paper: https://arxiv.org/abs/1602.07261
Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning
Very deep convolutional networks have been central to the largest advances in image recognition performance in recent years. One example is the Inception architecture that has been shown to achieve very good performance at relatively low computational cost
arxiv.org
논문은 inception-v4, inception-resnet-v1, v2를 소개하며 인셉션만 사용한 모델과 incepetion과 resnet을 모두 사용한 모델의 파라미터 수를 균등하게 맞췄을 때 성능의 차이를 서술한다.
Inception model의 기본 Motivation은 이러하다. 신경망은 깊고 넓을수록 성능이 좋아지지만 깊어질 수록 발생하는 문제점들 때문에 성능이 반드시 좋아지지 않는다. Inception은 이런 문제점들을 극복하며 당시 Image Recognition Task에서 최고의 성능을 달성했다.
Inception에서는 기울기 소실 문제를 방지하기 위해 두 개의 추가적인 Sub-Classifier를 둬 input에 가까운 층까지 기울기가 전달되게 하여 학습이 이뤄지도록 했다. Sub-Classifier와는 별개로 Inception Model을 구성하는 inception Module에 1x1 Convolution을 이용해 파라미터의 수를 급격하게 줄여서 over fitting을 방지하기도 했다. 이러한 두 가지 기법으로 inception은 20층이 넘는 layer를 쌓아 당시 최고의 성능을 달성할 수 있었다. 지금으로 치면 깊은 구조가 아니지만 2014년도 기준으로 10층이 넘는 layer조차 별로 없었다는 걸 생각하면 굉장히 깊은 층이었음을 알 수 있다.

위는 Inception 의 Architecture이다. 22층이며 이는 9개의 같은 Inception Module로 구성되어 있다.


사진은 3차원 28x28 이미지에 5x5 Convolution 연산을 적용하여 4개의 채널을 만드는 과정을 나타낸다. 먼저 output channel 하나를 만드는데 input channel 수만큼의 Convolution Filter가 필요할 것이므로 5x5x3 이고 output channel이 4개 이므로 5x5x3x4 = 300이 된다. 28x28 feature map에 5x5연산을 적용하면 output의 feature map은 24x24 ( (28-(5-1))*(28-(5-1)) ) 의 크기를 가질 것이다. 채널이 합쳐진 output pixel 하나가 의미하는 것은 12개의 convolution filter 한 번의 연산이므로 300x24x24= 172800의 연산량을 갖게 된다.
다음으로 inception에서 사용한 1x1 convolution을 살펴보겠다.

1x1 Convolutin을 통해 파라미터의 수(연산량)의 수를 줄일 수 있는 것은 Bottleneck 구조 덕분이다. 1x1 convolution 연산은 feature map의 크기를 줄이지 않고 연산량도 매우 작다. 이러한 점을 이용해서 적은 연산량으로 input의 차원을 조절한다 위 그림에서는 3채널을 1채널로 줄인 Bottle Neck 구조를 보이고 있다.
연산량은 input kernel에 대한 연산량 1x1x3 =3 이 Covolution 연산이 feature map의 크기만큼 반복되니 3x28x28 = 2352가 된다.

Bottleneck 구조 이후 이전과 같은 4채널의 feature map을 구하기 위해 5x5 convolution 연산을 수행한다. input channel의 수가 이전과 달리 1이라 input 과 kernel에 대한 연산량은 5x5x4 = 100 이고 output pixel의 개수 24x24 만큼 반복되니 연산량은 57600이다. 1x1 Convolution을 이용한 연산까지 합치면 59952가 된다. 이 전에 5x5 convolution 연산을 바로 진행한 연산량인 172800보다 거의 3배 정도 적은 연산량을 갖게 된다. 1x1 convolution 연산을 이용해 연산량을 줄이는 것의 핵심은 Bottle Neck 구조라고 할 수 있다. 연산량을 줄이는 것도 파라미터 수를 줄이는 것도 좋은 역할이지만 1x1 Convoltion 을 연산량을 줄이는 역할만으로 보기에는 아쉬운 부분이 있다.

Model 전체적인 과정에서 연산량을 줄이기 위해 위 사진처럼 3차원 이미지를 1차원으로 줄이기도 하지만 필요한 경우 오히려 차원을 늘리는 역할도 한다. 1x1 Convolution이 단순히 연산량을 줄이기 위해서라기 보다는 조금 더 확장적인 의미로 파악하는 것이 더 좋을 것이다. 위 그림은 추가적인 설명을 위해 가져온 것이다. 1x1 Convolution Filter각각을 Feature Map 각각의 가중치로 보면 이는 Feature map 단위의 Dense Layer라고 볼 수 있다. 가중합 후에 Convolution 역시 activaiton function을 활용할 수 있기 때문에 Dense Layer 처럼 모델의 정교함을 더할 수 있기 때문에 더욱 그렇다.
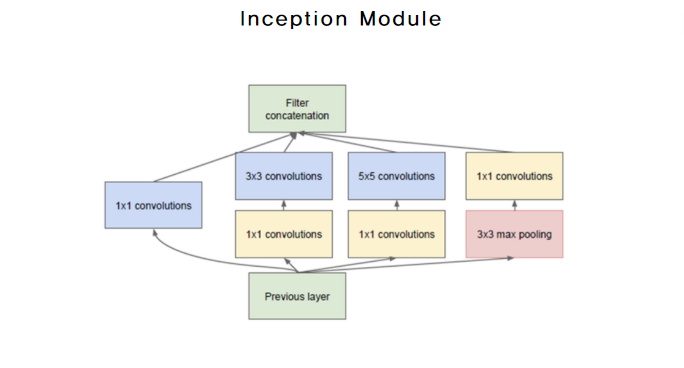
1x1 Convolution의 역할을 본 후 Inception Module을 살펴보면 차원 축소와 Non Linearity를 더했으며 서로다른 Receptive Field에서 얻는 정보를 활용한다는 것을 알 수 있을 것이다.

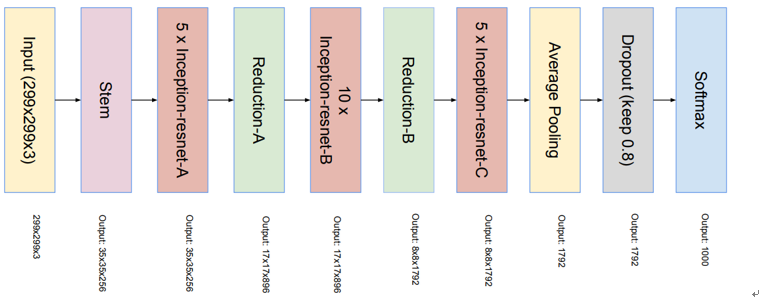
논문에서 소개한 Inception-v4 model을 살펴보겠다. 이전의 inception model은 동일한 inception Module 9개로 이뤄져 있었지만 incepetion-v4는 서로 다른 inception Module A, B, C를 사용했음을 알 수 있다. 또 inception Module A와 B 이후에는 Reduction Module이 등장하는데 여기서는 feature map의 크기를 줄이는 반면 채널의 수는 늘려가는 것을 알 수 있다. 이러한 구조는 inception Module C 이후 8x8 average pooling을 할 때 한 번에 여러 차원의 평균을 pooling하는 것과 관련이 있어 보인다.
나름의 해석을 해보자면 reduction Module을 통해 채널의 수는 늘었지만 feature map의 크기가 줄어들면서 공간적 정보에 손실이 일어났을 것이다. 공간적 정보에 대한 손실을 inception module들을 통해 복구하면서 Reduction Module을 통해 조금씩 차원을 줄여 나가려는 의도일 것이다.
Inception Module C 이후 Average Pooling 자체도 간단하지만 굉장히 효율적인 기법이라는 걸 알 수 있다. 8x8x1536의 feature map 들을 Dense Layer에 넣기 위해서라면 Flatten 이전의 차원 축소가 한 번 더 필요했을 텐데 이 과정에서 파라미터의 수와 연산 과정이 추가될 것이다. 따라서 이 과정을 average pooling으로 대체한 것은 꽤나 효율적인 방법인 것이다. 단순히 평균으로 대체했다는 점에서 정보의 손실이 발생할 거 같지만 여러 시행을 통해 얻은 모델일 것이므로 해당 과정이 성능의 차이에는 유의하지 않을 것이다. 과정은 단순하지만 결과적으로 좋은 아이디어라 볼 수 있다.

Inception-v4에 사용된 모듈들을 간단히 살펴보면 1x1Convolution 외에도 3x3Convolution을 2번 사용한다 든지 7x1, 1x7 Convolution을 나눠서 사용하는 것을 볼 수 있다. 이 역시 큰 receptive filed를 얻는 과정에서 늘어나는 파라미터 수와 연산량을 줄이는 방법 중 하나라고 볼 수 있다.
Inception-resnet-v1과 v2에 대해 살펴보면 inception-v4와 구성이 같지만 inception module이 Inception-resnet-A 등과 같이 바뀌었음을 알 수 있다.
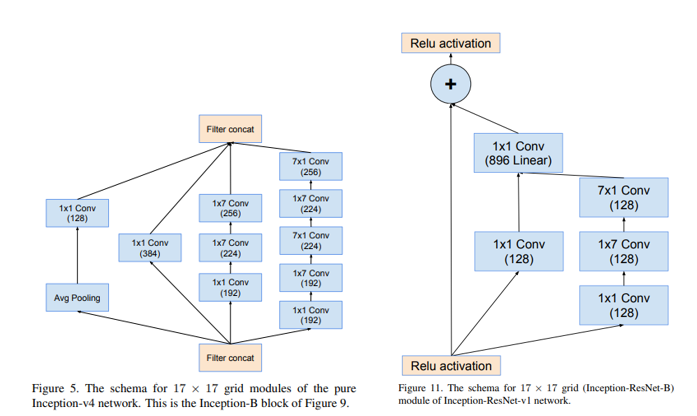
v1과 v2의 차이는 채널의 수 외에는 차이가 없다. 따라서 inception-v4와 inception-resnet-v1의 차이를 분석해 보겠다. 모듈 B나 C에서도 볼 수 있는 차이인데 v4의 avg-Pooling과 1x1Conv가 Residual Connection이 들어오며 없어진 것을 볼 수 있다. 또 inception-v4에서는 상대적으로 더 넓은 recpeptive field를 가져가는 것을 볼 수 있다.
<Incetion-v4> <Inception-ResNet>

논문에 정확하게 나와 있지는 않았지만 inception-resenet이 더 깊은 구조를 가졌기 때문에 각 Block에서 더 적은 receptive field를 가져가더라도 몇 번의 추가적인 layer를 통해 이를 보충할 것으로 생각할 수 있다. Residual connection을 통해 얻게 된 layer를 더 깊게 쌓을 수 있게 된 효과를 사용하면서 inception-v4와 연산량을 비슷하게 유지하는 것으로도 해석할 수 있겠다.

Ensemble을 하지 않고 Single Crop에 대한 Top-5 Error 성능 지표이다. 상대적으로 파라미터 수가 적은 Inception-v3, Inception-resnet-v1들의 최종 성능이 더 좋지 않은 걸 볼 수 있고 resnet을 이용한 모델들의 학습 속도가 더 빠른 것도 확인할 수 있다.

위의 그래프와 같은 결과로 나타낸 것인데 residual connection을 사용한 모델과 사용하지 않은 모델 간 성능에 차이는 없다고 봐도 무방하다. 0.01 정도의 차이라면 시도할 때마다 바뀔 수 있는 정도라고 생각할 수 있지만 여러 번의 시행 끝에 나온 결과라고 밝힌 성능들이다.
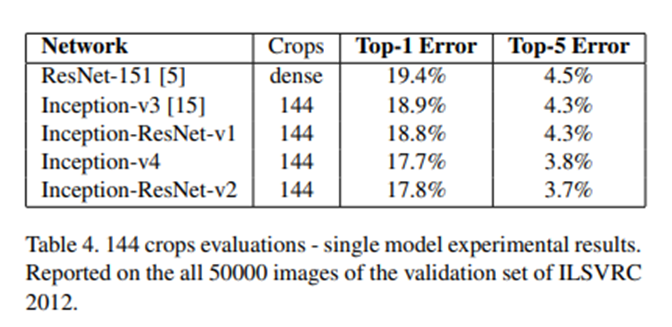
이번에는 한 개의 이미지에 대해 여러 crop들을 사용한 결과 지표이다. (Dense Crop은 1개의 이미지를 여러 개로 겹치게 자르는 것을 의미, 다른 모델들에 비해 이전 시점의 모델인 Resnet의 성능을 더 높이기 위해 한 것으로 추정) Top1 error에서 Inception-v4의 성능이 inception-resnet-v2의 성능보다 더 좋게 나온 것을 볼 수 있다. 이런 결과들을 조합하여 봤을 때 일반적으로 inception에 resenet을 더한 모델들의 학습이 더 빨리 이뤄진다. 성능적인 측면에서도 미세하게 좋긴 하지만 반드시 좋은 것은 아니라는 결론을 낼 수 있다.