이 논문은 "Thunder-LLM: Efficiently Adapting LLMs to Korean with Minimal Resources"라는 제목의 연구로, 기존의 영어 기반 대규모 언어 모델(LLM)을 적은 자원으로 한국어에 효율적으로 적응시키는 방법을 제시하고 있습니다.
1. 연구의 배경 및 목표
- 문제점:
- 최첨단 LLM은 영어 또는 중국어 외 다른 언어에서 저조한 성능을 보이는 경우가 많습니다. 예를 들어, Meta가 개발한 Llama는 한국어에서 영어보다 훨씬 낮은 성능을 보입니다.
- LLM의 전체 엔드투엔드 훈련 과정은 독점적인 이유, 기술적 복잡성, 일관성 없는 문서, 윤리적 고려사항 등으로 인해 대중에게 거의 알려져 있지 않으며, 이는 업계의 비밀로 유지되고 있습니다.
- 정부, 대학, 스타트업 등은 자체 언어 및 문화적 특성을 반영하는 LLM 개발에 대한 수요가 높지만, 대형 기술 기업이 가진 하드웨어 자원 및 기술 전문성이 부족합니다.
- 한국어 LLM 훈련을 위한 충분한 데이터 및 벤치마크가 부족합니다. 영어는 수조 토큰 이상의 공개 데이터가 풍부하지만, 한국어는 고품질 공개 텍스트가 약 300억 토큰으로 제한적입니다. 또한, 후속 훈련을 위한 공개 한국어 데이터는 거의 없으며, KLUE, KoBEST와 같은 몇몇 벤치마크만 특정 도메인에 초점을 맞추고 있습니다.
- 목표: 저예산 환경에서 기존의 영어 기반 LLM의 한국어 능력을 향상시켜 한국어-영어 이중 언어 LLM을 훈련하는 것입니다. 이를 통해 최소한의 데이터와 컴퓨팅 자원을 활용하여 최첨단 모델에 비해 뛰어난 한국어 성능을 달성하는 것을 목표로 합니다.
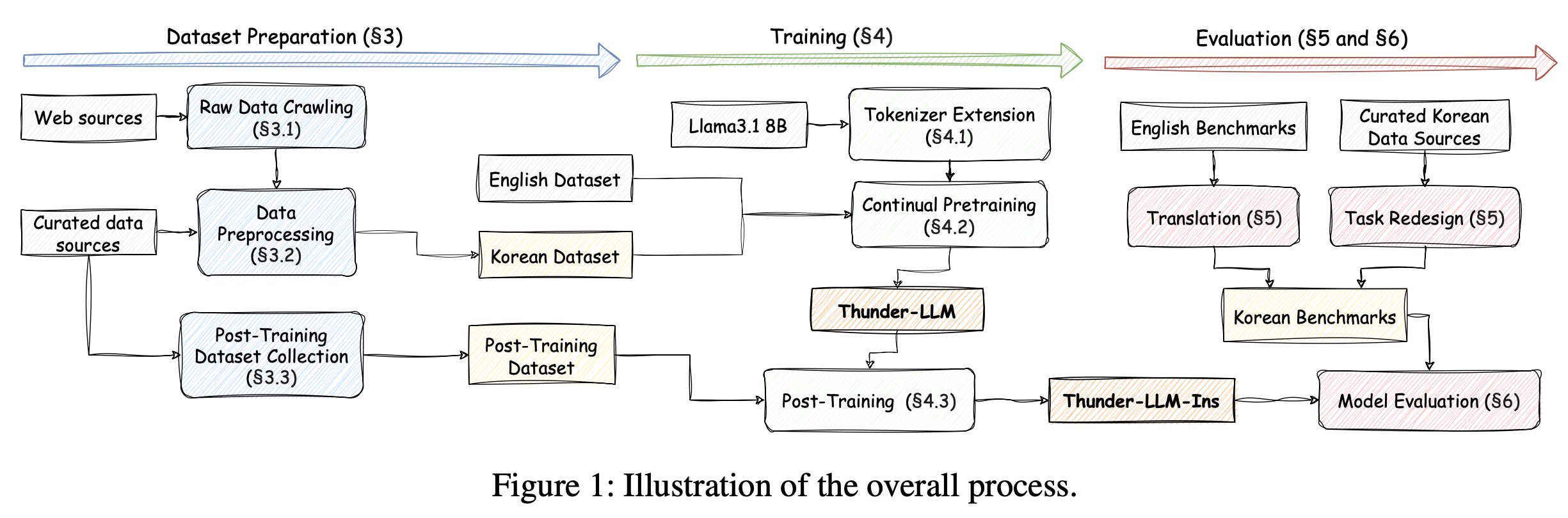
2. 연구 방법론 및 과정
논문은 한국어 데이터 수집, 데이터 전처리, 모델 훈련, 다운스트림 벤치마크 생성 및 평가를 포함한 전체 엔드투엔드 프로세스를 설명합니다. 전체 과정은 그림 1에 요약되어 있습니다.
- 데이터 준비 (Preparing Korean Datasets)
- 영어 데이터: RedPajama v2, DCLM, Dolma와 같은 공개적으로 사용 가능한 전처리된 데이터셋을 활용했습니다.
- 한국어 데이터 수집 (Crawling Korean Texts):
- 공개 한국어 데이터셋의 부족으로 인해 약 3TB의 원본 한국어 텍스트 데이터를 직접 수집했습니다.
- 수집원은 Naver, Daum, Tistory의 블로그, 온라인 커뮤니티(카페), 뉴스 기사였습니다.
- 개인 정보 보호를 위해 접근이 제한된 게시물은 제외하고, 불필요한 데이터를 줄이기 위해 특정 키워드를 포함하는 문서는 필터링했습니다.
- 데이터 전처리 (Preprocessing the Dataset): 수집된 한국어 웹 데이터의 품질을 향상시키기 위해 세 단계의 전처리 파이프라인을 구현했습니다.
- 규칙 기반 전처리 (Rule-based preprocessing): 한국어 원어민에게 자연스럽고 의미 있는 문서만 남기도록 합니다. 예를 들어, 문서당 10~10,000,000 단어 포함, 평균 단어 길이 2~10자, 80% 이상이 한국어 문자, 가장 빈번한 5-그램이 전체 5-그램의 15%를 초과하지 않아야 합니다. 또한, 마침표가 없는 문장은 제거하여 상용구 콘텐츠를 걸러냈습니다. 이 단계에서 원본 데이터의 45%가 필터링되었습니다.
- 중복 제거 (Deduplication): 문서 유사성을 기반으로 중복된 콘텐츠를 제거했습니다. GPU 기반 중복 제거 기술을 사용하여 10.7%의 중복 데이터를 제거했습니다.
- 모델 기반 필터링 (Model-based filtering): 한국어 위키피디아 덤프에 훈련된 5-gram KenLM 언어 모델을 사용하여 높은 퍼플렉시티를 보이는 문서를 필터링하여 언어적 유창성과 자연스러움이 떨어지는 데이터를 걸러냈습니다.
- 후속 훈련을 위한 데이터셋 (Datasets for Post-training): 공개적으로 사용 가능한 한국어 후속 훈련 데이터셋이 부족하여 두 가지 접근 방식을 사용했습니다.
- 벤치마크 훈련 세트 활용: 공개 한국어 및 영어 언어 모델 벤치마크의 훈련 데이터셋을 질문-답변 형식으로 변환하여 Supervised Fine-Tuning (SFT)에 사용했습니다. DPO(Direct Preference Optimization)를 위해 객관식 벤치마크에서 정답을 '선택된 응답', 오답을 '거부된 응답'으로 설정하여 선호도 데이터셋을 생성했습니다.
- 합성 데이터 (Synthetic datasets): 온라인 소스에서 고품질 질문을 수집하고, Llama3.3-70B-Instruct, EXAONE3.5-32B-Instruct, QWen2.5 모델 패밀리(32B, 72B)와 같은 LLM을 사용하여 응답을 생성했습니다. 저품질 응답이나 대상 언어로 작성되지 않은 응답은 필터링하고, 정확한 응답은 SFT 및 DPO 데이터셋에 포함시켰습니다.\

- 훈련 방법 (Training Methods)
- 토크나이저 확장 (Extension of the Tokenizer): Llama 3.1 토크나이저를 새로운 한국어 토큰으로 확장하여 비한국어 작업의 정확도를 유지하면서 추론 비용을 낮췄습니다.
- 분기 엔트로피(branching entropy) 기반의 한국어에 최적화된 전처리 토큰화 전략을 개발하여 72,000개의 한국어 전용 어휘를 만들고 이를 기존 Llama 토크나이저에 추가하여 총 200,000개의 어휘를 구성했습니다.
- 한국어 텍스트를 효과적으로 토큰화하기 위해 Byte-Pair Encoding(BPE)에서 Unigram 토크나이저로 알고리즘을 변경했습니다.
- 지속적 사전 훈련 (Continual Pre-training):
- 기존 LLM의 능력을 향상시키는 비용 효율적인 방법입니다.
- Llama의 한국어 능력을 향상시키기 위해 훈련했습니다.
- 총 102B 토큰을 사용하여 훈련했으며, 영어와 한국어 텍스트를 약 1:1 비율로 유지했습니다. 이는 한국어 성능을 빠르게 향상시키면서 영어 성능에 미치는 부정적인 영향을 최소화하기 위함입니다.
- 후속 훈련 (Post-Training): SFT(Supervised Fine-Tuning) 및 DPO(Direct Preference Optimization) 방법을 사용하여 모델의 다운스트림 작업 성능을 추가로 향상시켰습니다. 다양한 출처에서 후속 훈련 데이터셋을 수집하여 도메인 간 균형 잡힌 학습을 보장했습니다.
- 훈련 플랫폼 (Training Platform):
- PyTorch를 기반으로 하는 자체 프레임워크를 개발하고, DeepSpeed 프레임워크를 활용하여 훈련 과정을 병렬화했습니다.
- FP8 훈련: LLM 훈련 시간의 상당 부분이 행렬 곱셈에 사용되므로, 호환 가능한 레이어에 FP8 정밀도를 적용하여 전체 훈련 시간을 상당히 줄일 수 있습니다.
- 모든 행렬 곱셈에 FP8을 적용하면 훈련 불안정성이 발생할 수 있음을 발견하고, Transformer 블록 내의 선형 레이어와 언어 모델 헤드에서는 FP8을 안전하게 사용할 수 있지만, 어텐션 메커니즘과 관련된 행렬 곱셈에서는 불안정할 수 있음을 확인했습니다.
- 이러한 방식으로 FP8 정밀도를 사용하면 전통적인 BF16 또는 FP16 훈련에 비해 엔드투엔드 훈련 속도를 1.4배 향상시키면서 모델 정확도 손실은 없었습니다.
- 토크나이저 확장 (Extension of the Tokenizer): Llama 3.1 토크나이저를 새로운 한국어 토큰으로 확장하여 비한국어 작업의 정확도를 유지하면서 추론 비용을 낮췄습니다.
3. 다운스트림 벤치마크 및 평가
- 한국어 벤치마크의 부족: 영어 언어 모델과 달리 한국어 언어 모델을 평가하기 위한 잘 확립된 벤치마크 데이터셋이 부족합니다.
- 새로운 한국어 벤치마크 생성: 이러한 부족을 해결하기 위해 총 6개의 새로운 한국어 다운스트림 벤치마크를 생성했습니다.
- 이 중 5개(Ko-ARC-E, Ko-ARC-C, Ko-GSM8K, Ko-WinoGrande, Ko-IFEval)는 기존 영어 벤치마크를 기계 번역(DeepL) 후 전문가의 인간 수정 및 현지화를 거쳐 만들었습니다. 현지화 과정에는 인명, 지명, 측정 단위의 조정 및 한국 문화에 익숙하지 않은 외국 문화 참조 및 개념의 수정이 포함되었습니다.
- Ko-LAMBADA라는 완전히 새로운 한국어 벤치마크도 도입했습니다. 원본 LAMBADA 벤치마크는 문장의 마지막 단어를 예측하는 데 초점을 맞추지만, 한국어는 문장이 주로 동사로 끝나기 때문에 중간에 나오는 명사와 같은 중요한 단어를 예측하는 것으로 과제를 재설계했습니다.
- 모든 생성된 한국어 벤치마크는 추가 독립 검토자에 의해 교차 검증되었습니다.
- 평가 방법: Llama-3.1-8B를 포함한 최첨단 8B 규모 모델들과 Thunder-LLM 및 Thunder-LLM-Ins 모델의 한국어 및 영어 벤치마크 성능을 비교했습니다.
4. 평가 결과
- 사전 훈련된 모델 성능 (Thunder-LLM): 토크나이저 확장과 지속적 사전 훈련을 통해 한국어 벤치마크에서 평균 4%의 성능 향상을 보였습니다. 영어 벤치마크 점수는 기준 모델과 비교하여 최소한의 변화를 보였습니다.
- 후속 훈련된 모델 성능 (Thunder-LLM-Ins): Thunder-LLM에 후속 훈련을 수행한 결과, 한국어 및 영어 모두에서 벤치마크 점수가 크게 향상되었습니다.
- 한국어 성능에서 다른 모델들을 능가했으며, 영어에서는 두 번째로 높은 순위를 기록했습니다. 특히 일반 언어 이해 벤치마크에서 뛰어난 성능을 보였습니다.
- 후속 훈련 데이터셋에 포함된 훈련 세트가 있는 벤치마크와, 훈련 데이터셋이 없는 IFEval 및 Ko-IFEval과 같은 벤치마크 모두에서 성능 향상이 관찰되어, 후속 훈련 데이터셋 수집 및 훈련 방법의 효과가 입증되었습니다.
- 훈련 속도 (Training Speed): FP8 훈련 방법을 활용하여 전통적인 BF16 훈련에 비해 1.43배의 속도 향상을 달성했으며, 모델 정확도 손실은 없었습니다.
- 추론 속도 (Inference Speed): 토크나이저 확장이 추론 속도에 미치는 영향을 평가했습니다.
- 한국어 벤치마크에서는 평가에 필요한 토큰 수가 거의 절반으로 줄어들어 전체 추론 시간이 18% 감소했습니다. 이는 한국어 어휘 구성 방법론을 사용한 LLM 토크나이저 개선이 한국어 추론 속도를 크게 향상시킨다는 것을 의미합니다.
- 영어 벤치마크의 경우 토큰 수는 거의 동일했지만, 어휘 크기 증가로 인한 언어 모델 헤드의 계산 비용 증가로 추론 시간이 7.2% 증가했습니다. 그러나 이 지연은 모델 파라미터가 커질수록 전체 Transformer 아키텍처 대비 언어 모델 헤드의 계산 비용이 상대적으로 작아지기 때문에 덜 중요해집니다.
5. 결론 및 한계점
- 결론: 이 논문은 영어 기반 다국어 모델의 한국어 능력을 향상시키기 위한 비용 효율적인 엔드투엔드 LLM 훈련 프로세스를 제시합니다. Thunder-LLM 및 Thunder-LLM-Ins 모델은 한국어에서 최고의 성능을 보였고, 최첨단 모델과 비교할 만한 영어 성능을 달성했으며, 이는 상당히 적은 데이터와 컴퓨팅 자원을 필요로 했습니다.
- 한계점:
- 이 연구의 목표는 최첨단 LLM을 구축하는 것이 아니라, 기존 영어 기반 LLM의 한국어 능력을 향상시키기 위한 효과적이고 재현 가능한 훈련 방법론을 시연하는 것입니다.
- 지속적 사전 훈련 시 한국어 및 영어 데이터를 모두 사용했지만, 데이터 품질 및 양의 불균형으로 인해 영어 성능이 약간 저하되는 현상이 관찰되었습니다.
- 수집된 데이터셋은 저작권 및 개인 정보 보호 문제로 인해 공유할 수 없습니다.
- 이 방법의 효과는 한국어에 대해서만 검증되었으며, 다른 저자원 언어나 유형학적으로 거리가 먼 언어에 적용 가능성을 평가하기 위한 추가 실험이 필요합니다.
- 계산 제약으로 인해 모든 실험은 최대 80억 개의 파라미터를 가진 모델로 수행되었으며, 더 큰 규모의 LLM 평가는 향후 연구로 남겨두었습니다.
6. 윤리적 고려 사항
- Ko-LAMBADA 벤치마크는 주로 저작권이 만료된 고전 문학 작품과 같은 공개 도메인 텍스트만 사용하여 구축되었습니다.
- 웹 데이터는 크롤링에 대한 기술적 제한을 구현하지 않은 사이트에서만 수집되었습니다. 공개적으로 접근할 수 없는 콘텐츠는 제외되었고, 크롤링 과정이 대상 서버에 과도한 부하를 주지 않도록 보장했습니다.
- 데이터는 연구 목적으로만 수집되며 배포되지 않습니다. 공개된 모델은 연구용으로만 사용되며, 원본 콘텐츠 소유자의 저작권을 존중하고 보호하기 위한 조치를 취합니다.
- 개인 식별 정보(PII) 제거는 수행하지 않았으나, 관련 연구를 진행 중입니다.
7. 코드 및 모델 공개
저자들은 포괄적인 경험을 공유하고 코드를 공개적으로 사용할 수 있도록 할 예정입니다. 연구자들은 이 논문을 저예산 환경에서 기존 언어 모델에 새로운 언어 기능을 개발하기 위한 기반으로 사용할 수 있기를 희망합니다.