력을 입증했습니다.
- 사실성 (Factuality): Gemini API 모델의 사실성 평가는 폐쇄형 사실성(hallucination 방지), 속성(주어진 컨텍스트에 대한 충실도), 회피(답변할 수 없는 프롬프트에 대한 인정) 세 가지 측면을 통해 이루어집니다. post-training을 통해 부정확률이 절반으로 줄고, 속성 정확도가 50% 증가하며, 회피 성공률이 0%에서 70%로 증가했습니다.
5. 후처리 학습 (Post-Training) 및 배포
대규모 사전 학습 후, Gemini 모델은 전반적인 품질 개선, 타겟 기능 향상, 정렬 및 안전 기준 충족을 위해 후처리 학습(post-training)을 적용합니다.
- 학습 방법: 후처리 학습은 여러 단계로 이루어집니다:
- 프롬프트 데이터 수집: 실제 사용 사례를 대표하는 다양한 프롬프트 데이터셋을 큐레이션합니다.
- 데모 데이터에 대한 지도 미세 조정(SFT): 모델이 주어진 프롬프트에 대해 원하는 타겟 응답을 출력하도록 학습시킵니다. 이 데이터는 인간 전문가가 직접 작성하거나 모델이 생성한 후 인간이 수정/검토합니다.
- 피드백 데이터에 대한 보상 모델(RM) 학습: 인간 평가자가 후보 응답에 대한 상대적 선호도와 개별 응답에 대한 피드백을 제공하는 피드백 데이터를 수집합니다. 이 데이터는 인간의 선호도에 최대한 부합하는 보상을 출력하도록 RM을 학습하는 데 사용됩니다.
- 인간 피드백으로부터의 강화 학습(RLHF): SFT만 사용하는 것보다 더 큰 성능 향상을 제공합니다. RL이 RM의 경계를 지속적으로 확장하고, RM이 평가 및 데이터 수집을 통해 지속적으로 개선되는 반복적인 프로세스를 만듭니다.
- 모델 변형:
- Gemini Apps 모델: 대화형 AI 서비스인 Gemini 및 Gemini Advanced에 최적화되어 있으며, 현재 Gemini는 Pro 1.0, Gemini Advanced는 Ultra 1.0에 접근을 제공합니다.
- Gemini API 모델: Google AI Studio 및 Cloud Vertex AI를 통해 접근 가능하며, 대화형 및 비대화형 사용 사례를 모두 지원하도록 설계되었습니다.
후처리 학습은 지침 준수(Instruction Following), 도구 사용(Tool Use), 다국어 능력, 다중 모달 비전, 코딩 능력 등 여러 핵심 기능을 향상시킵니다.
- 지침 준수: Gemini Advanced (Ultra 포함)는 복잡한 프롬프트 지침 준수 벤치마크에서 거의 90%에 가까운 instruction-per-accuracy를 달성하여 Gemini (Pro 포함) 및 PaLM 2 모델에 비해 크게 개선되었습니다.
- 도구 사용: Gemini 모델은 도구를 사용하는 방법을 학습하여 내부 지식을 넘어 기능을 크게 확장합니다. 도구 호출이 코드 블록으로 표현되는 코드 생성 문제로 처리됩니다. 도구와 함께 사용되는 모델은 도구가 없는 모델보다 선호되는 것으로 나타났습니다.
- 다국어 능력: 고품질 영어 데이터를 현지 문화에 맞게 현지화하여 다국어 모델을 확장합니다. Gemini (Pro 포함)는 PaLM 2 기반의 이전 Bard 버전에 비해 모든 평가 언어에서 품질이 0.1 SxS(Side-by-Side) 이상 향상되었습니다.
- 다중 모달 비전: 사전 학습된 Gemini 모델을 텍스트 전용 및 이미지-텍스트 데이터 혼합물에 미세 조정하여 이미지 이해 능력을 강화합니다. 이미지-텍스트 데이터 도입은 텍스트 전용 작업에서 Gemini Apps 모델 품질을 유지하면서 다중 모달 작업 성능을 향상시켰습니다.
- 코딩: 후처리 학습 데이터는 기본 모델의 강력한 코딩 벤치마크 성능에도 불구하고 코드 품질과 정확성을 크게 향상시킵니다. Gemini Advanced (Ultra 포함)는 Gemini (Pro 포함)보다 코딩 성능이 더욱 향상되었습니다.
6. 책임감 있는 배포
Google은 Gemini 모델 개발 과정에서 모델의 예측 가능한 사회적 영향을 식별, 측정 및 관리하기 위해 책임감 있는 배포에 대한 체계적인 접근 방식을 따릅니다.
- 영향 평가: Gemini 모델은 정보 요약 등을 통해 사용자가 정보를 더 효율적으로 처리하는 데 도움이 되는 등 다양한 이점을 제공합니다. 동시에 안전하지 않은 콘텐츠(예: 성적으로 노골적인, 폭력적인, 혐오스러운 출력), 아동 안전 피해, 표현 피해와 같은 다양한 콘텐츠 위험과 감시 애플리케이션의 오용 가능성 등을 평가했습니다. 또한 모델 수준 및 제품 수준에서 위험 평가를 수행합니다.
- 안전 정책: Gemini 모델 개발 및 평가를 위한 모델 안전 정책 세트가 개발되었습니다. 이 정책은 아동 성적 학대 및 착취 콘텐츠, 혐오 발언, 괴롭힘, 무기 제조 지침과 같은 위험한 콘텐츠 및 악의적인 콘텐츠 생성 방지를 포함합니다. 또한 모델의 편향을 줄이는 가이드라인도 포함되어 있습니다.
- 완화 조치:
- 데이터 큐레이션: 모든 학습 단계 전에 잠재적 피해를 완화하기 위해 고위험 콘텐츠에 대한 학습 데이터를 필터링하고 고품질 학습 데이터를 보장합니다.
- 모델 완화: 주로 후처리 학습(SFT 및 RLHF)을 통해 안전 위험을 완화합니다. '유해성 유발 쿼리'에 대한 안전 지향 SFT 데이터셋을 생성하여 모델이 안전하고 유용한 응답을 생성하도록 학습시킵니다. 유해성 유발 쿼리에 RLHF를 적용하여 안전별 선호도 데이터를 보상 모델 학습에 포함시킵니다.
- 안전 평가: Gemini 모델의 개발 수명 주기 전반에 걸쳐 안전 정책 및 기타 주요 위험 영역에 대한 평가를 수행합니다.
- 개발 평가: 학습 중 책임 기준 개선을 위한 내부 평가.
- 보증 평가: 주요 이정표 또는 학습 실행 종료 시 모델 개발 팀 외부에서 수행되는 거버넌스 및 검토 목적의 평가.
- 외부 평가: 독립적인 외부 그룹이 모델의 사각지대를 식별하기 위해 수행하는 스트레스 테스트.
- 레드 팀: 전문가 내부 팀이 안전 정책 및 보안과 같은 영역에 걸쳐 수행하는 적대적 테스트.
- 위험한 기능: 공격적인 사이버 보안, 설득 및 기만, 자기 증식, 상황 인식, 화학/생물학/방사능/핵(CBRN) 위험과 같은 잠재적으로 대규모 피해를 초래할 수 있는 기능에 대한 평가도 수행됩니다.
- 표현 편향: Winogender, Winobias, BBQ 데이터 세트를 사용하여 텍스트-텍스트 기능의 편향 및 고정관념을 이해하며, 이미지-텍스트 기능에서는 다양한 인종 및 성별 외모를 가진 사람들의 이미지가 유사한 품질로 설명되는지 테스트합니다.
- 배포: 모델 및 시스템 카드(내부 및 외부)를 지속적으로 발행하며, 이용 약관, 모델 배포 및 접근, 운영 측면(변경 제어, 로깅, 모니터링 및 피드백)에 대한 온라인 콘텐츠도 제공합니다.
7. 결론
Gemini는 텍스트, 코드, 이미지, 오디오 및 비디오에서 다중 모달 모델의 기능을 발전시킨 새로운 모델 제품군입니다. Gemini Ultra는 MMLU 벤치마크에서 인간 전문가 성능을 능가했으며, 대부분의 이미지, 비디오, 오디오 이해 벤치마크에서 최첨단 성능을 달성했습니다.
이러한 새로운 능력은 교육, 일상 문제 해결, 다국어 의사소통, 정보 요약, 추출 및 창의성과 같은 다양한 새로운 애플리케이션을 가능하게 합니다. 그러나 LLM의 사용에는 '환각(hallucinations)' 및 인과 관계 이해, 논리적 추론과 같은 고수준 추론 능력 부족과 같은 지속적인 연구 및 개발이 필요한 제한 사항이 있습니다. Gemini 제품군은 "지능 해결, 과학 발전 및 인류에게 이점"이라는 Google의 사명을 향한 다음 단계이며, 다중 모달에 걸쳐 광범위한 일반화 능력을 갖춘 대규모 모듈화 시스템을 개발하는 미래 목표의 강력한 기반을 제공합니다.