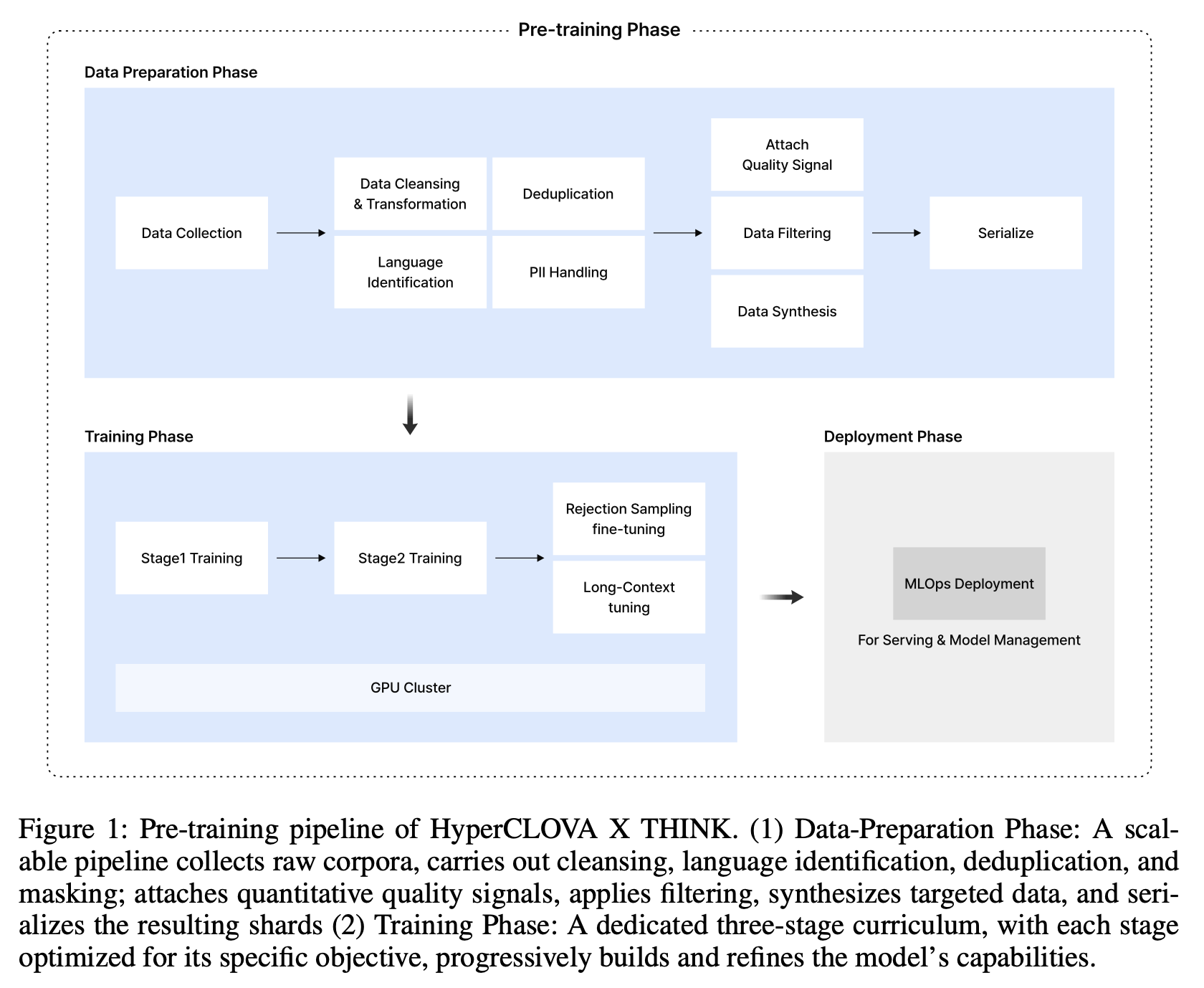
HyperCLOVA X THINK 개요 및 목표HyperCLOVA X THINK는 HyperCLOVA X 제품군의 첫 번째 추론 중심 대규모 언어 모델입니다. 이 모델은 두 가지 주요 목표를 가지고 개발되었습니다:고급 추론 능력: 사실적 지식 암기를 넘어 논리적 추론 및 다단계 문제 해결 능력을 제공합니다.주권 AI(Sovereign AI) 촉진: 한국어에 특화된 언어적 유창성과 문화적 민감도를 제공하며, 지역적 가치 및 규제에 부합하는 데이터 거버넌스를 목표로 합니다. 특히 한국을 중심 목표로 설정했습니다.이 모델은 약 6조 개의 고품질 한국어 및 영어 토큰으로 사전 학습되었으며, 표적 합성 한국어 데이터로 보강되었습니다. 또한 컴퓨팅-메모리 균형을 이루는 Peri-LN Transformer 아키텍처를..