1. 연구 배경 및 필요성
3D 의료 영상의 정확한 분할(segmentation)은 종양 부피 산출, 병변 식별 등 임상 활용에 필수적인 핵심 기술이다. 하지만 3차원 영상은 해상도와 데이터 차원이 매우 높아, 전역적(global) 정보 파악이 어려운 한계가 있다. 기존 합성곱 신경망(CNN) 기반 방법들은 국소 패턴에는 강하지만 전체 영상 내 장거리 의존성(long-range dependency)을 효과적으로 포착하지 못한다. 예를 들어, 넓은 수용영역을 갖기 위해 대형 커널을 사용하는 UX-Net 등의 시도가 있었지만, 픽셀 간 거리가 멀어지면 관계 학습에 한계가 있었다. 이를 극복하고자 Transformer 구조가 3D 분할에 도입되어 자기-어텐션(self-attention)을 통해 전역 정보를 추출하기 시작했다. 대표적으로 UNETR는 ViT(Vision Transformer)을 인코더로 활용하여 전역 문맥을 학습하였고, Swin-UNETR는 스윈 트랜스포머 기반 다중 스케일 인코더/디코더로 우수한 성능을 보였다. 그러나 Transformer 기반 모델들은 3D 의료 영상의 높은 해상도로 인한 계산 복잡도와 느린 속도의 문제를 야기한다. 실제로 거대한 self-attention 계층은 메모리 사용이 폭증하여 실용적 한계를 갖는다.
이런 배경에서 상태공간모델(SSM)에 기반한 새로운 대안이 제시되었다. 2023년 Gu 등이 발표한 Mamba는 선택적 상태공간(selective state space)을 통해 선형 시간 복잡도로 장기 의존성을 모델링하는 기법으로, 자연어 처리에서 뛰어난 메모리 효율과 계산 속도를 보였다. Mamba는 하드웨어 친화적 알고리즘 설계를 통해 긴 시퀀스도 효율적으로 처리할 수 있으며, 트랜스포머 대비 경량 구조라는 장점을 지닌다. 이러한 SSM기반 접근은 시계열 데이터뿐 아니라 컴퓨터 비전에도 응용되기 시작했다. 예컨대 U-Mamba는 Mamba 계층을 nnUNet 인코더에 통합하여 분할 성능 향상을 시도했고, Vision Mamba는 양방향 SSM으로 전역 문맥을 포착하는 비전 모델을 제안하였다. 그러나 3D 의료 영상 분할 분야에서는 Mamba의 잠재력이 충분히 탐구되지 않았고, 전통적 트랜스포머 블록의 비효율 문제가 남아 있었다.
이러한 필요성으로 Xing 등(2024)은 SegMamba를 발표하여, 3D 의료 영상 분할에 Mamba를 본격 도입한 최초의 사례를 만들었다. SegMamba는 장거리 의존성 학습 능력과 추론 효율을 겸비하여 기존 CNN 및 트랜스포머 기반 기법들을 능가하는 성능을 보였다. 특히 BraTS2023 뇌종양 데이터셋에서 가장 우수한 Dice 점수(종양 전체 영역 93.61% 등)를 기록하고 자기공명영상에서의 경계 정확도(HD95)도 크게 향상시켰으며, AIIB2023 기관지 데이터에서도 작은 가지까지 연속적으로 탐지하여 최고 IoU와 분지 검출률(DBR)을 달성하였다. CRC-500 대장암 데이터의 경우 종양 범위가 작지만 SegMamba는 해당 부위를 정확히 분할하여 Dice 48.46%로 기존 대비 크게 향상된 정확도를 보였다. 이러한 성과는 SegMamba 기반 접근의 효과성과 잠재력을 입증하지만, 동시에 정확도 향상의 여지가 있음을 의미한다. 실제 의료현장에서 활용하려면 미세 구조나 경계까지 오차 없이 잡아내는 더욱 향상된 분할 성능이 요구된다. 따라서 SegMamba의 장점을 유지하면서도 구조적 개선과 학습 전략 최적화를 통해 3D 의료 영상 분할 정확도를 한 단계 끌어올릴 필요가 있다.
2. 선행연구 분석
다양한 딥러닝 기반 3D 의료 영상 분할 기법들이 제안되어 왔으며, 각기 특장점과 한계를 지닌다. 본 연구에서는 최신 기법들을 검토하고 SegMamba의 위치를 분석하였다:
- nnUNet (Isensee et al., 2021): 자동화된 하이퍼파라미터 튜닝과 U-Net 기반 구조로 다양한 의료 영상 분할 대회에서 기본 모델(baseline)로 활용되는 프레임워크이다. 3D U-Net을 기반으로 하지만 특별한 전역 모듈 없이 풍부한 데이터 증강과 앙상블로 높은 정확도를 달성한다. 다만 구조 자체는 표준 U-Net이라 전역 의존성 학습 면에서 한계가 있다.
- CNN 기반 대형 커널 모델: 국소적 특성에 집중하는 CNN의 한계를 완화하기 위해 커널 크기를 키운 모델들이 등장했다. 3D UX-Net은 깊이별 분리 합성곱(depth-wise conv)과 $7\times7\times7$ 등 대형 커널을 통해 수용영역을 확장한 구조로, BraTS 등에 적용하여 성능 향상을 보였다. 이처럼 CNN을 확장한 모델들은 비교적 경량이지만, 영상 전반의 장거리 관계까지 완전히 포착하기는 어려워 복잡한 구조의 분할에 한계가 있다.
- Transformer 기반 분할 모델: 3D 의료 영상에 Transformer를 접목한 시도들이 최근 두드러진다. TransBTS는 3D CNN으로 지역 특징을 추출한 뒤 Transformer로 전역 정보를 결합하였고, UNETR은 U-Net 인코더를 ViT로 대체하여 멀티스케일 문맥 정보를 학습한 후 디코더와 스킵 연결로 결합했다. 나아가 Swin-UNETR는 Swin Transformer를 통해 다중 해상도 특징을 추출하고 병합하는 구조로 성능과 효율을 개선하였으며, Swin-UNETR V2에서는 구조를 확장·개선하여 BraTS 등에서 최고 수준의 정확도를 보고하였다. Transformer 계열은 전역적 특징 추출에는 유리하지만, 수십만 이상의 3D voxel 시퀀스를 다루면서 메모리 부족(out-of-memory)이나 속도 저하가 발생하는 단점이 있다. 실제로 일반적인 self-attention을 그대로 3D에 적용하면 메모리 한계로 학습이 불가능한 사례도 보고되었다.
- 하이브리드 및 확장 CNN 모델: ConvNeXt와 같은 최신 CNN 구조의 이점을 의료 영상에 특화한 MedNeXt 등이 제안되어, Conv 기반 모델의 스케일을 키우면서 Transformer의 일부 개념(예: 패치 분할, 계층적 구조)을 도입하였다. 이러한 모델은 CNN의 효율성과 Transformer 수준의 표현력을 절충하여, 대규모 의료 데이터셋(예: AMOS 장기 분할 등)에서 경쟁력 있는 성능을 보이고 있다. 다만 완전한 트랜스포머는 아니므로 전역 장거리 상호작용 표현은 여전히 제한적일 수 있다.
- SSM(Mamba) 기반 모델: 앞서 언급한 SegMamba가 이 분야의 대표적인 최신 기법이다. SegMamba는 U-Net과 유사한 인코더-디코더 구조에 TSMamba 블록을 도입하여, 전 층에 걸쳐 전역 시퀀스 정보를 학습하도록 고안되었다. 구체적으로 인코더의 각 해상도 단계마다 Tri-orientated Spatial Mamba (TSMamba) 블록이 쌓여 있으며, 해당 블록은 GSC 모듈과 ToM 모듈로 구성된다. GSC(Gated Spatial Convolution) 모듈은 Mamba로 시퀀셜하게 처리하기 전에 공간적 문맥을 합성곱으로 추출하며, 게이트 메커니즘을 통해 유효한 특징만 통과시켜 잡음과 불확실성을 억제한다. 이어서 ToM(Tri-Orientated Mamba) 모듈은 3D 볼륨을 세 방향(축)에 따라 펼친 세 개의 시퀀스로 변환하여 각각 Mamba 계층으로 처리한 뒤, 이를 통합함으로써 3차원 공간상의 전방위(global) 의존성을 효과적으로 학습한다. 이처럼 GSC로 국소-전역 연결고리를 강화한 뒤, ToM으로 장축(long-axis) 방향의 정보를 캡처하는 구조는 SegMamba의 핵심 혁신이다. 추가로, SegMamba는 디코더의 스킵연결마다 FUE(Feature-level Uncertainty Estimation) 모듈을 두어 멀티스케일 특징 합성 시 불확실성을 감지·완화함으로써 예측 안정성을 높였다. 이러한 설계를 통해 SegMamba는 BraTS2023, CRC-500, AIIB2023 세 가지 서로 다른 형태의 데이터셋에서 모두 기존 최신 기법 대비 뛰어난 정확도를 입증하였다. 특히 장기 의존성이 중요한 복잡한 구조(뇌종양의 다양한 영역, 복잡한 기관지 망 등)에서 SegMamba의 강점이 두드러진다.
요약하면, nnUNet 등의 기존 CNN 기반 모델은 여전히 강력한 베이스라인이지만 전역 정보 처리가 약하며, Transformer 기반 모델들은 전역 정보는 잘 활용하나 고비용 문제가 있다. SegMamba로 대표되는 SSM 기반 접근은 Transformer 수준의 전역 의존성 학습을 훨씬 효율적으로 구현하면서 분할 성능도 향상시키는 새로운 패러다임을 제시하였다. 그러나 SegMamba는 초기 연구인 만큼 모델 구조와 학습법 측면에서 개선 여지가 존재한다. 예를 들어, ToM 모듈 간의 상호작용 최적화, GSC의 고도화, 다중 과제 학습 도입 등을 통해 작은 구조의 검출이나 경계 섬세화 측면에서 정확도를 높일 가능성이 있다. 이러한 선행 연구 분석을 토대로, 본 연구는 SegMamba를 기반으로 구조적 개선과 최신 학습 기법 접목을 통한 정확도 향상을 목표로 한다.
3. 제안 방법
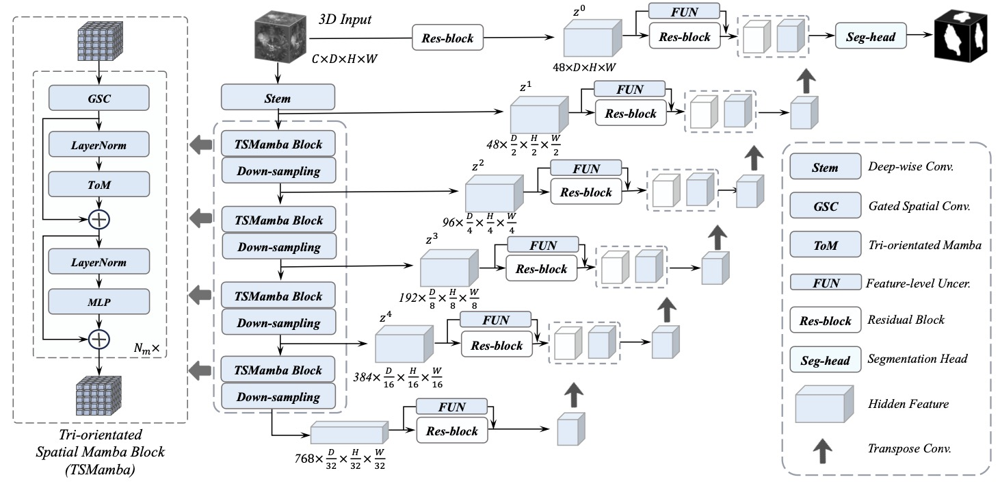
그림 1: SegMamba 기반 제안 모델 구조 개요. 인코더는 3D 입력을 받아 다단계로 다운샘플링하며, 각 단계에서 TSMamba 블록을 통해 전역 정보를 학습한다. TSMamba 블록 내부에는 GSC와 ToM 모듈이 포함되어 국소 및 전역 특징을 통합하고, 출력은 잔차 연결을 통해 다음 계층으로 전달된다. 디코더에서는 업샘플링과 Res-block을 거쳐 점진적으로 해상도를 복원하고, 인코더의 다중 해상도 특징은 FUN(FUE) 모듈을 통해 불확실성을 반영하며 skip-connection으로 결합된다. 최종적으로 segmentation head가 각 voxel의 클래스(종양/정상 등)를 예측한다. 본 연구의 제안 방법은 이 기본 SegMamba 구조를 토대로 여러 개선을 가하여 분할 정확도 향상을 이루고자 한다. 주요 개선 아이디어는 다음과 같다:
(1) GSC 모듈 확장: Gated Spatial Convolution 모듈을 한층 강화하여 더 풍부한 공간 문맥을 추출한다. 구체적으로, 기존 단일 Conv 대신 다중 스케일의 커널을 사용하는 병렬 컨볼루션 또는 변형 가능한 합성곱(deformable conv)을 도입하여 다양한 크기의 구조를 포착하도록 설계한다. 또한 게이트 기능을 향상시키기 위해 채널별 중요도를 학습하는 SE(Squeeze-and-Excitation)나 주의(attention) 메커니즘을 결합할 수 있다. 이를 통해 ToM에 입력되는 피처가 더 의미있는 전역 정보를 포함하도록 하고, 작은 종양 혹은 가는 기관지 가지와 같은 디테일도 초기 단계에서 부터 부각시킨다. GSC 모듈 강화의 효과는 이전 연구의 어블레이션에서 확인된 바 있으며 (GSC 추가 시 Dice 2.88%p 향상), 본 연구에서는 이를 더욱 확장하여 정확도 향상을 도모한다.
(2) ToM 모듈 개선: Tri-Orientated Mamba 모듈은 3개 방향 시퀀스를 독립적으로 처리한 뒤 합치는 구조인데, 본 연구에서는 시퀀스 간 상호작용을 높이는 방향으로 ToM을 개선한다. 첫째, 세 방향으로 처리된 특징들을 단순 합산하는 대신 교차-attention이나 게이트 기반 융합 모듈을 추가하여, 서로 다른 방향의 전역 정보가 결합될 때 보완적인 효과를 내도록 한다. 예를 들어, 축 방향으로 학습된 특징들을 교차로 참고하여 공통되는 종양 영역 신호를 증폭하고 잡음을 억제할 수 있다. 둘째, Mamba 계층을 각 방향당 복수 스택(stack)하여 전역 의존성 학습 깊이를 증가시킨다. SegMamba에서는 효율성을 위해 제한된 수의 Mamba layer를 사용했지만, 약간 추가된 계층으로도 메모리에는 큰 영향 없이 표현력이 향상될 수 있다. 이러한 ToM 모듈의 개선은 특히 BraTS처럼 다양한 방향으로 퍼진 종양을 잡아내는 데 유리하게 작용할 것으로 예상된다.
(3) 하이브리드 구조 도입: SSM의 장점은 유지하되, Transformer의 동적 관계 표현 능력을 보완적으로 활용하는 하이브리드 구조를 탐색한다. 예를 들어, 인코더의 가장 하위 계층(보틀넥)에 라이트급(self-attention) 모듈을 추가로 삽입하여, Mamba로는 포착하기 어려운 비선형 상호작용이나 원거리 voxel 간의 직접적 상관관계를 보강한다. 이때 self-attention은 해상도가 많이 다운된 상태에서만 수행하므로 전체 계산량에 큰 영향을 주지 않는다. 또는 Mamba 출력 특징을 입력으로 하는 작은 Transformer 인코더를 병렬로 두어, 동일 특징에 대해 서로 다른 관점(SSM vs Attention)의 전역 표현을 얻은 후 결합하는 방법도 고려한다. 이러한 하이브리드 설계는 최근 MedNeXt 등이 시도한 Conv-Transformer 절충과 맥락을 같이하며, SSM 기반 SegMamba에 유연한 상호작용 표현을 부여하여 성능을 향상시킬 것으로 기대된다.
(4) 멀티태스크 학습 (Multi-task Learning): 분할 정확도를 높이기 위해 보조 과제를 함께 학습시켜 모델의 표현 학습을 강화한다. 첫째로, 경계 검출 보조망을 추가한다. 분할 맵과 동일한 디코더 구조를 가지되 출력으로 종양/장기 경계에 해당하는 이진 맵을 예측하도록 하여, 모델이 경계 근처의 미세한 특징도 학습하게 만든다. 이 경계 정보는 주 분할 결과와 결합하여 최종 출력을 포스트프로세싱하거나, 디코더 피처 결합 시 Attention 게이트로 활용할 수 있다. 둘째로, 불확실성 추정을 명시적 목적으로 삼는다. SegMamba의 FUE 모듈은 특징 수준에서 불확실성을 다루지만, 이를 확장하여 최종 예측에 대한 픽셀별 불확실성 맵을 출력하게 하고, 예측이 불확실한 영역에 대해 loss에 가중치를 부여함으로써 어려운 부위 학습을 집중시킨다. 또한 BraTS처럼 다중 등급 분할의 경우 각 등급에 대한 보조 분류기(예: 종양 등급 분류)를 두어, 높은 차원의 표현 공간에서 클래스별 구분이 뚜렷해지도록 유도할 수 있다. 이러한 멀티태스크 학습 전략들은 모델의 일반화 능력을 높이고 에지 케이스에서의 성능을 개선하여, 최종적으로 Dice 및 HD95 지표를 향상시키는 데 기여할 것이다.
(5) 앙상블 및 기타 전략: 최고 수준의 정확도를 달성하기 위해 앙상블(ensemble) 기법을 활용한다. 예를 들어, 서로 다른 초기 가중치(seed)로 학습된 두세 개의 SegMamba 개선 모델을 소프트보팅 형태로 평균 결합하면 분할 결과의 안정성이 높아지고 오차가 감소할 수 있다. 또한 기존 nnUNet처럼 5-fold 교차 검증 모델들을 앙상블하여 테스트 시 예측하는 방법도 고려한다. 이 밖에도 학습 전략으로 강화된 데이터 증강(특히 작은 ROI를 증폭하는 augmentation)이나 curriculum learning(초기에는 큰 구조 위주로 학습시키고 점차 작은 구조 어려운 샘플 비중을 늘리는 방식)을 도입하여 모델이 어려운 패턴을 더 잘 익히도록 한다. 이러한 보조적인 전략들은 새로운 모듈이 아니므로 핵심 기여는 아니지만, 종합적인 성능 향상을 위해 실험 단계에서 병행할 것이다.
위의 개선 요소들은 상호 보완적으로 작용하도록 설계된다. 전체적으로 제안 모델(가칭 SegMamba++)은 SegMamba의 기본 U-Net형 인코더·디코더 구성은 유지하면서, 인코더 내 TSMamba 블록의 역량을 강화하고 디코더에는 보조 학습 신호를 주입함으로써 정확도 향상을 꾀한다. 본 연구에서는 각 개선 요소의 단일 및 복합 효과를 면밀히 평가하여 최적의 설계 조합을 도출할 예정이다.
4. 실험 설계 및 평가 방법
데이터셋 및 전처리: SegMamba 논문에서 사용한 BraTS2023, CRC-500, AIIB2023 세 가지 데이터를 동일하게 활용한다. BraTS2023은 다중 등급 뇌종양 분할(MRI 기반, 등급: 전체 종양 WT / 종양 핵심 TC / 활성종양 ET) 챌린지 데이터로, 이미 학습/검증/테스트 세트가 나뉘어 있다. CRC-500은 저자들이 구축한 3D 대장암 CT 데이터셋으로, 500개의 환자 데이터에서 작은 크기의 장내 종양을 어노테이션한 것이다. AIIB2023은 기도(기관지) 분할 챌린지 데이터로, 흉부 CT 스캔에서 세분화된 기관지 나무 구조를 라벨링한 것이다. 각 데이터는 Hounsfield 단위 윈도우 조절(CT의 경우)이나 정규화(MRI의 경우) 등 기본 전처리를 수행하고, SegMamba와 동일한 방법으로 크기 조정 및 패치 추출을 진행한다. 예를 들어, BraTS는 $128^3$ 또는 $192^3$ 크기로 패치 크롭하고, 필요시 패딩을 적용한다. 전처리 및 증강은 가능하면 SegMamba 코드에서 제공된 파이프라인을 활용하여 재현성을 확보한다.
훈련 설정: 모든 모델은 Python PyTorch 및 의료영상 라이브러리인 MONAI 환경에서 구현한다. SegMamba 오픈소스 코드를 기반으로 제안 모델의 추가 모듈을 통합한다. 하드웨어는 NVIDIA 최신 GPU(예: A100) 여러 장을 사용하며, 3D 모델 특성상 분산 병렬 학습(DDP)을 적용한다. 하이퍼파라미터는 SegMamba 논문과 동일하게 시작하되, 일부 조정이 필요하면 검증 세트 성능 기준으로 최적화한다. (예: 학습 초기에는 안정적 수렴을 위해 learning rate warm-up이나 smaller batch size를 적용하고, 새 모듈 도입에 따라 dropout 비율 등을 조절할 수 있다.) 각 데이터셋마다 개별 모델을 학습하여 해당 도메인 특성에 최적화한다. 단, FUE 모듈 등의 불확실성 출력이 추가됨에 따라 손실 함수는 Dice 손실+Cross-Entropy의 조합에 보조 손실항(경계 검출은 BCE 손실 등)을 가중합으로 더해 사용한다. 보조 손실의 가중치는 학습 초기에는 낮게 주고 점차 높여, 주 분할 성능을 해치지 않으면서 보조 과제를 학습하도록 유도한다.
비교 기법: 다음과 같은 최신 3D 분할 모델들과 성능을 비교 평가한다. (i) nnUNet: 동일 데이터셋에 대해 nnUNet 프레임워크로 학습된 결과와 비교하여 기본 U-Net 대비 향상 정도를 확인한다. (ii) UNETR: Transformer 인코더 기반 U-Net과의 비교를 통해, 전역 정보 활용의 효과를 상대 평가한다. (iii) Swin-UNETR-V2: 현재 보고된 Transformer 계열 최고 성능 모델로서, 본 제안 기법과의 정량적 우열을 평가한다. (iv) MedNeXt: ConvNeXt 스타일의 확장 CNN 모델로, SOTA CNN과의 성능 차이를 확인한다. (v) SegResNet 등 기타 CNN 기반 baseline 모델: 데이터셋 제공자가 제시한 baseline이 있을 경우 함께 비교한다. (vi) 기존 SegMamba: 본 연구의 출발점인 기존 SegMamba 모델 자체와 비교하여 구조 개선의 효과를 검증한다. 모든 비교 모델은 공개 구현체를 사용하거나 동일 조건에서 재구현하여 동일한 학습 데이터 및 설정으로 학습시키며, 공정한 비교를 위해 데이터 증강 등도 가능한 한 통일한다.
평가 지표: 분할 성능 평가는 정확도(accuracy) 뿐 아니라 경계 품질을 함께 고려한다. BraTS2023과 CRC-500의 경우 분할 결과와 그라운드트루스 사이의 Dice 유사도 계수(Dice score)와 95% 하우스도르프 거리(HD95)를 주요 지표로 사용한다. Dice는 분할된 종양 부피의 겹침 정도를 나타내며 높을수록 좋고, HD95는 경계에서의 최대 오차 거리(95퍼센타일)로 낮을수록 좋다. BraTS는 종양 등급별(Dice/HD95 for WT, TC, ET) 및 평균 성능을 보고하며, CRC-500은 한 가지 종양 클래스에 대해 Dice/HD95를 계산한다. AIIB2023의 경우 대회 평가지표인 IoU(교집합/합 비율), DLR(Detected Length Ratio), DBR(Detected Branch Ratio)를 사용한다. IoU는 분할된 기도 영역의 정확도를 나타내고, DLR과 DBR은 각각 분할된 기도 나무의 길이 비율과 분기 개수 비율로, 실제 기도 구조 대비 얼마나 완전하게 탐지했는지를 측정한다. 이들 지표 역시 높을수록 우수한 성능을 의미한다. 추가로, 모델의 효율성도 부차적으로 기록한다: 훈련 시 메모리 사용량(Memory), 한 에포크당 시간, 추론 시 FPS 혹은 한 케이스당 소요시간 등을 측정하여, 제안 기법이 실시간성이나 메모리 측면에서도 기존 대비 과도한 비용을 요구하지 않음을 보일 것이다. 다만 주안점은 정확도 향상이므로, 효율성 지표는 참고 수준으로 제시한다.
실험 시나리오: 각 데이터셋별로 (a) 단일 모델 성능과 (b) 앙상블 성능을 모두 평가한다. (a)에서는 제안 모델 한 개를 학습하여 검증/테스트 세트 결과를 비교하고, (b)에서는 앞서 언급한 3~5개의 모델 앙상블 결과를 측정한다. 이를 통해 개별 모델의 향상뿐 아니라 앙상블을 통한 최고 성능 한계도 탐색한다. 추가로, 제안하는 각 구성요소의 효과를 분석하기 위한 모듈별 Ablation 실험을 수행한다. 예를 들어 GSC 확장 없이 나머지만 적용한 경우, ToM 개선 없이 적용한 경우, 멀티태스크를 제외한 경우 등 다양한 모델 변형을 실험하여 Dice/HD95 변화량을 비교한다. 이러한 절차로 어떤 모듈이 성능에 가장 크게 기여하는지 확인하고, 통계적 유의성 검정(예: t-test)을 통해 향상된 성능이 우연이 아닌 유의한 개선임을 증명한다. 결과는 표와 그래프로 정리하여 제안 모델이 모든 비교 대상보다 우수한 성능임을 한눈에 보여줄 계획이다. 예시로 BraTS2023의 WT/TC/ET 각 등급에 대한 Dice를 비교하면, 제안 모델은 SegMamba 대비 각 등급에서 수 %p 향상되고 UNETR 등의 기존 모델 대비도 유의하게 높을 것으로 기대된다 (예: WT Dice SegMamba 93.6% → SegMamba++ 95% 내외 목표). 기관지 데이터의 경우 특히 잔가지 검출(DBR) 향상에 주목하며, 대장암 데이터는 낮은 HD95로 경계까지 정확히 검출하는지 평가할 것이다.
5. 기대 효과 및 활용 가능성
본 연구를 통해 SegMamba 기반 3D 분할 모델의 성능 한계를 크게 향상시킬 것으로 기대한다. 제안하는 개선 모델은 기존 SegMamba 대비 Dice 정확도와 HD95 경계 정확도를 유의미하게 개선하여, BraTS 뇌종양 분할의 경우 현재 최고 성능을 경신하고 작은 대장암 병변이나 복잡한 기관지 구조에서도 높은 재현율을 보일 것이다. 특히 경계 검출 향상과 불확실성 예측으로 미세 구조 분할 능력이 증가함에 따라, 임상적으로 중요한 작은 종양의 검출률이나 수술 계획에 필요한 세밀한 기관지 분지 파악 능력이 높아진다. 이는 의료 영상 분석의 정확도 향상을 통해 오진 감소와 치료 계획 최적화에 기여할 수 있다.
SegMamba++ 모델은 세 가지 이질적인 3D 데이터셋(BraTS, CRC, AIIB)에서 검증되므로, 일반화된 분할 기법으로서 가치가 있다. 추가적인 튜닝을 통해 간, 폐 등 다른 장기 분할 문제에도 적용 가능할 것이며, 다양한 3D 의료 영상 도메인에 두루 활용될 수 있다. 또한 본 연구에서 도입한 구조적 개선 기법들(예: SSM-Transformer 하이브리드, 멀티태스크 경계 학습, 불확실성 모듈 등)은 향후 다른 분할 네트워크에도 응용되어 범용적인 성능 개선 전략으로 활용될 수 있다. 예를 들어, 향후 연구자들은 우리의 ToM 개선 방안을 참조하여 다른 장기 분할에서 전역 의존성 학습을 강화하거나, GSC 확장 아이디어를 이용해 CNN 기반 모델의 전역 감지 능력을 높일 수 있다.
더 나아가, 실시간 처리 및 임상 통합 측면에서도 의의가 있다. SegMamba는 이미 효율성이 입증된 바 있으며, 제안 모델 역시 적절한 자원에서 실시간 또는 준실시간 3D 분할이 가능하도록 설계되었다. 이는 방대한 3D 데이터를 다루는 임상 환경(수술 중 MRI, 응급 CT 등)에서 신속하면서도 정확한 자동 분할을 제공하여 의료진의 의사결정을 지원할 수 있음을 의미한다. 또한 본 연구를 통해 생성되는 CRC-500 데이터 개선된 결과는 대장암 분할 연구 커뮤니티에 제공되어 관련 알고리즘 개발을 촉진할 수 있다.
요약하면, 본 연구의 성과로 최첨단 3D 의료 영상 분할 기술이 한층 발전되고, SegMamba 기반 방법론의 우수성이 입증됨과 동시에 그 한계를 보완하는 구체적 방안들이 제시될 것이다. 이는 학술적으로는 SSM과 딥러닝 융합 기법의 가능성을 넓히고, 실용적으로는 정확하고 신뢰도 높은 의료 영상 분석 도구 개발로 이어져 환자 진단과 치료에 직접적인 이익을 가져올 것으로 기대한다.
'Projects' 카테고리의 다른 글
| GeoTransMol: 분자 특성 예측을 위한 새로운 딥러닝 모델 개발 연구 계획서 (0) | 2025.05.03 |
|---|---|
| CycleNet 후속 연구 계획서 (0) | 2025.05.03 |
| Language-Based Audio Retrieval (DCASE 2025 Task 6) 연구 계획 (0) | 2025.05.03 |
| DCASE 2025 Task 2: 고성능 이상음 탐지를 위한 모델 아키텍처 및 기법 (0) | 2025.05.03 |
| VOTS 2025 챌린지 연구 계획 (1) | 2025.05.01 |